一、摘要
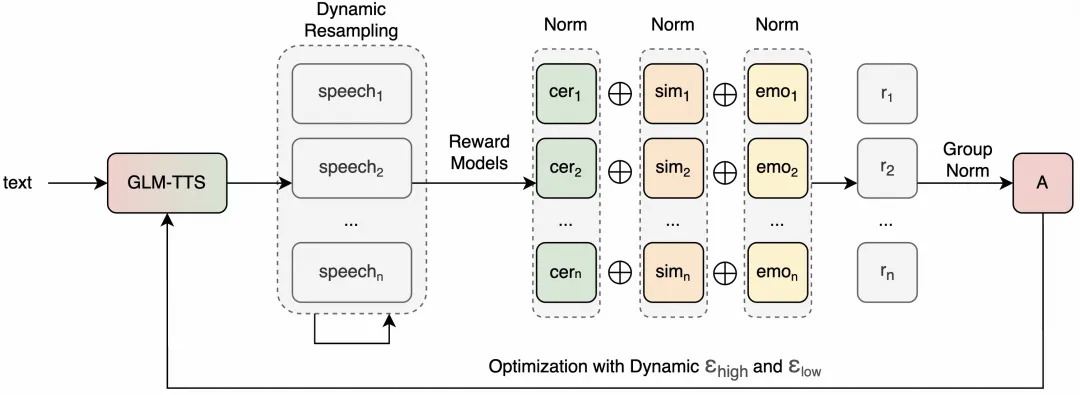
GLM-TTS 是面向工业级语音生成的开源 TTS 系统,支持仅 3 秒语音样本的音色克隆,并提供可控的情绪表达能力。其架构采用两阶段生成流程,并引入基于 GRPO 的强化学习机制,在字符错误率(CER)与情感维度达到开源领先水平。项目强调低训练成本与高可扩展性,适用于教育、电子书、有声内容和智能客服等场景。
二、核心特性
1、快速音色克隆:根据短至 3 秒的语音学习个体音色与说话风格。
2、两阶段生成架构:分离时长、韵律与声码器模块,提高稳定性与可控性。
3、情绪可控表达:支持愉快、悲伤、愤怒等多种情绪,适配长文本朗读与角色化场景。
4、GRPO 强化学习提升表达力:通过多维度奖励减少 CER、提高音色相似度并增强情绪表现。
5、低训练与推理成本:10 万小时数据训练,单机 4 天可完成预训练;音色 LoRA 与 RL 训练亦可在单机 1 天完成。
6、多平台开源与推理示例:提供 GitHub、Hugging Face、ModelScope 完整资源,便于企业落地。
三、安装
1、克隆仓库:
git clone https://github.com/zai-org/GLM-TTS
2、安装依赖:
按照仓库提供的环境文件或示例脚本配置 Python 及深度学习框架。
3、下载模型权重:
可从 ModelScope 或 Hugging Face 获取基础模型、精品音色与 RL 版本权重。
4、推理部署:
在 GPU 环境下运行示例推理脚本,支持文本转语音、音色复刻与参数化控制。
四、典型用例
1、教育场景:为教材、题库和评测任务生成标准发音,适配多音字、公式符号与生僻词。
2、电子书与有声内容:支持长篇朗读,不同角色可绑定不同音色与情绪风格。
3、智能客服:生成克制、专业的客服音色,可在脚本中自然插入变量信息并保持韵律一致。
4、音色复刻与内容创作:快速克隆作者、主播或讲解者的音色,用于播客、有声解说与短视频生产。
五、生态与竞品
1、生态:提供权重、推理脚本、API 文档与在线体验入口,方便开发者在本地或云端部署。
2、竞品对比:与开源 TTS 模型(如 VITS、CosyVoice、FishSpeech 等)相比,GLM-TTS 在 CER、情感表达和低成本训练方面具有优势;但具体效果依赖业务文本类型、声学条件与推理配置。
六、局限与注意事项
1、情绪控制依赖训练数据质量,某些复杂情绪或混合情绪表现仍存在不稳定性。
2、在长文本与实时语音交互中,韵律一致性可能受限于推理速度和上下文策略。
3、音色克隆需遵守数据授权要求,不得用于未经许可的声音复制。
4、不同平台权重可能存在细微差异,需依据应用场景选择相应模型版本。
七、项目地址
https://github.com/zai-org/GLM-TTS
八、常见问题
Q: GLM-TTS 的音色克隆最低需要多少语音?
A: 支持 3 秒样本完成音色复刻,但更长样本可提高稳定性。
Q: 是否支持情绪控制?
A: 支持 Happy、Sad、Angry 等情绪标签,并在公开评测中取得领先表现。
Q: 推理成本如何?
A: 单机 GPU 环境即可完成推理,适合大规模内容库的批量合成。
Q: 模型是否适合商业部署?
A: 在 Apache License 下开源,可自由用于研究与商业场景,但需遵循声音授权规范。
Q: 是否提供在线 API?
A: 支持。可通过开放平台获得文本转语音与音色复刻接口。