I. Zusammenfassung
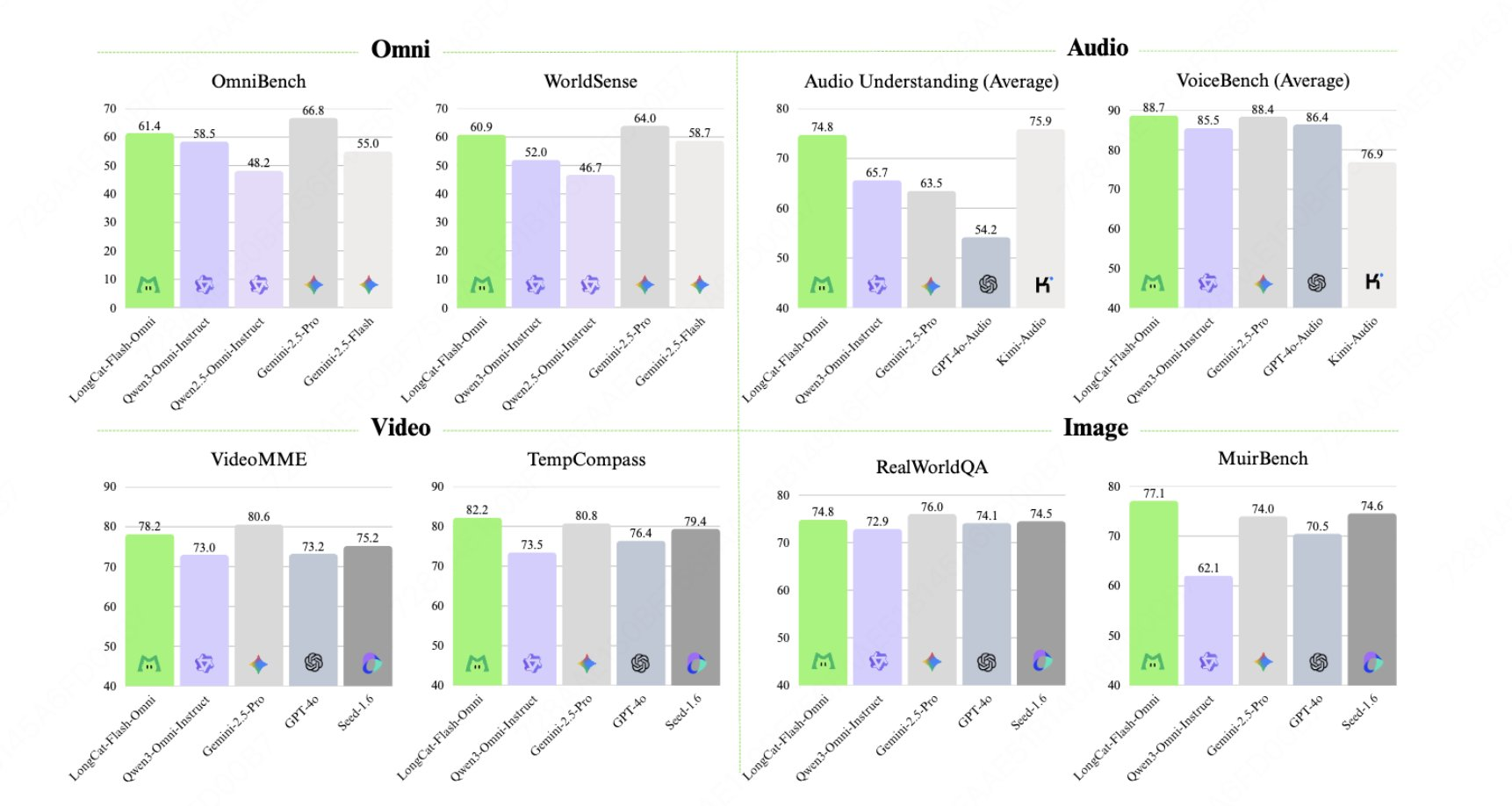
LongCat-Flash-Omni ist ein Open-Source-Multimodalmodell (Omni-modal) des LongCat-Teams von Meituan. Es erweitert die ScMoE-Architektur von LongCat-Flash durch eine einheitliche Modellierung von Text, Bildern, Audio und Video. Mit ca. 560 Byte an Parametern und 27 Byte an Aktivierungen ist es primär für durchgängige Sprachdialoge im Millisekundenbereich, Kontextinformationen von 128.000 Byte sowie Echtzeit-Audio- und Videointeraktionsszenarien von über 8 Minuten geeignet. Zu den wichtigsten Merkmalen gehören ein frühzeitiges Training der multimodalen Fusion, eine entkoppelte modale Parallelinfrastruktur und der zugehörige LongCat-Audio-Codec für hochwertige Sprachausgabe.
II. Kernmerkmale
- Vollmodale Ein-/Ausgabe: Die Eingabe kann eine beliebige Kombination aus Text, Bild, Audio oder Video sein, die Ausgabe erfolgt als Text oder Sprache und passt sich so an Echtzeit-Agenten an.
- Sprachverarbeitung mit geringer Latenz: Die Latenz beim gesamten Sprachverständnis und der Sprachsynthese wird im Millisekundenbereich kontrolliert, was für „unterbrochene“ Dialoge geeignet ist.
- Langer Kontext: Native 128K, die lange Meetings, Mehrkanal-Sprach- und Videokonferenzen unterstützt.
