1. Résumé
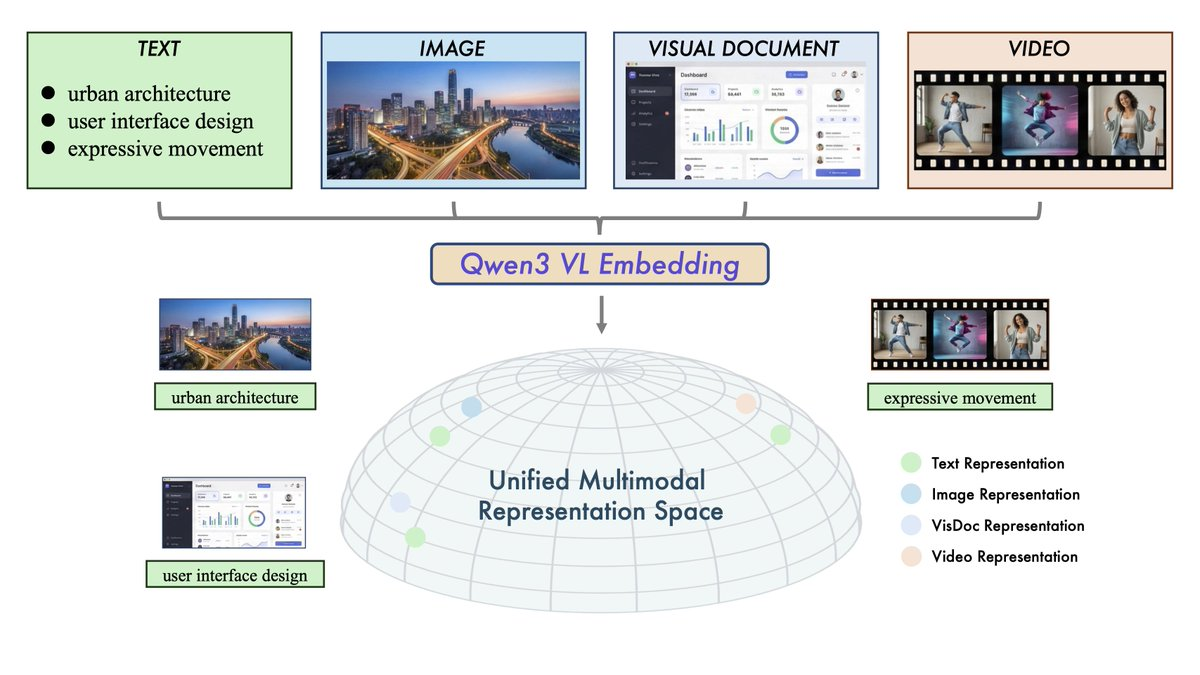
Qwen3-VL-Embedding et Qwen3-VL-Reranker sont des séries de modèles multimodaux open source basées sur Qwen3-VL, visant à la compréhension et à la récupération intermodale de « texte + image + capture d’écran + vidéo + entrée mixte ». L’architecture globale en deux étapes est adoptée : l’embedding est utilisé pour le rappel vectoriel à grande échelle, puis Reranker est utilisé pour la correlation fine afin d’améliorer la précision de la récupération finale et de couvrir des scénarios de 30+ langues.
2. Caractéristiques principales
- Unification multimodale des entrées : le même cadre gère le texte, les images, les captures d’écran, les vidéos et les modalités mixtes.
- Paradigme de récupération en deux étapes : l’immersion est responsable d’un rappel efficace ; Reranker est responsable de l’alignement fin et de la correction des erreurs.
- Dimensions vectorielles configurables : L’intégration prend en charge des dimensions de sortie flexibles (généralement utilisées pour équilibrer effets et coûts).
- Instructions personnalisables : Différentes cibles telles que « récupération/clustering/VQA/RAG multimodal » peuvent être adaptées via des instructions de tâche.
- Quantification et facilité en ingénierie : Prend en charge la quantification des sorties d’intégration pour réduire les coûts de stockage et de récupération ; La longueur du contexte est orientée vers la conception de scènes d’entrée longues.
3. Installation
- Cloner le dépôt et créer un environnement selon le script (le dépôt fournit un script d’environnement en un clic, adapté à la reproduction de l’exemple).
- Poids de téléchargement : Vous pouvez extraire l’Embedding et le Reranker de la taille correspondante (2B/8B) depuis Hugging Face ou ModelScope.
