1. Abstract
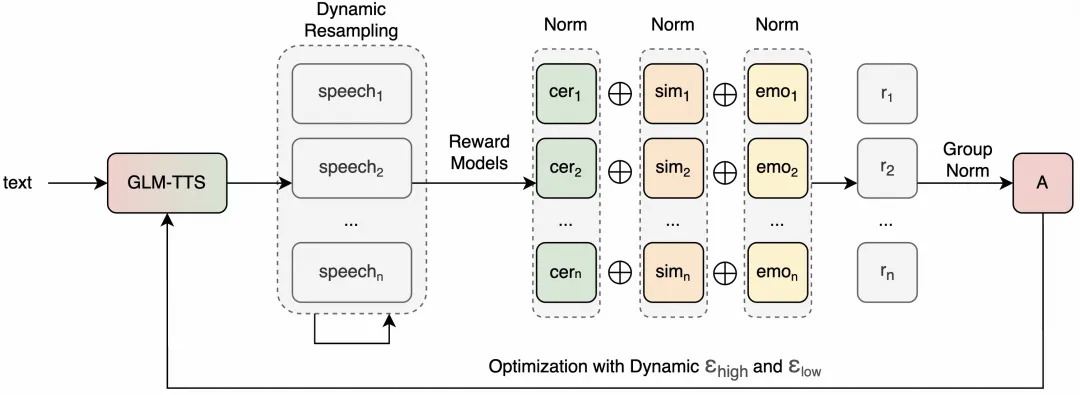
GLM-TTS est un système TTS open source pour la génération de voix de qualité industrielle, prenant en charge le clonage timbre des échantillons vocaux en seulement 3 secondes et offrant une expression émotionnelle contrôlable. Son architecture adopte un processus de génération en deux étapes et introduit un mécanisme d’apprentissage par renforcement basé sur GRPO, qui atteint le niveau de référence de l’open source en termes de taux d’erreur de caractère (CER) et de sentiment. Le projet met l’accent sur de faibles coûts de formation et une grande scalabilité, et convient à des scénarios tels que l’éducation, les livres électroniques, le contenu audio et un service client intelligent.
2. Caractéristiques principales
1. Clonage rapide du timbre : Apprenez le timbre individuel et le style de parole basés sur une parole aussi courte que 3 secondes.
2. Architecture de génération à deux étapes : durée de séparation, rythme et module vocodeur pour améliorer la stabilité et la contrôlabilité.
3. Expression émotionnelle contrôlable : soutient une variété d’émotions telles que le bonheur, la tristesse, la colère, etc., et convient aux longues lectures de texte et aux scènes de caractérisation.
4. L’apprentissage par renforcement de la GRPO améliore l’expressivité : Réduit la CER, améliore la similarité du timbre et améliore la performance émotionnelle grâce à des récompenses multidimensionnelles.
5. Faible coût d’entraînement et d’inférence : 100 000 heures d’entraînement des données, et la pré-entraînement peut être complétée en 4 jours sur une seule machine ; La formation Tone LoRA et RL peut également être réalisée en 1 jour sur une seule machine.
6. Exemples multi-plateformes open source et d’inférence : Fournir des ressources complètes telles que GitHub, Hugging Face et ModelScope pour faciliter la mise en œuvre en entreprise.
3. Installation
- Cloner le dépôt :
git clone https://github.com/zai-org/GLM-TTS
- Installer les dépendances :
Configurer les frameworks Python et deep learning selon les fichiers d’environnement ou les scripts d’exemple fournis par le dépôt.
- Télécharger les poids des modèles :
Vous pouvez obtenir les poids du modèle de base, du timbre premium et de la version RL sur ModelScope ou Hugging Face.
- Déploiement d’inférence :
exécuter des scripts d’inférence d’exemple dans un environnement GPU, prenant en charge la synthèse vocale, la reproduction de timbre et le contrôle paramétrique.
4. Cas d’usage typiques
1. Scénarios éducatifs : Générer une prononciation standard pour les manuels, les banques de questions et les tâches d’évaluation, et s’adapter aux mots multisyllabiques, symboles de formules et mots rares.
2. Livres électroniques et contenus audio : Soutenir la lecture longue, et différents personnages peuvent être reliés avec différents timbres et styles émotionnels.
3. Service client intelligent : Générez des tonalités de service client sur et professionnelles, qui peuvent naturellement insérer des informations variables dans le script et maintenir un rythme constant.
4. Reproduction du timbre et création de contenu : Clonez rapidement le timbre de l’auteur, du présentateur ou du narrateur pour des podcasts, des commentaires audio et de la production de courtes vidéos.
5. Écologie et concurrents
1. Écosystème : Fournir des poids, des scripts d’inférence, de la documentation API et des portails d’expériences en ligne pour faciliter le déploiement local ou dans le cloud des développeurs.
2. Comparaison des concurrents : Comparé aux modèles TTS open source (tels que VITS, CosyVoice, FishSpeech, etc.), GLM-TTS présente des avantages en CER, expression émotionnelle et formation à faible coût ; Cependant, l’effet spécifique dépend du type de texte métier, des conditions acoustiques et de la configuration d’inférence.
6. Limitations et précautions
- Le contrôle des émotions dépend de la qualité des données d’entraînement, et certaines émotions complexes ou mixtes restent instables.
- Dans les longues interactions de texte et de voix en temps réel, la cohérence prosodique peut être limitée par la rapidité de raisonnement et la stratégie contextuelle.
- Le clonage vocal doit respecter les exigences d’autorisation des données et ne doit pas être utilisé pour la reproduction sonore non autorisée.
- Il peut y avoir de légères différences de poids entre différentes plateformes, et la version du modèle correspondante doit être sélectionnée en fonction du scénario applicatif.
7. Adresse du projet
https://github.com/zai-org/GLM-TTS
8. FAQ
Q : Quelle quantité de voix est nécessaire pour le clonage vocal GLM-TTS ?
R : Prise en charge des échantillons de 3 secondes pour compléter la réplication du timbre, mais des échantillons plus longs peuvent améliorer la stabilité.
Q : Est-ce qu’il prend en charge le contrôle des émotions ?
R : Soutenir les tags de sentiment comme Heureux, Triste, En colère, etc., et montrer la voie dans les avis publics.
Q : Quel est le coût de l’inférence ?
R : L’inférence peut être réalisée dans un environnement GPU autonome, adapté à la synthèse par lots de bibliothèques de contenu à grande échelle.
Q : Le modèle est-il adapté à un déploiement commercial ?
R : Il est open source sous la licence Apache et peut être librement utilisé pour la recherche et des scénarios commerciaux, sous réserve des spécifications de licence solides.
Q : Existe-t-il une API en ligne ?
R : Oui. Des interfaces de synthèse vocale et de reproduction timbre sont disponibles via la plateforme ouverte.