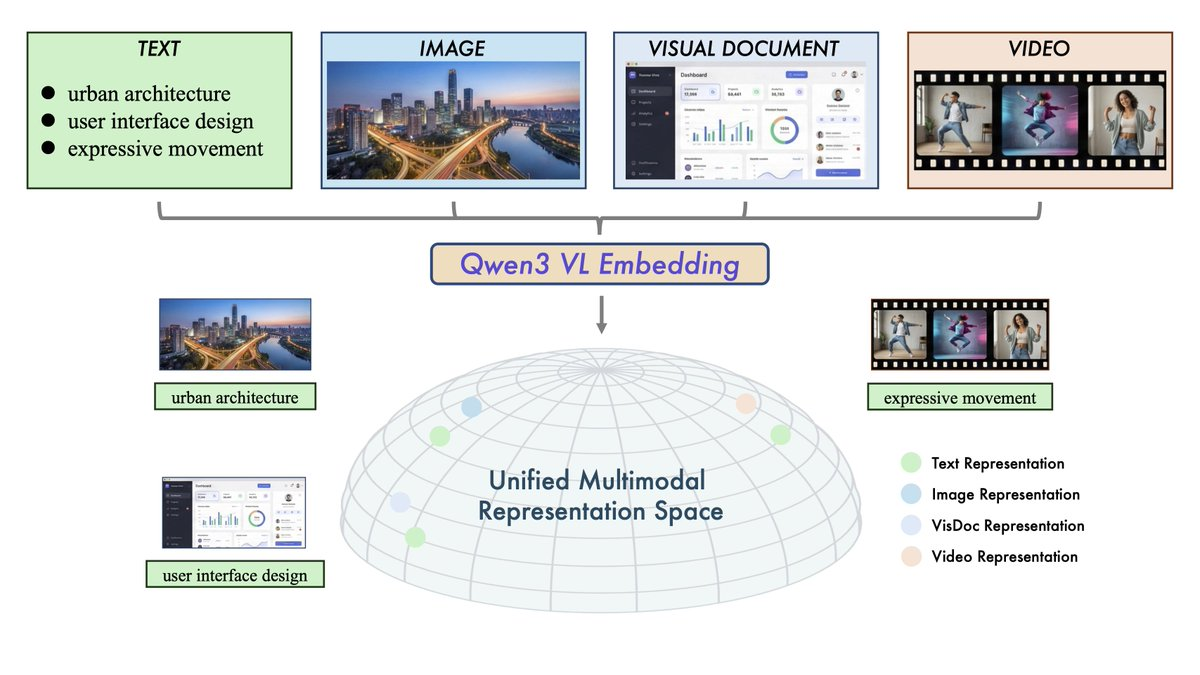
1. Abstract
Qwen3-VL-Embedding and Qwen3-VL-Reranker are open-source multimodal retrieval model series based on Qwen3-VL, which are aimed at cross-modal understanding and retrieval of "text + image + screenshot + video + mixed input". The overall two-stage architecture is adopted: Embedding is used for large-scale vector recall, and then Reranker is used for fine-grained correlation scoring to improve the final retrieval accuracy and cover 30+ language scenarios.
2. Core features
- Multimodal input unification: the same framework handles text, images, screenshots, videos and mixed modalities.
- Two-stage retrieval paradigm: embedding is responsible for efficient recall; Reranker is responsible for fine alignment and error correction.
- Configurable vector dimensions: Embedding supports flexible output dimensions (typically used to balance effects and costs).
- Customizable instructions: Different targets such as "retrieval/clustering/VQA/multimodal RAG" can be adapted through task instructions.
- Quantization and engineering friendliness: Supports quantization of embedding output to reduce storage and retrieval costs; Context length is oriented towards long input scene design.
3. Installation
- Clone the repository and create an environment according to the script (the repository provides a one-click environment script, which is suitable for reproducing the example).
- Download Weight: You can pull the Embedding and Reranker of the corresponding size (2B/8B) from Hugging Face or ModelScope.
- Prepare to run dependencies: Common dependencies include Transformers, PyTorch, and toolkits related to multimodal preprocessing; The version is based on the repository/model card.
4. Typical use cases
- Graphic and text search: use text to find pictures, use pictures to find text (e-commerce, media material library, knowledge base).
- Video search/video-text matching: Search video clips or candidate videos in natural language.
- Multimodal RAG: Vectorize the graphic pages, screenshots, charts and other content, and then use Reranker to improve the quality of the answer basis.
- Visual Q&A and content clustering: use a unified vector space for similar content aggregation, deduplication and topic grouping.
- Multilingual visual search: cross-language query and cross-modal content alignment (international sites, cross-border business).
5. Ecology and competing products
- Ecosystem: Models are available for download and example on GitHub, Hugging Face, and ModelScope to facilitate access to existing vector libraries/search frameworks. The official also mentioned that cloud API deployment capabilities will be provided in the future.
- Competing products: Common routes for multimodal vector retrieval include "graphic-text comparative learning" vector models such as CLIP/SigLIP/OpenCLIP, as well as various multimodal/cross-encoder fine arrangement models. The difference between Qwen3-VL-Embedding + Reranker is the engineering flexibility brought by the homologous multimodal base, two-stage collaboration, and directiveization and configurability dimensions.
6. Limitations and precautions
- The two-stage link is more complex: it requires maintenance of vector libraries and fine-tuning services, and the cost of system design and monitoring is higher.
- Video and long context costs: Video decoding/frame extraction and long sequence inference will significantly increase computing power and latency.
- Instruction and data sensitivity: Different business corpora, language and modal distribution will affect the effect, so it is recommended to do small-scale annotation evaluation and prompt iteration.
- Quantification needs to be verified: Quantification may bring accuracy fluctuations, and regression tests should be done on key indicators.
7. Project address
https://github.com/QwenLM/Qwen3-VL-Embedding
8. Frequently asked questions
Q: How is Qwen3-VL-Embedding used for multimodal retrieval recall?
A: First, encode the "image/text/video content (or its representation)" into vector storage; The query side also encodes it into vectors for similarity retrieval to obtain a candidate set.
Q: What problems does Qwen3-VL-Reranker solve in the search process?
A: It scores candidates with fine-grained correlation to alleviate issues such as "vector recall mismatching, weak alignment across modalities", and improves top-K accuracy.
Q: What is the impact of configurable embedding dimensions on costs?
A: The smaller the dimension, the more friendly the storage and vector retrieval speed. However, some of the expression ability may be lost, and it is necessary to weigh the business indicators.
Q: How should instructions be written in multilingual searches?
A: Customizing clear instructions for tasks is often recommended; If the cross-language scenario is complex, you can give priority to English instructions and evaluate the effect on the target corpus.
Q: Does multimodal RAG have to OCR screenshots/images first?
A: Not necessarily; If the model and process support direct processing of images/screenshots, multimodal encoding and fine arrangement can be carried out directly. However, when the requirements such as "searchable fragmentation and interpretable citations" are stronger, OCR/layout parsing may still improve controllability.