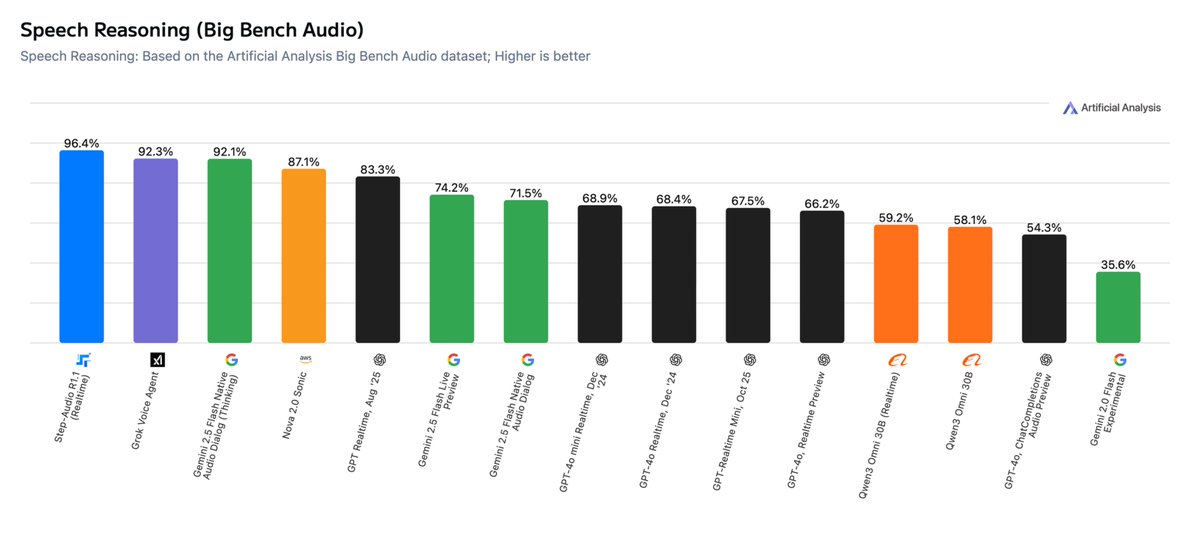
Step-Audio-R1.1 宣布上线,并称在 Artificial Analysis 的 Speech Reasoning 榜单位列第一;在 BigBench Audio 测试中取得约96.4% 准确率,同时在实时对话场景下实现约1.51秒的首帧音频输出。项目方强调,模型在深度推理与交互时延之间取得平衡,用于更贴近真实语音对话的场景。
官方介绍称,R1.1 在推理阶段引入“测试时算力伸缩”,并强化端到端音频推理与面向音频任务优化的可扩展 CoT。模型权重已开放,可在社区平台直接下载;同时提供在线体验入口。需要注意的是,榜单评测方法与设备网络差异可能影响实际表现,具体效果仍取决于应用场景与部署条件。
常见问题
Q:Step-Audio-R1.1 是什么?
A:Step-Audio-R1.1 是面向语音对话的音频大模型,强调深度推理与低时延兼顾。
Q:Step-Audio-R1.1 有哪些成绩?
A:公开成绩包含 BigBench Audio 约96.4% 准确率与约1.51秒 TTFA,并在相关榜单列首。
Q:Step-Audio-R1.1 的技术特点是什么?
A:模型采用测试时算力伸缩、端到端音频推理与面向音频的可扩展 CoT。
Q:Step-Audio-R1.1 是否开源?
A:权重与资源已公开,可在主流社区平台获取并本地部署。
Q:Step-Audio-R1.1 可在哪里试用?
A:可通过在线演示页面体验,亦可在平台页面下载权重自行运行。