- Préparer l’exécution des dépendances : Les dépendances courantes incluent Transformers, PyTorch et les kits d’outils liés au prétraitement multimodal ; La version est basée sur le dépôt ou la carte de modèle.
4. Cas d’usage typiques
- Recherche graphique et textuelle : utiliser le texte pour trouver des images, utiliser des images pour trouver du texte (e-commerce, bibliothèque de matériel multimédia, base de connaissances).
- Recherche vidéo/correspondance vidéo-texte : Rechercher des extraits vidéo ou des vidéos candidates en langage naturel.
- RAG multimodal : vectoriser les pages graphiques, captures d’écran, graphiques et autres contenus, puis utiliser Reranker pour améliorer la qualité de la base de réponses.
- Questions et réponses visuelles et regroupement de contenu : utiliser un espace vectoriel unifié pour l’agrégation de contenu, la déduplication et le regroupement de sujets similaires.
- Recherche visuelle multilingue : requête interlinguistique et alignement de contenu inter-modal (sites internationaux, affaires transfrontalières).
5. Écologie et produits concurrents
- Écosystème : Les modèles sont disponibles en téléchargement et par exemple sur GitHub, Hugging Face et ModelScope pour faciliter l’accès aux bibliothèques vectorielles/cadres de recherche existants. Le responsable a également mentionné que des capacités de déploiement d’API cloud seront fournies à l’avenir.
- Produits concurrents : Les voies courantes pour la récupération vectorielle multimodale incluent des modèles vectoriels « apprentissage comparatif textuel graphique » tels que CLIP/SigLIP/OpenCLIP, ainsi que divers modèles multimodaux/encodeurs croisés d’arrangement fin. La différence entre Qwen3-VL-Embedding + Reranker réside dans la flexibilité d’ingénierie apportée par la base multimodale homologue, la collaboration en deux étapes, ainsi que les dimensions de directive et de configurabilité.
6. Limitations et précautions
- Le lien à deux étapes est plus complexe : il nécessite la maintenance des bibliothèques vectorielles et l’ajustement fin des services, et le coût de conception et de surveillance du système est plus élevé.
- Coûts vidéo et contexte long : Le décodage vidéo/extraction d’images vidéo et l’inférence de longues séquences augmenteront significativement la puissance de calcul et la latence.
- Sensibilité à l’instruction et aux données : différents corpus métier, différentes distributions linguistiques et modales influenceront l’effet, il est donc recommandé de procéder à une évaluation à petite échelle des annotages et à l’itération des prompts.
- La quantification doit être vérifiée : La quantification peut entraîner des fluctuations de précision, et des tests de régression doivent être réalisés sur des indicateurs clés.
7. Adresse du projet
https://github.com/QwenLM/Qwen3-VL-Embedding
8. Questions fréquemment posées
Q : Comment l’embedding Qwen3-VL est-il utilisé pour le rappel de récupération multimodale ?
R : Premièrement, encoder le « contenu image/texte/vidéo (ou sa représentation) » dans un stockage vectoriel ; Le côté requête l’encode également en vecteurs pour la récupération de similarité afin d’obtenir un ensemble candidat.
Q : Quels problèmes Qwen3-VL-Reranker résout-il dans le processus de recherche ?
R : Il évalue les candidats avec une corrélation fine afin d’atténuer des problèmes tels que le « désalignement de rappel de vecteurs, un alignement faible entre les modalités », et améliore la précision du top K.
Q : Quel est l’impact des dimensions d’intégration configurables sur les coûts ?
R : Plus la dimension est petite, plus le stockage et la vitesse de récupération vectorielle sont amicales. Cependant, une partie de la capacité d’expression peut être perdue, et il est nécessaire de peser les indicateurs métier.
Q : Comment les instructions doivent-elles être écrites dans les recherches multilingues ?
R : Il est souvent recommandé de personnaliser des instructions claires pour les tâches ; Si le scénario interlinguistique est complexe, vous pouvez donner la priorité aux instructions en anglais et évaluer l’effet sur le corpus cible.
Q : Le multimodal RAG doit-il d’abord faire des captures d’écran/images en OCR ?
R : Pas forcément ; Si le modèle et le processus supportent le traitement direct des images/captures d’écran, un encodage multimodal et un arrangement fin peuvent être réalisés directement. Cependant, lorsque des exigences telles que « fragmentation recherchable et citations interprétables » sont plus strictes, l’OCR/syntaxique de mise en page peut encore améliorer la contrôlabilité.