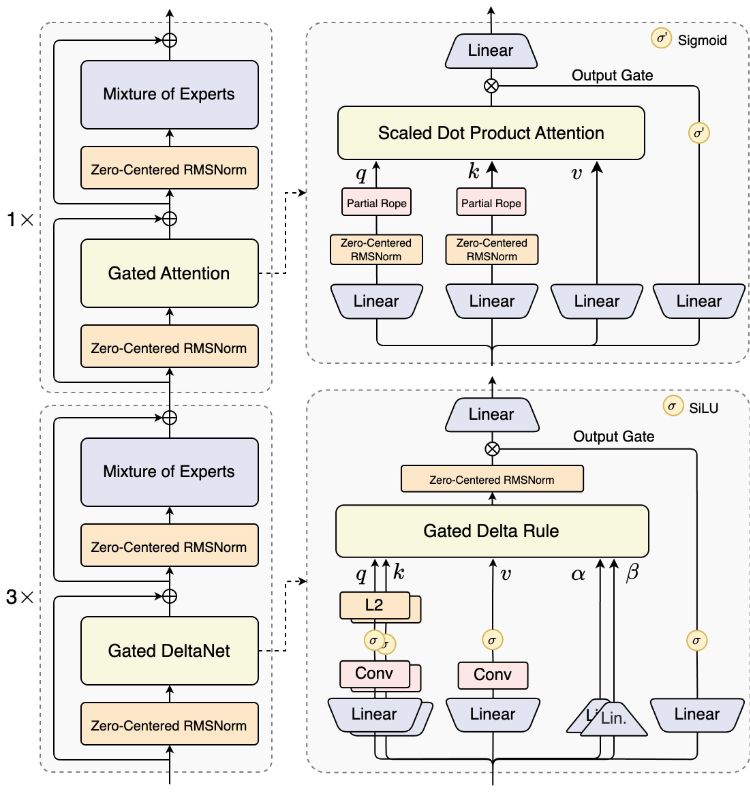
Qwen3-Next-80B-A3B focuses on 80B total parameters, only 3B activation per token, adopts Hybrid architecture (Gated DeltaNet+Gated Attention), Ultra-sparse MoE (512 experts, 10 routes + 1 sharing) and Multi-Token Prediction Thinking version.
1. Quick Summary
1. Core Parameters and Positioning
Qwen3-Next-80B-A3B aligns the large model capacity with 80B parameters, but achieves extremely sparse MoE through 3B activation; For long contexts above 32K, it emphasizes high throughput and low latency, making it suitable for retrieval enhancement and multi-document workflows.
2. Architecture Highlights
The hybrid solution introduces Gated DeltaNet and Gated Attention, and selects 10+1 among 512 experts with routing gating. MTP multi-token prediction and speculation decoding linkage to improve generation efficiency and stability. The A3B route ensures the cost-effectiveness of "large general staff and small activation".
3. Performance benchmarking
The official caliber said that the training cost is about an order of magnitude lower than that of Qwen3-32B, and the inference throughput of 32K+ scenes is significantly improved; Instruct is close to the 235B flagship, and the Thinking version benchmarks the mainstream chain-of-thought model in inference and long contexts.
2. Implementation and use
1. High-value scenarios
(1) Long document RAG and retrieval Q&A: Relying on long context and high throughput to process large blocks of knowledge
(2) Multi-round business assistant: cross-file instructions, tables and code mixed tasks
(3) Batch processing and offline generation: MTP Optimize throughput and cost with sparse routes
2. Deployment and tuning suggestions
(1) KV-Cache tiering and parallel batch processing, giving priority to optimizing 32K/64K gears
(2) Parallel tensor segmentation according to expert routing to reduce bandwidth hotspots
(3) Prompt word tracking: retrieval, code, and chain of thought templates are maintained separately
3. Migration and evaluation checklist
(1) Establish a Qwen3-32B/Qwen3-235B baseline and unify the evaluation script
(2) Measure quality, throughput, and cost in three dimensions, respectively; Record the impact of context length on performance
(3) Grayscale replacement: first switch between high-concurrency scenarios in long contexts, and then gradually cover general dialog
3. Risk control and compliance
1. Cost and quota
(1) Set call quotas and budget alarms according to tenants and projects
(2) Change large batch tasks to offline batch processing to reduce peak overhead
(3) Monitor the hit rate of token/KV per request to avoid implicit waste
2. Observability and quality regression
(1) Enforce the preservation of chains of thought and citation evidence summaries
(2) Enable manual sampling and rollback for key channels
(3) Version locking: model, 3
. Licensing and data security
(1) Follow model weights and API license terms
(2) Access enterprise data with least privileges and enable audit logs
(3) Configure filtering and manual review
Frequently Asked Questions (Q&A)
Q: What are the advantages of Qwen3-Next-80B-A3B's A3B and Ultra-sparse MoE?
A: A3B allows 80B general staff to participate in forward with only 3B activation, and with 512 expert 10+1 routing, it achieves higher throughput and lower billing, which is suitable for AI workloads in 32K+ long contexts and batch processing scenarios.
Q: How to choose the model with Qwen3-32B and Qwen3-235B?
A: In pursuit of cost-effectiveness and long-context efficiency, choose Qwen3-Next-80B-A3B; Flagship requirements that require absolute peak quality and maximum context are considered before the 235B; The stable stock production line can be temporarily retained at 32B as a control baseline.
Q: How does Multi-Token Prediction and Speculative Decoding work in engineering?
A: After enabling MTP, use a large parallel decoding window and monitor the rejection rate; Combined with speculative decoding, the actual latency can be further reduced, but the impact of different tasks on quality needs to be observed.
Q: What is the difference between Instruct and Thinking versions?
A: Instruct is oriented towards instruction compliance and general tasks; Thinking strengthens the chain of thought and reasoning, making it more stable in planning and tool use, and is more suitable for complex retrieval and long-link tasks.