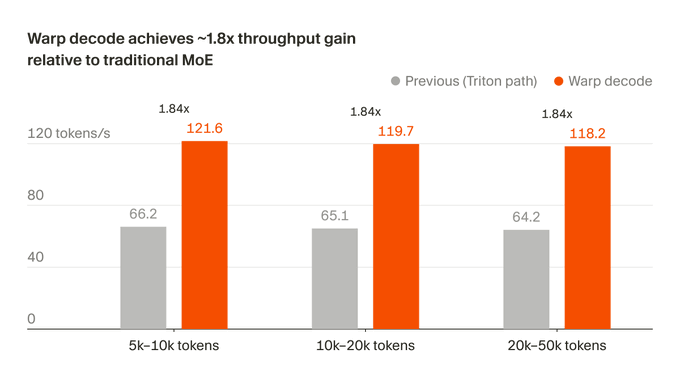
Cursor hat kürzlich bekannt gegeben, dass er den Token-Generierungspfad des MoE-Modells auf der Blackwell GPU neu konfiguriert hat und diese Methode als Warp Decode benannt hat.官方称,这项底层优化带来 1.84 倍推理吞吐提升,同时让输出结果更接近 FP32 参考值;相关改进也已用于 Composer 的训练流程,以加快模型迭代和版本发布。
Cursor hat die Decodierung von MoE neu geschrieben
Der Kern dieses Updates ist nicht nur ein schnelleres GPU für das Modell, sondern die Art und Weise, wie MoE auf Blackwell decodiert wird, neu geschrieben. Bei traditionellen Szenarien, in denen Experten berechnet werden, dreht der Cursor die parallele Achse zu Outputs um, sodass jede Warp für einen Ausgabewert verantwortlich ist, anstatt sich um die Expertenrouten zu drehen.
Diese Änderung richtet sich an kleine Batch-Decodierungsszenarien. Bei der Erstellung eines einzelnen Tokens im MoE-Modell wurden ursprünglich viele Schritte für die Datenverarbeitung, das Handling und das Zwischenpuffering verwendet, und der Anteil der tatsächlichen Berechnungen ist nicht hoch. Warp-Decode ist das Ziel, diese zusätzlichen Verbindungen so weit wie möglich zu unterdrücken.
Hinter der 1,84 - fachen Beschleunigung steht eine kürzere Inferenz-Links
Laut Cursor komprimiert die Warp-Decode die gesamte Schicht der MoE-Berechnung in zwei Kernels: _ _ CODE_INLINE_0__ und _ _ CODE_INLINE_1__. Es ist nicht mehr auf mehrere Stagings, Cross-Warp - Synchronisation und zusätzlichen Puffern angewiesen, und die Inferenzpfade sind kürzer als herkömmliche expertenzentrische Szenarien. Die offizielle Logik ist eindeutig: Vortraining-Daten und RL bestimmen die Obergrenzen des Modells, aber die Effizienz der Inferenz-Links beeinflusst, wie schnell das Feedback von Forschung, Training und Validierung läuft, was das Tempo der Composer-Version - Updates beeinflusst. Dies erklärt auch, warum der Cursor diese Engineering-Arbeit ausschließlich betont. Für KI-Unternehmen ist die Kerneloptimierung nicht nur eine Verbesserung der Infrastruktur, sondern beeinflusst wiederum die Geschwindigkeit der Modellentwicklung, die Frequenz der Veröffentlichung und letztlich die Erfahrung, die an die Entwickler geliefert wird. Die Umschreibung des MoE-Decodes um die Blackwell-GPUs zeigt, dass die Konkurrenz für große Modelle zurückkehrt, um die Effizienz zu erreichen. Der Cursor spricht diesmal nicht von einer größeren Parametergröße, sondern konzentriert sich auf Durchsatz, Genauigkeit und Iterationsgeschwindigkeit. Ob diese Optimierungen auf Systemebene kontinuierlich in schnellere Updates übersetzt werden können, ist für Composer wahrscheinlich mehr interessant als eine einzige Änderung der Versionsbenennung. Wichtiger ist, dass diese Optimierung nicht auf "schneller" aufgehört hat. Das Ergebnis ist im Vergleich zum FP32 - Referenzwert näher, wodurch die Warp Decode nicht nur für den Durchsatz optimiert wird, sondern auch für eine numerische Leistung wie eine grundlegende Refactoring. Stabilität ist für Modelle der Codegenerierung oft genauso wichtig wie Geschwindigkeit.Composer beginnt die System-Ebene - Optimierungsdividende zu nutzen Cursor verbindet dieses Update direkt mit Composer in der ursprünglichen Formulierung.



