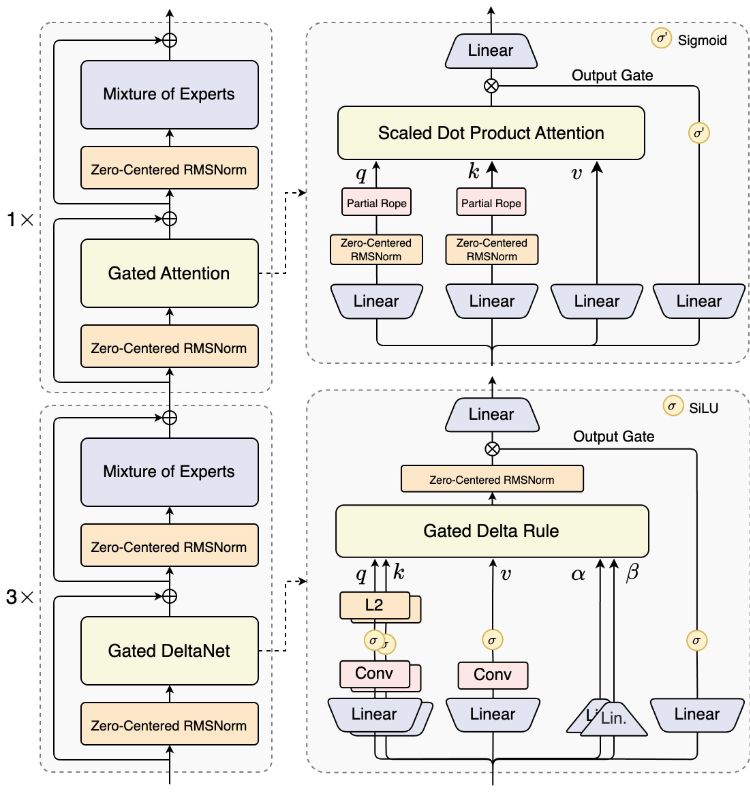
Qwen3-Next-80B-A3B は、合計 80B のパラメーターに焦点を当て、トークンあたり 3B のアクティベーションのみ、ハイブリッド アーキテクチャ (Gated DeltaNet+Gated Attention)、超スパース MoE (512 人の専門家、10 のルート + 1 つの共有)、およびマルチトークン予測を採用しています 思考バージョン。
1. クイックサマリー
1. コアパラメータと位置決め
Qwen3-Next-80B-A3B は、大容量モデルを 80B パラメータに合わせますが、3B アクティベーションによって非常にまばらな MoE を実現します。 32K を超える長いコンテキストでは、高スループットと低遅延が重視され、検索の強化や複数ドキュメントのワークフローに適しています。
2. アーキテクチャのハイライト
ハイブリッド ソリューションでは、Gated DeltaNet と Gated Attention が導入され、ルーティング ゲーティングを備えた 512 人の専門家の中から 10+1 を選択します。 MTP マルチトークン予測と投機デコード連携により、生成効率と安定性が向上します。 A3Bルートは「大人数の一般スタッフと小規模の活性化」という費用対効果を保証します。
3. パフォーマンスのベンチマーク
公式の口径によると、トレーニングコストは Qwen3-32B よりも約一桁低く、32K+ シーンの推論スループットが大幅に向上しています。 Instruct は 235B フラッグシップに近く、Thinking バージョンは推論と長いコンテキストで主流の思考連鎖モデルをベンチマークします。
2. 実装と使用
1. 価値の高いシナリオ
(1) 長いドキュメントの RAG と検索 Q&A: 長いコンテキストと高スループットに依存して大規模な知識ブロックを処理する
(2) マルチラウンド ビジネス アシスタント: ファイル間の命令、テーブル、コード混合タスク
(3) バッチ処理とオフライン生成: MTP スパース ルートでスループットとコストを最適化
2. 展開とチューニングの提案
(1) KV-Cache の階層化と並列バッチ処理、32K/64K ギアの最適化を優先
(2) 帯域幅ホットスポットを削減するためのエキスパート ルーティングによる並列テンソル セグメンテーション
(3) プロンプト ワードの追跡: 検索、コード、思考の連鎖テンプレートは個別に維持されます
3. 移行と評価のチェックリスト
(1) Qwen3-32B/Qwen3-235B ベースラインを確立し、評価スクリプトを統一
します(2) 品質、スループット、コストをそれぞれ 3 次元で測定します。 コンテキストの長さがパフォーマンスに与える影響を記録
する(3) グレースケールの置換: 最初に長いコンテキストで同時実行性の高いシナリオを切り替え、次に徐々に一般的なダイアログ
3. リスク管理とコンプライアンス
1. コストとクォータ
(1) テナントとプロジェクトに応じて通話クォータと予算アラームを設定する
(2) 大規模なバッチ タスクをオフライン バッチ処理に変更してピーク オーバーヘッドを削減
します(3) 暗黙の無駄を避けるためにリクエストごとのトークン/KV のヒット率を監視
します2. 可観測性と品質回帰
(1) 思考の連鎖と引用証拠の要約の保存を強制
する(2) 主要なチャネルの手動サンプリングとロールバックを有効にする
(3) バージョン ロック: モデル、 3
. ライセンスとデータセキュリティ
(1) モデルの重みと API ライセンス条項に従う
(2) 最小限の権限でエンタープライズデータにアクセスし、監査ログを有効にする
(3) 出力された機密コンテンツよくある質問 (Q&A)Q
: QWEN3-Next-80B-A3B の A3B と超スパース MoE の利点は何ですか?
A: A3B では、80B の一般スタッフが 3B アクティベーションのみでフォワードに参加でき、512 人のエキスパート 10+1 ルーティングにより、より高いスループットとより低い請求が達成され、32K+ の長いコンテキストやバッチ処理シナリオでの AI ワークロードに適しています。
Q: Qwen3-32B と Qwen3-235B のモデルを選択するにはどうすればよいですか?
A: 費用対効果と長期的なコンテキスト効率を追求するには、Qwen3-Next-80B-A3B を選択してください。 絶対的なピーク品質と最大のコンテキストを必要とするフラッグシップ要件は、235B の前に考慮されます。 安定した在庫生産ラインは、管理ベースラインとして32Bに一時的に保持できます。
Q: マルチトークン予測と投機的デコードはエンジニアリングでどのように機能しますか?
A: MTP を有効にした後、大きなパラレル デコード ウィンドウを使用して、拒否率を監視します。 投機的デコードと組み合わせることで、実際の遅延をさらに短縮できますが、さまざまなタスクが品質に与える影響を観察する必要があります。
Q: Instruct バージョンと Thinking バージョンの違いは何ですか?
A: インストラクトは、指示の遵守と一般的なタスクを対象としています。 思考は思考と推論の連鎖を強化し、計画とツールの使用をより安定させ、複雑な検索や長いリンクのタスクにより適しています。