1. Abstract
GLM-TTS ist ein Open-Source-TTS-System für die industrielle Sprachgenerierung, das das Klonen von Klangproben in nur 3 Sekunden unterstützt und einen kontrollierbaren emotionalen Ausdruck ermöglicht. Seine Architektur verwendet einen zweistufigen Generierungsprozess und führt einen GRPO-basierten Reinforcement-Learning-Mechanismus ein, der das führende Open-Source-Niveau in den Bereichen Zeichenfehlerrate (CER) und Sentiment erreicht. Das Projekt legt Wert auf niedrige Schulungskosten und hohe Skalierbarkeit und eignet sich für Szenarien wie Bildung, E-Books, Audioinhalte und intelligenten Kundenservice.
2. Kernmerkmale
1. Schnelles Klonen des Klangfarbes: Lernen Sie individuellen Klangfarbe und Sprechstil basierend auf Sprache in nur 3 Sekunden.
2. Zweistufige Generationsarchitektur: Trenndauer, Rhythmus und Vocoder-Modul zur Verbesserung von Stabilität und Steuerbarkeit.
3. Kontrollierbarer emotionaler Ausdruck: unterstützt eine Vielzahl von Emotionen wie Glück, Traurigkeit, Wut usw. und eignet sich für lange Textlesungen und Charakterisierungsszenen.
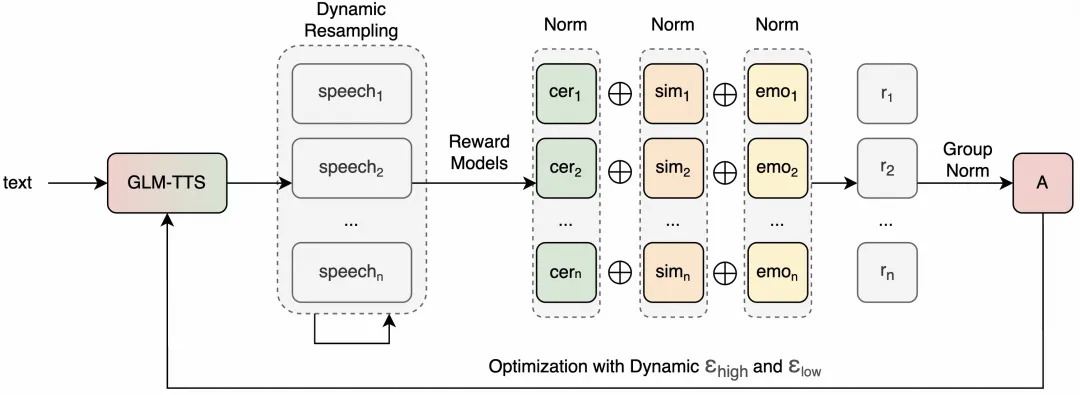
4. GRPO Reinforcement Learning verbessert die Ausdruckskraft: Reduziert CER, verbessert die Klangfarbeähnlichkeit und steigert die emotionale Leistung durch multidimensionale Belohnungen.
5. Geringe Schulungs- und Schlusskosten: 100.000 Stunden Datentraining, und das Vortraining kann in 4 Tagen auf einer einzigen Maschine abgeschlossen werden; Tone LoRA und RL-Training können ebenfalls an einem Tag auf einer einzigen Maschine abgeschlossen werden.
6. Plattformübergreifende Open-Source- und Inferenzbeispiele: Vollständige Ressourcen wie GitHub, Hugging Face und ModelScope bereitstellen, um die Unternehmensimplementierung zu erleichtern.
3. Installation
- Klonen des Repositorys:
git clone https://github.com/zai-org/GLM-TTS
- Installationsabhängigkeiten:
Konfigurieren Sie Python- und Deep-Learning-Frameworks entsprechend den vom Repository bereitgestellten Umgebungsdateien oder Beispielskripten.
