1. Zusammenfassung
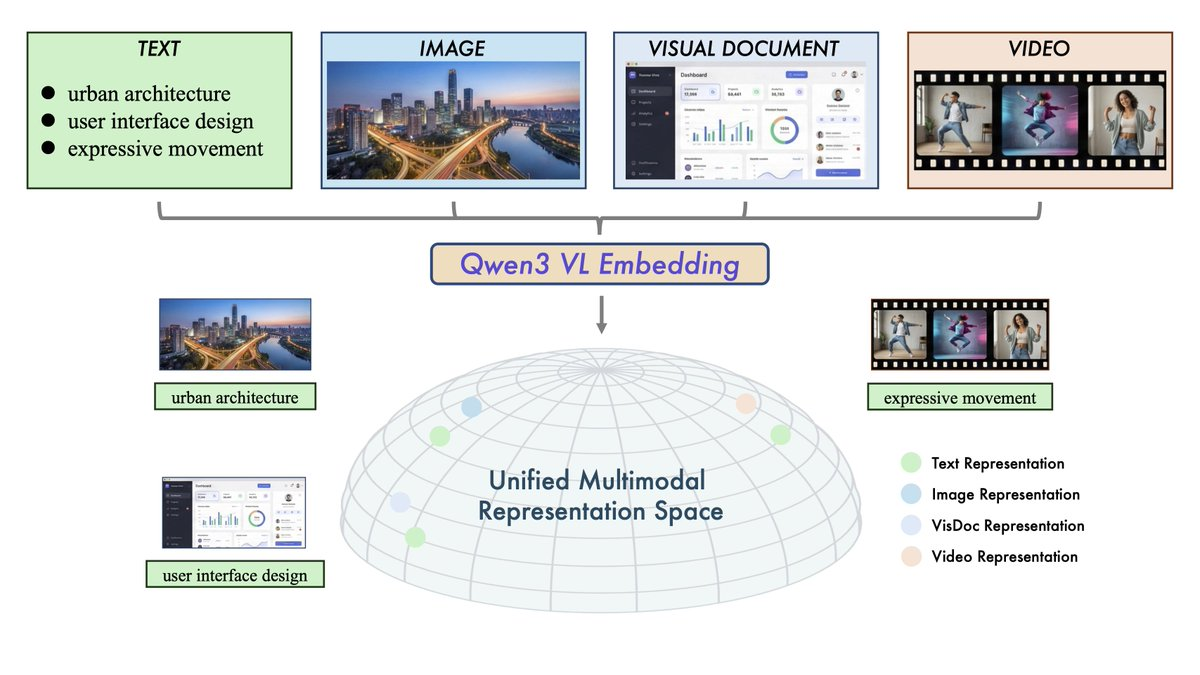
Qwen3-VL-Embedding und Qwen3-VL-Reranker sind Open-Source-multimodale Abrufmodellreihen, die auf Qwen3-VL basieren und auf das intermodale Verständnis und Abruf von "Text + Bild + Screenshot + Video + gemischte Eingabe" abzielen. Die übergeordnete zweistufige Architektur wird übernommen: Embedding wird für großflächige Vektorabrufe verwendet, dann Reranker für feinkörnige Korrelationsbewertungen, um die endgültige Abrufgenauigkeit zu verbessern und 30+ Sprachszenarien abzudecken.
2. Kernmerkmale
- Multimodale Eingabevereinigung: Dasselbe Framework behandelt Text, Bilder, Screenshots, Videos und gemischte Modalitäten.
- Zweistufiges Abrufparadigma: Einbettung ist für effizientes Abrufen verantwortlich; Reranker ist für die Feinausrichtung und Fehlerkorrektur verantwortlich.
- Konfigurierbare Vektordimensionen: Das Einbetten unterstützt flexible Ausgabedimensionen (typischerweise zum Ausbalancieren von Effekten und Kosten).
- Anpassbare Anweisungen: Verschiedene Ziele wie "Abruf/Clustering/VQA/multimodales RAG" können durch Aufgabenbefehle angepasst werden.
- Quantisierung und technische Freundlichkeit: Unterstützt die Quantisierung von Embedding-Ausgaben zur Reduzierung von Speicher- und Abrufkosten; Die Kontextlänge ist auf das Design von langen Eingabeszenen ausgerichtet.
3. Installation
- Klonen Sie das Repository und erstellen Sie eine Umgebung entsprechend dem Skript (das Repository stellt ein Ein-Klick-Umgebungsskript bereit, das sich zur Reproduktion des Beispiels eignet).
- Gewicht herunterladen: Du kannst das Einbetten und den Reranker der entsprechenden Größe (2B/8B) aus Hugging Face oder ModelScope ziehen.
- Bereite die Ausführung von Abhängigkeiten vor: Häufige Abhängigkeiten sind Transformers, PyTorch und Toolkits im Zusammenhang mit multimodaler Vorverarbeitung; Die Version basiert auf der Repository-/Modellkarte.
