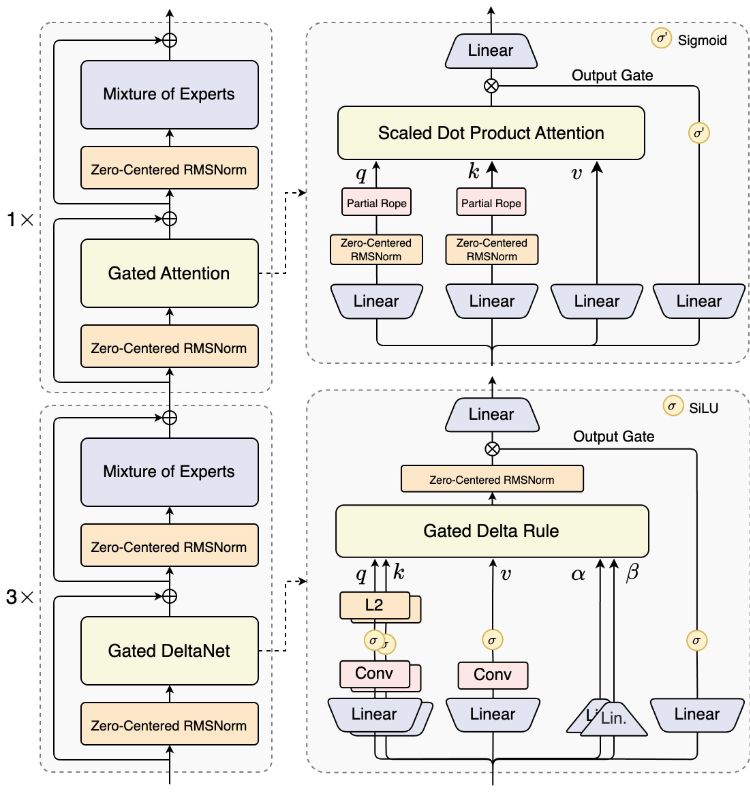
Qwen3-Next-80B-A3B 主打 80B 总参数、每 Token 仅 3B 激活,采用 Hybrid 架构(Gated DeltaNet+Gated Attention)、Ultra-sparse MoE(512 专家,10 路由+1 共享)与 Multi-Token Prediction,官方称训练更省、推理更快,并提供 Instruct 与 Thinking 版本。
一、速览要点
1、核心参数与定位
Qwen3-Next-80B-A3B 以 80B 总参对齐大模型容量,但通过 3B 激活实现极致稀疏 MoE;面向 32K 以上长上下文,强调高吞吐与低延迟,适合检索增强与多文档工作流。
2、架构亮点
Hybrid 方案引入 Gated DeltaNet 与 Gated Attention,配合路由门控在 512 专家中选 10+1;MTP 多 Token 预测与推测解码联动,提升生成效率与稳定性;A3B 路线保证“总参大、激活小”的性价比。
3、性能对标
官方口径称:训练成本较 Qwen3-32B 约降一个数量级,32K+场景推理吞吐显著提升;Instruct 逼近 235B 旗舰,Thinking 版在推理与长上下文上对标主流思维链模型。
二、落地与使用
1、高价值场景
(1)长文档 RAG 与检索问答:依托长上下文与高吞吐处理大块知识
(2)多轮业务助理:跨文件指令、表格与代码混合任务
(3)批处理与离线生成:MTP 与稀疏路由优化吞吐与成本
2、部署与调优建议
(1)KV-Cache 分层与并行批处理,优先优化 32K/64K 档位
(2)按专家路由做张量并行切分,减少带宽热点
(3)提示词分轨:检索型、代码型、思维链型分别维护模板
3、迁移与评测清单
(1)建立 Qwen3-32B/Qwen3-235B 基线,统一评测脚本
(2)分别测质量、吞吐、成本三维;记录上下文长度对性能的影响
(3)灰度替换:先在长上下文高并发场景切换,再逐步覆盖通用对话
三、风控与合规
1、成本与额度
(1)按租户与项目设置调用限额与预算告警
(2)将大批量任务改为离线批处理,降低峰值开销
(3)监控每请求 Token/KV 命中率,避免隐性浪费
2、可观测与质量回归
(1)强制保存思维链与引用证据摘要
(2)对关键信道启用人工抽检与回滚
(3)版本锁定:模型、路由及提示模板三方同版本管理
3、许可与数据安全
(1)遵循模型权重与 API 许可条款
(2)最小权限访问企业数据,开启审计日志
(3)对输出涉敏内容配置过滤与人工复核
常见问题解答(Q&A)
Q:Qwen3-Next-80B-A3B 的 A3B 与 Ultra-sparse MoE 有何优势?
A:A3B 让 80B 总参仅以 3B 激活参与前向,配合 512 专家 10+1 路由,实现更高吞吐与更低算费,适合 32K+长上下文与批处理场景的 AI 工作负载。
Q:与 Qwen3-32B、Qwen3-235B 如何选型?
A:追求性价比与长上下文效率选 Qwen3-Next-80B-A3B;需要绝对峰值质量与最大上下文的旗舰需求再考虑 235B;存量稳定产线可暂留 32B 做对照基线。
Q:Multi-Token Prediction 与推测解码在工程上怎么落地?
A:开启 MTP 后用较大的并行解码窗口并监控拒绝率;结合推测解码可进一步降低实际延迟,但需观察不同任务对质量的影响。
Q:Instruct 与 Thinking 版本差异是什么?
A:Instruct 面向指令遵循与通用任务;Thinking 加强思维链与推理,在规划与工具使用上更稳,更适合复杂检索与长链路任务。