1. Abstract
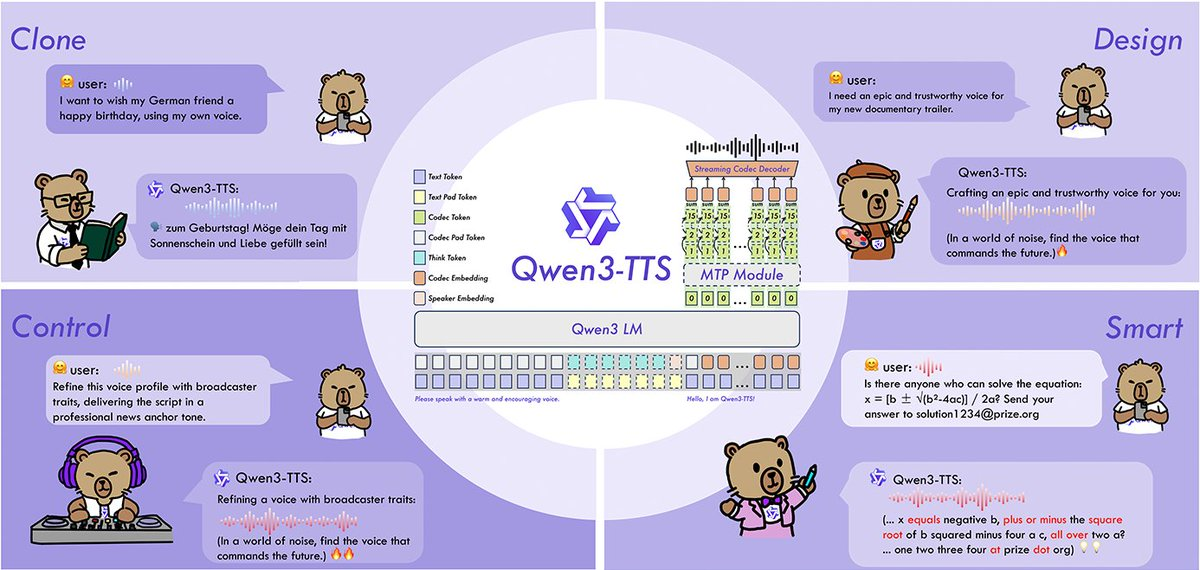
Qwen3-TTS is a family of open-source text-to-speech (TTS) models from the Qwen team, including VoiceDesign (to generate new voices from text descriptions), CustomVoice (command control of predetermined high-quality sounds), and Base (fast voice cloning and fine-tuning base). The project open-sources both code and weight, and provides a 12Hz voice tokenizer to achieve higher compression and streaming synthesis capabilities, for real-time conversations, dubbing, and personalized voice scenarios.
2. Core features
1. Full family capability coverage: VoiceDesign (free voice design), CustomVoice (custom timbre and style control), Base (3-second fast timbre cloning, can be used for full fine-tuning).
2. Two scales: The published models cover about 0.6B and 1.7B parameters (some publicity calibers will be written as about 1.8B, it is recommended to refer to the warehouse and model card labeling).
3. 10 Language support: Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian, and provide multiple dialects/timbre configurations.
4. 12Hz tokenizer high compression: expresses speech at a lower token frequency, reduces bandwidth and inference burden, and is suitable for streaming and offline synthesis.
5. Controllable and robust: Support the use of natural language commands to control speech speed, emotion, prosody, etc., improving stability for noisy text and complex inputs.
6. Full fine-tuning path: The warehouse provides fine-tuning related catalogs and examples, which is convenient for industry corpus, brand timbre or specific accent adaptation.
3. Installation
- Python environment: It is recommended to create a new Python 3.12 virtual environment.
2. One-click installation: Directly install the PyPI package qwen-tts; If local modifications are required, clone the repository and pip install -e . it.
- Resource optimization: The official recommendation is to install FlashAttention 2 to reduce the memory usage. Weights can also be pre-downloaded locally via Hugging Face / ModelScope.
4. Typical use cases
- Product/customer service voice: low-latency streaming broadcasting, adapted to conversational assistants and real-time simultaneous interpretation.
- Content creation and dubbing: Use commands to control emotions and speech speed to generate multi-style narration.
- Personalized voice: 3 seconds of reference audio for timbre cloning, used as a personal assistant or barrier-free reading (authorization required).
- Games and virtual humans: VoiceDesign quickly generates character timbres through text descriptions, and then superimposes style controls.
- Industry fine-tuning: Use its own corpus for full fine-tuning to improve terminology reading, accent consistency and brand timbre stability.
5. Ecology and competing products
- Ecosystem: Provide Hugging Face/ModelScope model collection and online demo; Natively supports Web UI launch; At the same time, provide API documentation related to DashScope/Model Studio; And mentioned the integration direction of vLLM-Omni.
- Competing products: Common solutions on the open source side include Coqui TTS, Bark, XTTS, StyleTTS2, etc., focusing on multilingualism, clone quality, controllability, and deployment costs. The difference of Qwen3-TTS is more focused on the integration of "voice design + cloning + streaming low latency + 12Hz high-compression tokenizer + fine-tuning link".
6. Limitations and precautions
- Computing power and video memory: Larger models and high-quality output usually consume more GPU; Streaming services also need to pay attention to concurrency and latency jitter.
- Timbre compliance: Timbre cloning and onomatopoeia may involve portrait rights/sound rights and content compliance, so be sure to obtain authorization and do a good job of use boundaries.
- Quality boundary: Pronunciation deviations and prosody instability may still occur in different languages, accents, extreme emotions or ultra-long texts, so it is recommended to add manual sampling and post-processing.
- Production deployment: Browser microphone permissions, HTTPS, gateway, and certificate configuration will affect the availability of the demo/service and need to be handled according to the official instructions.
7. Project address
https://github.com/QwenLM/Qwen3-TTS
8. Frequently asked questions
Q: What languages and voices does Qwen3-TTS support?
A: 10 languages are covered and multiple dialect/timbre configurations are available; The specific details are subject to the model card and warehouse description.
Q: What is the difference between Qwen3-TTS's VoiceDesign and Voice Clone?
A: VoiceDesign describes the "design" of a new sound in words; Voice Clone replicates the target speaker's timbre with a short reference audio, such as 3 seconds.
Q: What is the value of the Qwen3-TTS 12Hz tokenizer?
A: Lower frequency voice token expression can bring higher compression and lower latency potential, suitable for streaming real-time synthesis and cost control.
Q: Can Qwen3-TTS be fine-tuning?
A: Yes, the warehouse provides fine-tuning related code and sample processes, which is suitable for industry corpus and brand tone adaptation.
Q: How does Qwen3-TTS experience the demo quickly?
A: You can use Hugging Face/ModelScope online demo, or launch the official web UI command after installing qwen-tts locally to experience it.