- ScMoE-Architektur: 560 Milliarden Gesamtparameter + 27 Milliarden Aktivierungen, wobei der Rechenaufwand sich der Effizienz des reinen Texttrainings annähert.
- Einheitliches Trainingsparadigma: Multimodales Training sollte in den frühen Phasen integriert werden, um den Verlust von Punkten in einer einzelnen Modalität zu vermeiden und Hören, Sehen und Sprechen zu berücksichtigen.
III. Installation
1. Klonen Sie das GitHub-Repository: git clone https://github.com/meituan-longcat/LongCat-Flash-Omni und wechseln Sie in das Verzeichnis.
- Installieren Sie die Abhängigkeiten gemäß den Anweisungen im Repository. Sie können zwischen vLLM, SGLang oder einem selbstentwickelten Inferenzdienst wählen. Eine GPU ist erforderlich; empfohlen wird ein Videospeicher von mindestens 40 GB. Mehrere GPUs können parallel verwendet werden.
3. Die entsprechenden Gewichtungen und Beispiele aus Hugging Face abrufen: https://huggingface.co/meituan-longcat/LongCat-Flash-Omni; Falls eine Sprachausgabe erforderlich ist, gleichzeitig LongCat-Audio-Codec installieren.
- Nach der Bereitstellung sollten Text-/Sprachtests über REST/WebSocket oder das offizielle LongCat.AI-Frontend durchgeführt werden.
IV. Typische Anwendungsfälle
- Echtzeit-Sprachassistent: ausgehende Anrufe, Kundenservice und Interaktionen mit Begleitern, die eine geringe Latenz und ein Gedächtnis für mehrere Gesprächsrunden erfordern.
- AV-Szenenverständnis: Wichtige Punkte aus Audio- und Videoeingaben für Meetings/Live-Übertragungen/Kurse extrahieren und Fragen beantworten.
- Text- und Audioerklärung: Screenshots/Fotos/Dokumente eingeben, um Audioerklärungen oder mehrsprachige Zusammenfassungen zu generieren.
- Agentenprojekt-Einstiegspunkt: Übergibt die Ergebnisse der Video-/Spracherkennung an die Toolchain oder den Geschäftsprozess zur weiteren Ausführung.
V. Ökologie und Wettbewerber
- Ökosystem: Ergänzend zu LongCat-Flash-Chat, LongCat-Flash-Thinking und LongCat-Audio-Codec, ermöglicht es einheitliche Versionen und Trainingsparadigmen innerhalb derselben Organisation.
- Wettbewerber: Die Fähigkeiten der Qwen-Serie Omni, der multimodalen Sprachversionen von InternLM/GLM und der MiniCPM-O/Omni-ähnlichen Modelle verschiedener Communities sind vergleichbar; der entscheidende Unterschied liegt in LongCats langem Kontext und der Sprachauflösung auf Millisekundenebene.
- Anwendungsseite: Die offizielle Website bietet eine iOS/Android-App und eine Web-Oberfläche zur Überprüfung der Sprachverbindungsleistung.
VI. Einschränkungen und Vorsichtsmaßnahmen
- Echte niedrige Latenzzeiten erfordern durchgängige Sprachverbindungen und Inferenzdienste mit hoher Bandbreite, die auf lokalen oder leistungsschwachen Rechnern nicht vollständig reproduziert werden können.
- Video-/lange Audioeingaben erhöhen den Videospeicher- und Rechenleistungsbedarf erheblich, daher ist es notwendig, das Material je nach Szenario zu kürzen oder zu segmentieren.
- Obwohl eine frühe multimodale Fusion die Konsistenz verbessern kann, reagiert sie empfindlich auf Datenformat und Annotationsqualität. Das sekundäre Training muss sich strikt an den offiziellen Beispielen orientieren.
- Open-Source-Repositories werden häufig aktualisiert, und Bereitstellungsskripte, Quantisierungsmethoden und Modellsharding sollten auf den neuesten Versionen basieren.
VII. Projektadresse
https://github.com/meituan-longcat/LongCat-Flash-Omni
VIII. Häufig gestellte Fragen
F: Benötigt LongCat-Flash-Omni eine Internetverbindung zur Durchführung von Inferenz?
A: Die Gewichte sind Open Source und können lokal oder privat eingesetzt werden. Für Sprachsynthese und multimodale Inferenz im großen Maßstab wird jedoch die Verwendung eines GPU-Clusters empfohlen, um die in der offiziellen Dokumentation gezeigte Echtzeitleistung zu erreichen.
F: In welchen Szenarien wird der 128K-Kontext hauptsächlich verwendet?
A: Geeignet für lange Besprechungen, das segmentierte Verständnis langer Videos und die Aufrechterhaltung des Status von mehrteiligen Sprachdialogen. Es kann auch als Eingabefenster für lange Dokumente in multimodalen RAG-Systemen verwendet werden.
F: Wenn nur Sprach-Ein- und -Ausgabe benötigt werden, ist es dann notwendig, die volle 560B zu laden?
A: Die offizielle Architektur ist ScMoE mit einer tatsächlichen Aktivierung von ca. 27 Bytes. Sie kann mit Quantisierung/Pruning und Single-Task-Feinabstimmung kombiniert werden, um den Ressourcenverbrauch zu reduzieren; Einzelheiten finden Sie in den Bereitstellungsanweisungen des Repositorys.