4. Typische Anwendungsfälle
- Grafische und Textsuche: Verwenden Sie Text, um Bilder zu finden, verwenden Sie Bilder, um Text zu finden (E-Commerce, Medienmaterialbibliothek, Wissensdatenbank).
- Videosuche/Video-Text-Abgleich: Suche nach Videoclips oder Kandidatenvideos in natürlicher Sprache.
- Multimodales RAG: Vektorisieren Sie die grafischen Seiten, Screenshots, Diagramme und andere Inhalte und verwenden Sie dann Reranker, um die Qualität der Antwortbasis zu verbessern.
- Visuelle Fragen & Antworten und Inhaltsclustering: Verwenden Sie einen einheitlichen Vektorraum für ähnliche Inhaltsaggregation, Deduplizierung und Themengruppierung.
- Mehrsprachige visuelle Suche: Sprachübergreifende Abfrage und intermodale Inhaltsausrichtung (internationale Seiten, grenzüberschreitende Geschäfte).
5. Ökologie und konkurrierende Produkte
- Ökosystem: Modelle sind zum Download und zum Beispiel auf GitHub, Hugging Face und ModelScope verfügbar, um den Zugang zu bestehenden Vektorbibliotheken/Suchframeworks zu erleichtern. Der Beamte erwähnte außerdem, dass in Zukunft Cloud-API-Bereitstellungsmöglichkeiten bereitgestellt werden.
- Konkurrierende Produkte: Gängige Wege für multimodale Vektorabrufe sind "graphisch-textvergleichendes Lernen"-Vektormodelle wie CLIP/SigLIP/OpenCLIP sowie verschiedene multimodale/Cross-Encoder-Feinanordnungsmodelle. Der Unterschied zwischen Qwen3-VL-Embedding + Reranker liegt in der technischen Flexibilität, die durch die homologe multimodale Basis, die zweistufige Zusammenarbeit sowie die Dimensionen Direktivisierung und Konfigurierbarkeit.
6. Einschränkungen und Vorsichtsmaßnahmen
- Die zweistufige Verbindung ist komplexer: Sie erfordert die Pflege von Vektorbibliotheken und Feinabstimmungsdiensten, und die Kosten für Systemdesign und Überwachung sind höher.
- Video- und Long-Context-Kosten: Videodekodierung/Frame-Extraktion und Long Sequence Inference erhöhen die Rechenleistung und Latenz erheblich.
- Instruktions- und Datensensitivität: Verschiedene Geschäftskorpora, Sprachen und modale Verteilungen beeinflussen den Effekt, daher wird empfohlen, eine Annotationsbewertung im kleinen Maßstab durchzuführen und Iterationen prompt durchzuführen.
- Quantifizierung muss überprüft werden: Quantifizierung kann zu Genauigkeitsschwankungen führen, und Regressionstests sollten an Schlüsselindikatoren durchgeführt werden.
7. Projektadresse
https://github.com/QwenLM/Qwen3-VL-Embedding
8. Häufig gestellte Fragen
F: Wie wird Qwen3-VL-Embedding für multimodale Abrufwiedergabe verwendet?
A: Zuerst kodiert man den "Bild-/Text-/Videoinhalt (oder dessen Darstellung)" in den Vektorspeicher; Die Abfrageseite kodiert es außerdem in Vektoren zur Ähnlichkeitsabfindung, um eine Kandidatenmenge zu erhalten.
F: Welche Probleme löst Qwen3-VL-Reranker im Suchprozess?
A: Sie bewertet Kandidaten mit feingranulärer Korrelation, um Probleme wie "Vektor-Rückruf-Fehlanpassungen, schwache Ausrichtung zwischen den Modalitäten" zu lindern, und verbessert die Genauigkeit der Top-K.
F: Welche Auswirkungen haben konfigurierbare Einbettungsmaße auf die Kosten?
A: Je kleiner die Dimension, desto freundlicher ist die Speicher- und Vektorabrufgeschwindigkeit. Allerdings kann ein Teil der Ausdrucksfähigkeit verloren gehen, weshalb es notwendig ist, die Geschäftsindikatoren zu gewichten.
F: Wie sollten Anweisungen in mehrsprachigen Suchen verfasst werden?
A: Es wird oft empfohlen, klare Anweisungen für Aufgaben anzupassen; Wenn das sprachübergreifende Szenario komplex ist, kannst du Englischunterricht Priorität geben und die Wirkung auf das Zielkorpus bewerten.
F: Muss multimodales RAG zuerst Screenshots/Bilder OCR-en?
A: Nicht unbedingt; Wenn Modell und Prozess die direkte Verarbeitung von Bildern/Screenshots unterstützen, können multimodale Codierungen und Feinanordnungen direkt durchgeführt werden. Wenn jedoch Anforderungen wie "durchsuchbare Fragmentierung und interpretierbare Zitate" stärker sind, kann OCR/Layout-Parsing die Steuerbarkeit dennoch verbessern.