Zhipu AI a été officiellement lancé et a rendu open source le système industriel de synthèse vocale GLM-TTS. Le système peut apprendre le timbre et les habitudes de parole du locuteur à travers environ trois secondes d’échantillons vocaux, et générer une parole naturelle et fluide proche de personnes réelles dans des situations telles que la lecture générale, le doublage émotionnel, l’évaluation éducative, les livres électroniques et le service client audio, dans le but de produire une voix à la fois réelle et émotionnellement appropriée dans la scène appropriée.
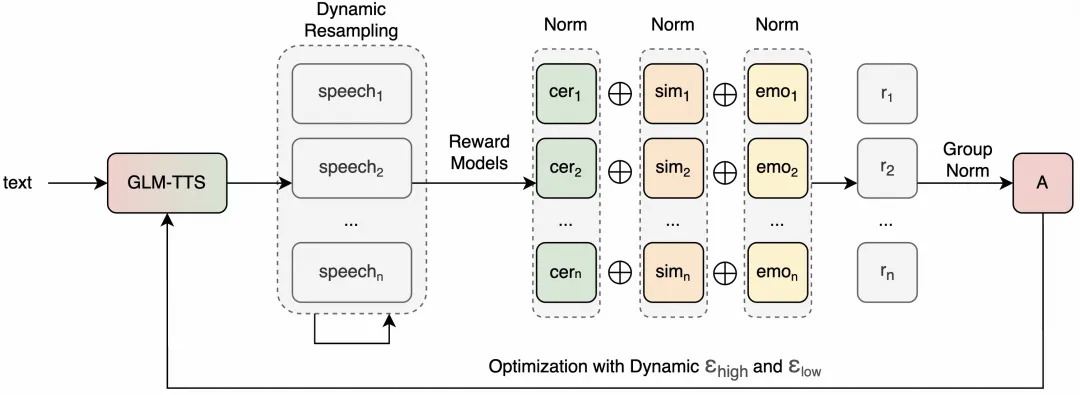
En termes de parcours technique, GLM-TTS adopte une architecture de génération en deux étapes et introduit un schéma d’apprentissage par renforcement basé sur GRPO dans la formation, et atteint la performance SOTA open source dans des évaluations publiques telles que le taux d’erreur de caractère et l’expression émotionnelle. Le modèle peut atteindre une précision de prononciation et une restauration du timbre de pointe dans l’industrie en utilisant seulement environ 100 000 heures de données d’entraînement, et la formation pré-entraînement, la LORA au timbre de haute qualité et l’apprentissage par renforcement peuvent être réalisées en quelques jours sur une seule machine, réduisant considérablement les coûts et les seuils d’entraînement.
En termes d’application et d’écologie, GLM-TTS a vérifié l’effet de mise en œuvre dans des scénarios typiques tels que l’éducation, les livres électroniques et le service client intelligent : il supporte la prononciation standard de mots multisyllabiques, de caractères et symboles rares, supporte la lecture multi-caractères et multi-émotionnelles, et maintient un ton réservé et professionnel dans la voix du service client. Parallèlement, le projet est open source dans de nombreuses communautés utilisant le protocole Apache, et offre une plateforme ouverte, une API et un portail d’expérience en ligne, facilitant la transition rapide des développeurs et des entreprises du déploiement au niveau production.
FAQ
Q : Quelles sont les principales capacités et scénarios d’application du système GLM-TTS ?
R : Le système GLM-TTS prend en charge le clonage vocal de trois secondes du timbre du haut-parleur, ce qui convient aux situations nécessitant une voix humaine simulée, telles que la lecture générale, le doublage émotionnel, l’évaluation éducative, les livres électroniques et le service client audio.
Q : Quelles sont les caractéristiques remarquables du système GLM-TTS en termes de parcours technique et d’effet ?
R : Le système GLM-TTS adopte la génération en deux étapes et l’apprentissage par renforcement basé sur GRPO, ce qui permet un SOTA open source en termes de taux d’erreur de caractère et d’évaluation de l’expression émotionnelle, tout en tenant compte d’une restauration et d’une stabilité élevées du timbre.
Q : De quels coûts de formation et de déploiement les développeurs ont-ils besoin pour utiliser le système GLM-TTS ?
R : Les développeurs peuvent utiliser environ 100 000 heures de données pour compléter l’entraînement avec le système GLM-TTS, et la pré-entraînement, la formation audio de haute qualité et l’apprentissage par renforcement peuvent être réalisées en quelques jours sur une seule machine, et le coût de déploiement est relativement faible.
Q : Comment les utilisateurs d’entreprise peuvent-ils accéder au système GLM-TTS aux services en ligne ?
R : Les utilisateurs d’entreprise peuvent appeler les capacités de synthèse vocale et de réplication timbre de GLM-TTS via des plateformes ouvertes et des documents API, configurer la facturation et QPS selon l’échelle métier, et progresser progressivement des appels d’essai à des appels de grande envergure en production.
Q : Comment les utilisateurs ordinaires peuvent-ils expérimenter l’effet de synthèse du système GLM-TTS en ligne ?
R : Les utilisateurs ordinaires peuvent télécharger du texte ou de courtes invitations vocales via audio.z.ai ou Zhipu Qingyan et d’autres portails pour découvrir les effets réels de la lecture multi-style et du clonage exclusif de timbre.



