Zhipu AI wurde offiziell eingeführt und hat das industrielle Sprachsynthesesystem GLM-TTS als Open Source veröffentlicht. Das System kann den Klangfarbe und die Sprachgewohnheiten des Sprechers durch etwa drei Sekunden Sprachproben erlernen und natürliche und flüssige Sprache erzeugen, die nahe an realen Menschen in Situationen wie allgemeiner Lesung, emotionaler Synchronisation, Bildungsbewertung, E-Books und Audio-Kundenservice liegt, mit dem Ziel, eine Stimme zu erzeugen, die sowohl real als auch emotional passend in der jeweiligen Szene ist.
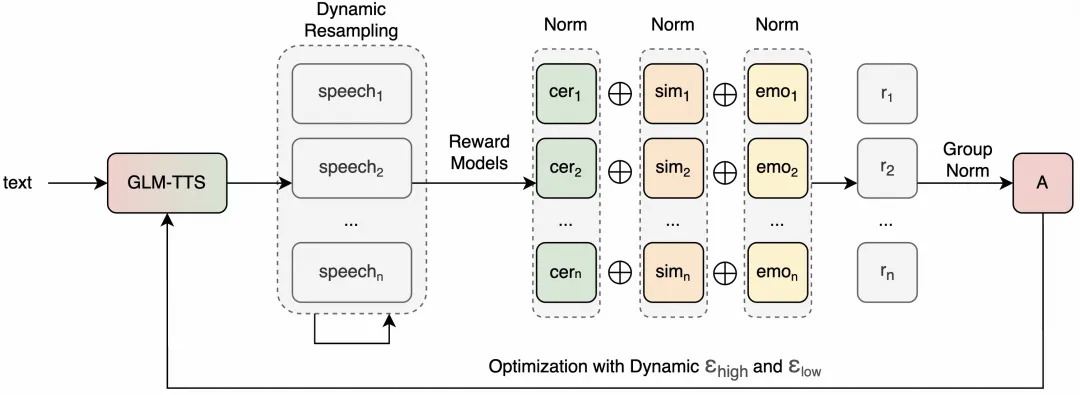
Technisch gesehen verwendet GLM-TTS eine zweistufige Generierungsarchitektur, führt ein GRPO-basiertes Reinforcement-Learning-Schema im Training ein und erreicht Open-Source-SOTA-Performance in öffentlichen Bewertungen wie Fehlerquote und emotionalen Ausdruck. Das Modell kann branchenführende Aussprachegenauigkeit und Klangfarbewiederherstellung mit nur etwa 100.000 Stunden Trainingsdaten erreichen, und Vortraining, hochwertiges Klangfarbe-LORA- und Reinforcement-Learning-Training kann innerhalb weniger Tage auf einer einzigen Maschine abgeschlossen werden, was die Trainingskosten und Schwellenwerte erheblich senkt.
In Bezug auf Anwendung und Ökologie hat GLM-TTS die Implementierungswirkung für typische Szenarien wie Bildung, E-Books und intelligenten Kundenservice bestätigt: Es unterstützt die Standardaussprache von mehrsilbigen Wörtern, seltenen Zeichen und Symbolen, unterstützt mehr- und mehr-emotionale Lesungen und bewahrt einen zurückhaltenden und professionellen Ton in der Kundenservice-Stimme. Gleichzeitig ist das Projekt in vielen Gemeinden Open Source und nutzt das Apache-Protokoll und bietet eine offene Plattform, API und ein Online-Erlebnisportal, was es Entwicklern und Unternehmen erleichtert, schnell von der Demo- auf Produktionsbereitstellung zu wechseln.
FAQ
F: Was sind die wichtigsten Fähigkeiten und Anwendungsszenarien des GLM-TTS-Systems?
A: Das GLM-TTS-System unterstützt das dreisekündige Klonen des Klangfarbes des Sprechers, was für Szenarien geeignet ist, die simulierte menschliche Stimme erfordern, wie allgemeine Lektüre, emotionale Synchronisation, Bildungsbewertung, E-Books und Audio-Kundenservice.
F: Was sind die herausragenden Merkmale des GLM-TTS-Systems in Bezug auf technische Route und Wirkung?
A: Das GLM-TTS-System verwendet zweistufige Generierung und GRPO-basiertes Reinforcement Learning, das Open-Source-SOTA bei der Zeichenfehlerrate und der Bewertung emotionaler Ausdrucksformen erreicht, wobei eine hohe Klangfarbe-Wiederherstellung und Stabilität berücksichtigt werden.
F: Wie hohe Schulungs- und Bereitstellungskosten benötigen Entwickler, um das GLM-TTS-System zu nutzen?
A: Entwickler können etwa 100.000 Stunden Daten verwenden, um das Training mit dem GLM-TTS-System abzuschließen, und Vorschulungen, hochwertige Sound-LORA- und Reinforcement-Learning-Schulungen können innerhalb weniger Tage auf einer einzigen Maschine abgeschlossen werden, wobei die Bereitstellungskosten relativ niedrig sind.
F: Wie können Unternehmensnutzer auf das GLM-TTS-System auf Online-Dienste zugreifen?
A: Unternehmensanwender können die Text-zu-Sprache- und Timbre-Replikationsfunktionen von GLM-TTS über offene Plattformen und API-Dokumente aufrufen, Abrechnung und QPS nach Geschäftsgröße konfigurieren und schrittweise von Test- bis zu groß angelegten Anrufen auf Produktionsebene erweitern.
F: Wie können gewöhnliche Nutzer den Syntheseeffekt des GLM-TTS-Systems online erleben?
A: Gewöhnliche Nutzer können Text- oder kurze Sprachanregungen über audio.z.ai oder Zhipu Qingyan und andere Portale hochladen, um die tatsächlichen Effekte von Multi-Style-Lesen und exklusivem Klangfarbe-Klonen zu erleben.



