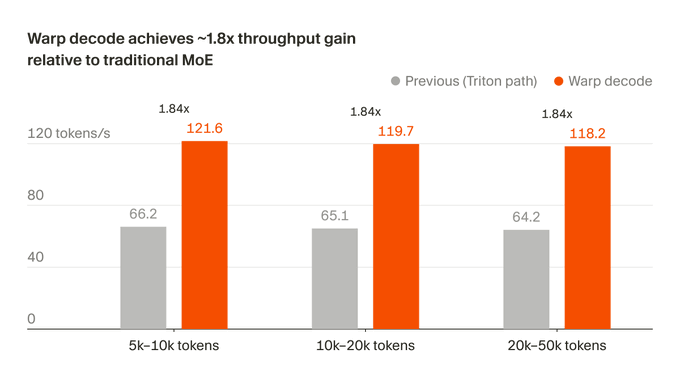
Cursorrecently disclosed that it reconstructs the token generation path of theMoE modelBlackwell GPU and named this method warp decode. Officials said that this underlying optimization brings about a 1.84-fold increase in inference throughput and makes the output result closer to the FP32 reference value; related improvements have also been used in the training process ofComposerto speed up model iteration and version release.
Cursor rewritten the MoE decoding again
The core of this update is not just to replace the model with a faster GPU, but to rewrite the way MoE decodes on Blackwell. Traditional solutions organize calculations by experts, while Cursor flips the parallel axis to outputs, making each warp responsible for an output value, rather than circling around expert routing.
This adjustment is aimed at small-batch decode scenarios. When the MoE model generates a single token, many steps are originally spent on data sorting, handling and intermediate buffering, and the proportion actually used for calculation is not high. The meaning of warp decode is to suppress these extra links as much as possible.
1.84x speed increase is the shortening of the inference link
According to Cursor, warp decode compresses the entire layer of MoE calculation into two kernels: More importantly, this optimization did not stop at "faster". The official also emphasized that the output result is closer to the FP32 reference value, which makes warp decode not just throughput optimization, but also more like an underlying reconstruction that takes into account numerical performance. For code generation models, stability is often as important as speed. Cursor connected this update directly to Composer in the original statement. The official logic is clear: pre-training data and RL determine the upper limit of the model, but the efficiency of the inference chain will affect how fast research, training and verification feedback runs, and this is related to the pace of Composer version updates. This also explains why Cursor would highlight this engineering work alone. For AI companies, underlying kernel optimization is not just infrastructure improvements. It will in turn affect the speed of model development, release frequency, and ultimately deliver experience to developers. Rewriting the MoE decode around Blackwell GPUs shows that the competition for large models is returning to underlying execution efficiency. Cursor did not talk about larger parameter sizes this time, but focused on throughput, accuracy and iteration speed. For Composer, whether such system-level optimizations can continue to translate into faster updates may be more noteworthy than a version naming change.moe_gate_up_3d_batchedand_CODE_INLINE_1__. The middle no longer relies on multiple stages, cross-warp synchronization and extra buffers, and the inference path is shorter than traditional expert-centric schemes.Composer began to enjoy the benefits of system-level optimization



