I. 要約
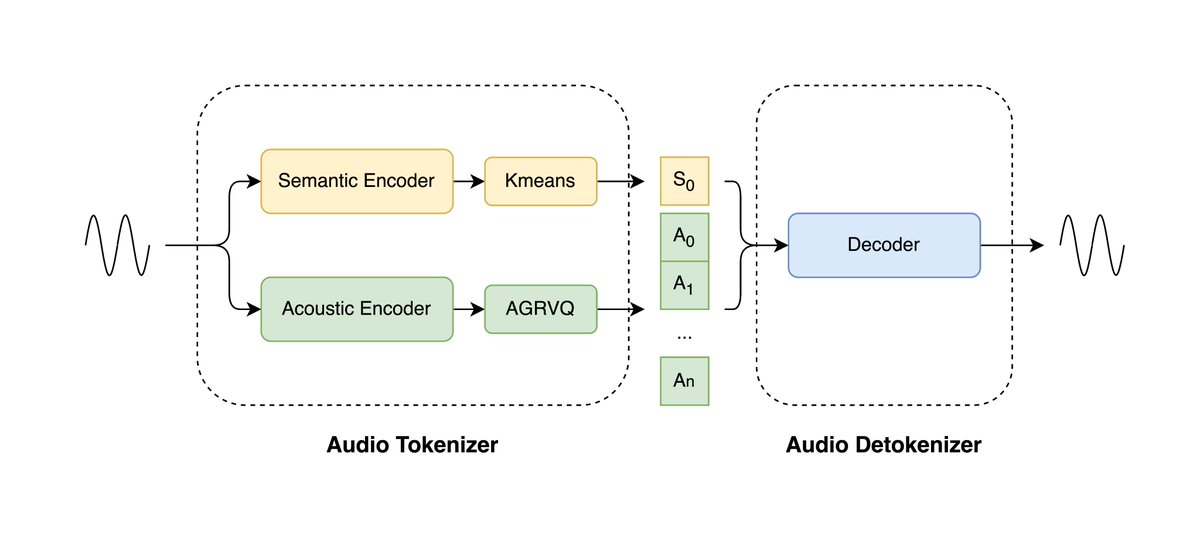
LongCat-Audio-Codecは、Meituan LongCatチームによって開発されたオープンソースのオーディオコーデックソリューションで、音声大規模モデル(LLM)向けに最適化されています。このプロジェクトは、デュアルトークンアーキテクチャを採用し、意味情報と音響情報を同時にモデル化することで、わずか0.43 kbpsという超低ビットレートでも音声の明瞭度と品質を維持します。リアルタイムストリーミングデコーダーは、数百ミリ秒単位のレイテンシーを維持し、音声インタラクションと組み込みシステムへの導入をサポートします。デコーダーに統合された超解像モジュールは、追加モデルを必要とせずに音質をさらに向上させ、エンドツーエンドの音声システムのリソースオーバーヘッドを大幅に削減します。
2. コア機能
1.デュアルトークン並列エンコーディング:意味トークンと音響トークンを同時に抽出し、16.7 Hz (60 ms) の低フレームレートで効率的な特徴モデリングを実現します。
2.極めて低いビットレートと高忠実度の再構成: 0.43 kbps で高い明瞭度を維持し、帯域幅の利用率を大幅に向上します。
3.リアルタイムの低遅延デコード:ストリーミング アーキテクチャを使用することで、全体的な遅延が数百ミリ秒に維持され、リアルタイムの音声生成とインタラクションのニーズを満たします。
4.デコード側の超解像度強化:統合された超解像度モジュールにより、外部モデルを必要とせずに音質の詳細が向上します。
5.軽量およびモバイル最適化: 組み込みデバイスおよびモバイル デバイスのコンピューティング能力の制限に対処するためのアーキテクチャの最適化。
3. インストール
1. リポジトリのクローン: git clone https://github.com/meituan-longcat/LongCat-Audio-Codec
2. インストール依存関係: pip install -r requirements.txt
3. モデルをロードします。Hugging Face を通じて meituan-longcat/LongCat-Audio-Codec の対応する重みをダウンロードできます。
- 例を実行します。リポジトリ内の推論スクリプトを実行して、エンコードとデコードの検証を実行します。
典型的な使用例
- 大規模音声モデルのフロントエンド圧縮:明瞭度を維持しながら入力帯域幅を削減します。
- リアルタイム音声インタラクションシステム:会話型 AI または音声アシスタントで低遅延伝送を実現します。
- エッジおよびモバイル デバイスの音声合成: ローカルで音声を生成またはデコードします。
- 長距離音声通信: 極めて低帯域幅の環境でもクリアな音声伝送品質を維持します。
5. エコシステムと競合製品
1.エコシステム統合:LongCat-Audio-Codec は Meituan LongCat シリーズ エコシステムの一部であり、LongCat-Flash などのモデルと連携して音声生成と理解を最適化します。
2.競合他社との比較: SemantiCodec、UniCodec、LMCodec などのニューラル コーデック ソリューションと比較して、LongCat-Audio-Codec は音声分野でより低いビット レートとより強力なリアルタイム パフォーマンスを実現します。
3.業界の重要性:音声 LLM の導入ハードルを下げ、モバイル AI アシスタントと音声サービスにインフラストラクチャ サポートを提供します。
VI. 制限事項と注意事項
- ビットレートが非常に低い場合でも、細部が失われて音質が損なわれる可能性があります。
- ストリーミング デコードでは、ハードウェアのリアルタイム パフォーマンスに対する要件が高くなります。
- モデルのバージョンによって、レイテンシーと音質のトレードオフが生じる場合があります。
- 超解像モジュールを統合すると計算負荷が増加します。
7. プロジェクト住所
https://github.com/meituan-longcat/LongCat-オーディオコーデック
8. よくある質問
Q: LongCat-Audio-Codec はオフライン展開をサポートしていますか?
A: 完全にオフラインで実行できますが、対応するモデルの重みと依存環境を準備する必要があります。
Q: このコーデックをモバイル デバイスに統合するにはどうすればよいですか?
A: 量子化モデルまたは軽量推論フレームワークを通じて、モバイル プラットフォームまたは組み込みプラットフォームに移植できます。
Q: 音声以外のオーディオにも使用できますか?
A: 現在のバージョンは主に音声タスク向けに最適化されており、他の種類のオーディオには追加のトレーニングが必要です。



