Zhipu AI was officially launched and open-sourced the industrial-grade speech synthesis system GLM-TTS. The system can learn the speaker's timbre and speaking habits through about three seconds of voice samples, and generate natural and smooth speech close to real people in scenarios such as general reading, emotional dubbing, educational evaluation, e-books, and audio customer service, with the goal of outputting a voice that is both real and emotionally appropriate in the appropriate scene.
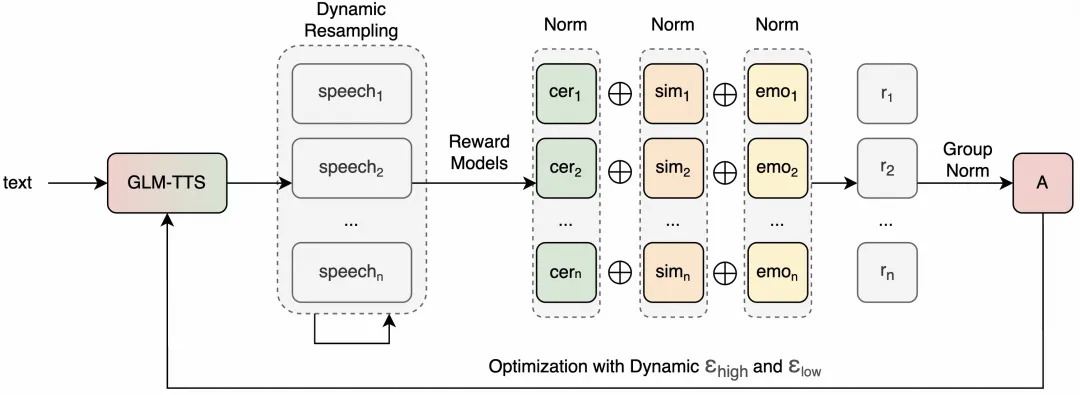
In terms of technical route, GLM-TTS adopts a two-stage generation architecture and introduces a GRPO-based reinforcement learning scheme in training, and achieves open-source SOTA performance in public evaluations such as character error rate and emotional expression. The model can achieve industry-leading pronunciation accuracy and timbre restoration using only about 100,000 hours of training data, and pre-training, high-quality timbre LORA, and reinforcement learning training can be completed within a few days on a single machine, greatly reducing training costs and thresholds.
In terms of application and ecology, GLM-TTS has verified the implementation effect for typical scenarios such as education, e-books, and intelligent customer service: it supports standard pronunciation of multi-syllable words, rare characters and symbols, supports multi-character and multi-emotional reading, and maintains a restrained and professional tone in customer service voice. At the same time, the project is open source in many communities using the Apache protocol, and provides an open platform, API, and online experience portal, making it convenient for developers and enterprises to quickly move from demo to production-level deployment.
FAQ
Q: What are the main capabilities and application scenarios of the GLM-TTS system?
A: The GLM-TTS system supports three-second voice cloning of the speaker's timbre, which is suitable for scenarios that require simulated human voice, such as general reading, emotional dubbing, educational evaluation, e-books, and audio customer service.
Q: What are the outstanding features of the GLM-TTS system in terms of technical route and effect?
A: The GLM-TTS system adopts two-stage generation and GRPO-based reinforcement learning, which achieves open-source SOTA in character error rate and emotional expression evaluation, while taking into account high timbre restoration and stability.
Q: How much training and deployment costs do developers need to use the GLM-TTS system?
A: Developers can use about 100,000 hours of data to complete training when using the GLM-TTS system, and pre-training, high-quality sound LORA, and reinforcement learning training can be completed within a few days on a single machine, and the deployment cost is relatively low.
Q: How can enterprise users access GLM-TTS system to online services?
A: Enterprise users can call GLM-TTS's text-to-speech and timbre replication capabilities through open platforms and API documents, configure billing and QPS according to business scale, and gradually expand from trial to production-level large-scale calls.
Q: How can ordinary users experience the synthesis effect of GLM-TTS system online?
A: Ordinary users can upload text or short voice prompts through audio.z.ai or Zhipu Qingyan and other portals to experience the actual effects of multi-style reading and exclusive timbre cloning.



