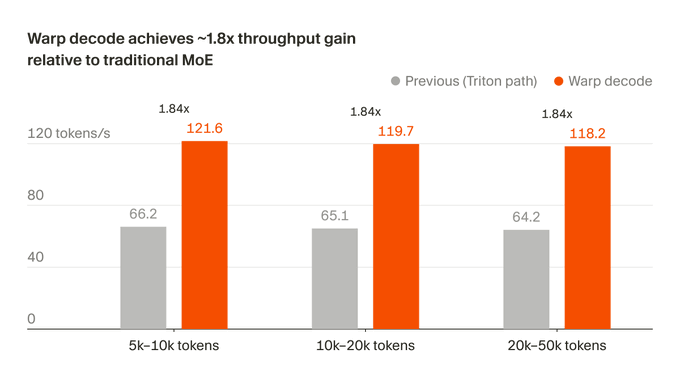
Cursor は最近、 Blackwell GPU で MoE model のトークン生成パスを再構築し、このメソッドをwarp decodeと名付けたことを明らかにしました。公式には、この低レベルの最適化は推論スループットを1.84 倍に向上させ、出力をFP32の参照値に近づけます。関連する改善は、モデルの反復とバージョンリリースをスピードアップするために、Composer のトレーニングフローにも使用されています。
CursorはMoEデコードを書き直しました
従来のシナリオでは、計算をエキスパート単位で構成していますが、Cursorは並列軸をoutputsに反転させ、エキスパートルートの周りを回転させるのではなく、各warpに出力値を割り当てます。
この調整は、小ロットデコーディングシナリオをターゲットとしています。MoEモデルが単一のトークンを生成する場合、データの照合、処理、中間バッファリングに多くのステップが費やされており、実際に計算に使用される割合は高くありません。ワープデコードのポイントは、これらの余分なリンクをできるだけ小さくすることです。 1.84倍高速化の背後には推論リンクが短くなることがあります
カーソルによると、warp decodeはMoE計算の層全体を2つのカーネルに圧縮します:moe_gate_up_3d_batchedと_moe_down_3d_batched。中間は複数のステージング、ワープ間の同期、追加のバッファに依存しなくなり、推論パスは従来のexpert-centricスキームよりも短くなります。さらに重要なことに、この最適化は“高速化”にとどまらなかった。また、出力結果はFP32リファレンス値に近いため、Warp Decodeはスループット最適化だけでなく、数値性能を考慮した低レベルのリファクタリングのようなものになります。コード生成モデルでは、安定性はスピードと同じくらい重要になります。 Composerはシステムレイヤ最適化ボーナスを受け取り始めました
Cursorは、オリジナルのプレゼンテーションでこの更新をComposerに直接リンクしました。事前学習データとRLがモデルの上限を決定しますが、推論リンクの効率性は、研究、トレーニング、検証フィードバックの実行速度に影響し、Composerのバージョン更新のペースに影響します。
これは、カーソルがこのエンジニアリング作業を単独で強調した理由を説明します。AI企業にとって、基盤となるカーネル最適化は単なるインフラストラクチャの改善ではなく、モデル開発のスピード、リリース頻度、そして最終的に開発者に提供されるエクスペリエンスに影響を与えます。
Blackwell GPU周辺のMoEデコードの書き換えは、ビッグモデル競争が低レベルの実行効率に戻っていることを示します。Cursor氏は今回、より大きなパラメータサイズに言及する代わりに、スループット、精度、反復速度に焦点を当てました。Composerにとって、このようなシステムレベルの最適化がより速いアップデートにつながるかどうかは、バージョン名の変更よりも重要かもしれません。
のコメント


