The LongCat team has released the LongCat-AudioDiT and simultaneously released code, technical reports and Hugging Face weights. It mainly conducts diffusion TTS directly in the waveform latent space, and no longer detours back to intermediate representations such as mel. What attracts the most attention of the voice circle is that it puts tone clone scores, model weights and inference code on the table together.
- The most important thing this time is not the parameters, but the generation path has changed
LongCat-AudioDiT follows a non-autoregressive diffusion route, structurally compressed into two stages: Wav-VAE and Diffusion. The core statement given by the official is very straightforward: this is done to reduce cascading errors, shorten the speech generation link, and also deal with the common distortion problems of diffuse TTS forward.
Second, this wave is not just publishing papers. 1B and 3.5B can already download
The repository has released inference codes. The model page also provides two versions 1B and 3.5B, supporting Chinese and English audio generation. For developers, this is more practical than just giving a report, because both ordinary TTS and voice cloning with prompt audio can be verified directly.
- What the official wants to emphasize most is the tone cloning results on Seed Benchmark
According to the public model card, the SIM on Seed-ZH and Seed-Hard for version 3.5B reaches 0.818 and 0.797 respectively, and the SIM on version 1B reaches 0.812 and 0.787. This score is very eye-catching, but a more reliable understanding is still "leading performance based on officially announced benchmarks." Later, we will need to see more community auditions and reproduction results.
Fourth, the real technical point is the APG and mismatch processing
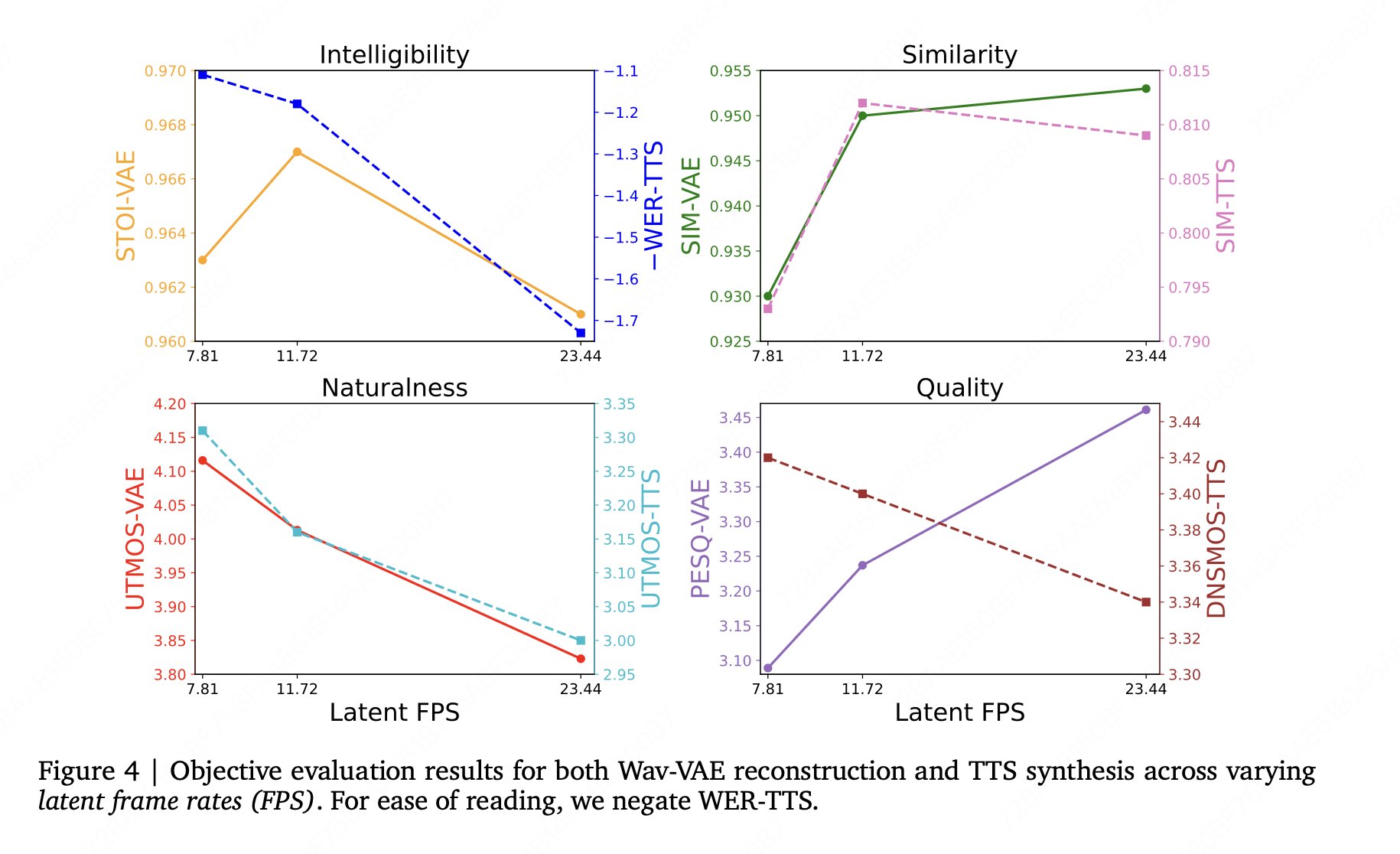
This time, not only did the CFG be replaced by APG, the team also took out the long-standing training-interference mismatch in the diffusion TTS separately. Another easy-to-remember conclusion in the report is also counterintuitive: Better VAE reconstruction may not necessarily be directly exchanged for stronger overall TTS performance.
- How to determine whether this set of things is worth it? Try it now
It takes two steps: first check whether the warehouse has provided a complete inference entry, and then check whether the model page has hung up weights that can be directly called. Now that both are in place, it's more like a workable research-oriented open source set rather than just stopping at a concept demonstration.