- Modellgewichte herunterladen:
Sie können die Gewichte des Basismodells, des Premium-Timbres und der RL-Version über ModelScope oder Hugging Face erhalten.
- Inferenzbereitstellung:
Führen Sie Beispiel-Inferenzskripte in einer GPU-Umgebung aus, die Text-zu-Sprache, Klangfarbewiedergabe und parametrische Steuerung unterstützen.
4. Typische Anwendungsfälle
1. Bildungsszenarien: Erstelle standardisierte Aussprache für Lehrbücher, Fragebänke und Bewertungsaufgaben und passe dich an mehrsilbige Wörter, Formelsymbole und seltene Wörter an.
2. E-Books und Hörinhalte: Unterstützen Sie Langform-Lektüre, und verschiedene Charaktere können mit unterschiedlichen Klangfarben und emotionalen Stilen gebunden werden.
3. Intelligenter Kundenservice: Erzeugen Sie zurückhaltende und professionelle Kundenservice-Töne, die variable Informationen auf natürliche Weise in das Skript einfügen und einen konstanten Rhythmus aufrechterhalten.
4. Klangfarbewiedergabe und Inhaltserstellung: Klonen Sie schnell das Timbre des Autors, Moderators oder Erzählers für Podcasts, Audiokommentare und Kurzvideoproduktionen.
5. Ökologie und Wettbewerber
1. Ökosystem: Bereitstellung von Gewichtungen, Inferenzskripten, API-Dokumentation und Online-Erfahrungsportalen, um Entwicklern die lokale oder cloudbasierte Bereitstellung zu erleichtern.
2. Vergleich der Konkurrenten: Im Vergleich zu Open-Source-TTS-Modellen (wie VITS, CosyVoice, FishSpeech usw.) hat GLM-TTS Vorteile bei CER, emotionaler Ausdrucksform und kostengünstigem Training; Der spezifische Effekt hängt jedoch vom Geschäftstexttyp, den akustischen Bedingungen und der Inferenzkonfiguration ab.
6. Einschränkungen und Vorsichtsmaßnahmen
- Die Emotionskontrolle hängt von der Qualität der Trainingsdaten ab, und einige komplexe oder gemischte Emotionen sind weiterhin instabil.
- Bei langen Text- und Echtzeit-Sprachinteraktionen kann die prosodische Konsistenz durch die Geschwindigkeit des Denkens und die kontextuelle Strategie begrenzt sein.
- Sprachklonen muss den Anforderungen zur Datenautorisierung entsprechen und darf nicht für unautorisierte Tonwiedergabe verwendet werden.
- Es kann leichte Unterschiede in den Gewichten verschiedener Plattformen geben, und die entsprechende Modellversion muss entsprechend dem Anwendungsszenario ausgewählt werden.
7. Projektadresse
https://github.com/zai-org/GLM-TTS
8. FAQs
F: Wie viel Stimme wird für das Klonen von GLM-TTS benötigt?
A: Unterstützung für 3-Sekunden-Samples zur Abschluss der Timbre-Replikation, aber längere Samples können die Stabilität verbessern.
F: Unterstützt es die Emotionskontrolle?
A: Unterstütze Sentiment-Tags wie Glücklich, Traurig, Wütend usw. und führe öffentliche Rezensionen an.
F: Was kostet die Schlussfolgerung?
A: Inferenz kann in einer eigenständigen GPU-Umgebung abgeschlossen werden, die sich für die Batch-Synthese groß angelegter Inhaltsbibliotheken eignet.
F: Ist das Modell für den kommerziellen Einsatz geeignet?
A: Es ist Open Source unter der Apache-Lizenz und kann frei für Forschungs- und kommerzielle Szenarien verwendet werden, vorbehaltlich der Sound-Lizenzspezifikationen.
F: Gibt es eine Online-API?
A: Ja. Text-zu-Sprache- und Klangfarbewiedergabe-Schnittstellen sind über die offene Plattform verfügbar.