1. Résumé
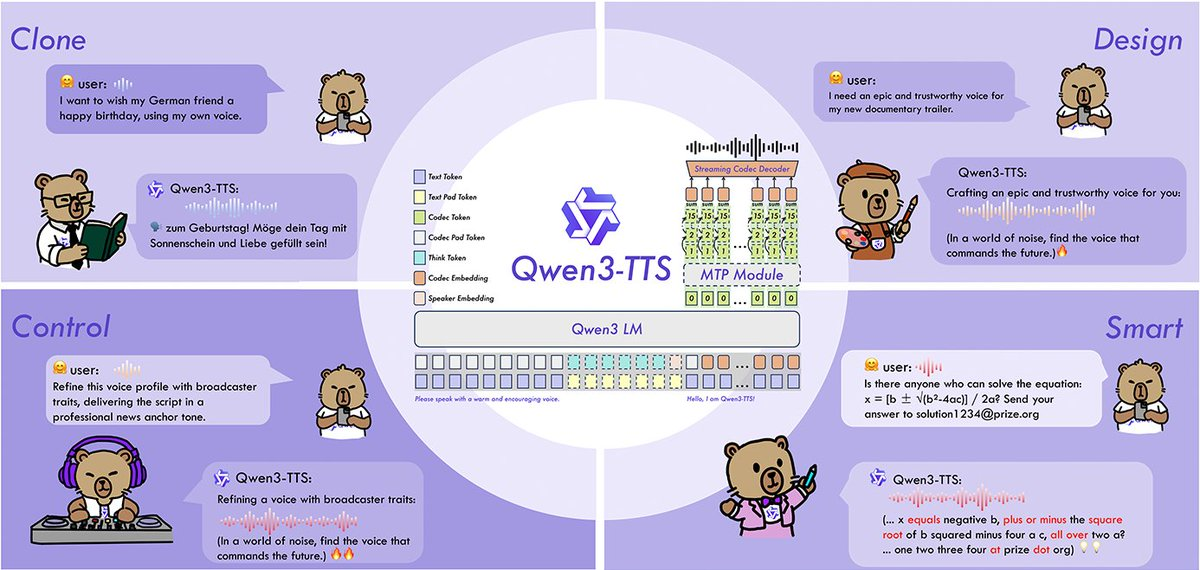
Qwen3-TTS est une famille de modèles open source de synthèse vocale (TTS) de l’équipe Qwen, incluant VoiceDesign (pour générer de nouvelles voix à partir de descriptions textuelles), CustomVoice (contrôle par commande de sons de haute qualité prédéterminés) et Base (base de clonage rapide et d’ajustement fin de la voix). Le projet ouvre en source à la fois le code et le poids, et propose un tokeniseur vocal à 12Hz pour obtenir des capacités de compression et de synthèse en streaming plus élevées, pour des conversations en temps réel, du doublage et des scénarios vocaux personnalisés.
2. Caractéristiques principales
1. Couverture complète des capacités familiales : VoiceDesign (conception vocale gratuite), CustomVoice (timbre et contrôle de style personnalisés), Base (clonage rapide de timbre en 3 secondes, utilisable pour un réglage complet de la musique).
2. Deux échelles : Les modèles publiés couvrent environ 0,6B et 1,7B (certains calibres publicitaires seront écrits comme étant d’environ 1,8B, il est recommandé de se référer à l’étiquetage des cartes d’entrepôt et de modèle).
3. 10 Prise en charge des langues : chinois, anglais, japonais, coréen, allemand, français, russe, portugais, espagnol, italien, et fournir plusieurs dialectes/configurations de timbre.
4. Tokenizer 12Hz haute compression : exprime la parole à une fréquence de jeton plus basse, réduit la bande passante et la charge d’inférence, et convient à la synthèse en streaming et hors ligne.
5. Contrôlable et robuste : Soutenir l’utilisation de commandes en langage naturel pour contrôler la vitesse de la parole, l’émotion, la prosodie, etc., améliorant la stabilité pour le texte bruyant et les entrées complexes.
6. Parcours complet de fin-tuning : L’entrepôt fournit des catalogues et exemples liés à l’ajustement fin, ce qui est pratique pour le corpus industriel, le timbre de marque ou une adaptation spécifique d’accent.
3. Installation
- Environnement Python : Il est recommandé de créer un nouvel environnement virtuel Python 3.12.
2. Installation en un clic : Installer directement le paquet PyPI qwen-tts ; Si des modifications locales sont nécessaires, clonez le dépôt et pip install -e .-le.
- Optimisation des ressources : La recommandation officielle est d’installer FlashAttention 2 pour réduire la consommation de mémoire. Les poids peuvent également être pré-téléchargés localement via Hugging Face / ModelScope.
4. Cas d’usage typiques
- Voix produit/service client : diffusion en streaming à faible latence, adaptée aux assistants conversationnels et à l’interprétation simultanée en temps réel.
- Création de contenu et doublage : Utilisez des commandes pour contrôler les émotions et la vitesse de la parole afin de générer une narration multi-style.
- Voix personnalisée : 3 secondes d’audio de référence pour le clonage de timbre, utilisé comme assistant personnel ou lecture sans barrières (autorisation requise).
- Jeux et humains virtuels : VoiceDesign génère rapidement des timbres de personnages via des descriptions textuelles, puis superpose des contrôles de style.
- Ajustement fin de l’industrie : Utiliser son propre corpus pour un réglage complet afin d’améliorer la lecture terminologique, la cohérence des accents et la stabilité du timbre de la marque.
5. Écologie et produits concurrents
- Écosystème : Fournir une collection de modèles Face/ModelScope et une démonstration en ligne ; Prend en charge nativement le lancement de l’interface Web ; En même temps, fournir la documentation API liée à DashScope/Model Studio ; Et il a mentionné la direction d’intégration de vLLM-Omni.
- Produits concurrents : Les solutions courantes côté open source incluent Coqui TTS, Bark, XTTS, StyleTTS2, etc., axées sur le multilinguisme, la qualité des clones, la contrôlabilité et les coûts de déploiement. La différence entre Qwen3-TTS est davantage axée sur l’intégration de « conception vocale + clonage + streaming basse latence + tokeniseur à haute compression 12Hz + liaison fine tuning ».
6. Limitations et précautions
- Puissance de calcul et mémoire vidéo : Les modèles plus grands et la sortie de haute qualité consomment généralement plus de GPU ; Les services de streaming doivent également prêter attention à la concurrence et au saut de latence.
- Conformité au timbre : Le clonage de timbre et l’onomatopée peuvent impliquer des droits de portrait/droits sonores et la conformité au contenu, il faut donc obtenir une autorisation et bien gérer les limites d’utilisation.
- Frontière de qualité : Des écarts de prononciation et une instabilité de prosodie peuvent encore apparaître dans différentes langues, accents, émotions extrêmes ou textes ultra-longs, il est donc recommandé d’ajouter un échantillonnage manuel et un post-traitement.
- Déploiement en production : Les permissions de microphone du navigateur, HTTPS, passerelle et configuration des certificats affecteront la disponibilité de la démo/service et devront être gérées conformément aux instructions officielles.
7. Adresse du projet
https://github.com/QwenLM/Qwen3-TTS
8. Questions fréquemment posées
Q : Quelles langues et quelles voix prend en charge Qwen3-TTS ?
R : 10 langues sont couvertes et plusieurs configurations dialectales/timbres sont disponibles ; Les détails spécifiques dépendent de la carte modèle et de la description de l’entrepôt.
Q : Quelle est la différence entre VoiceDesign et Voice Clone de Qwen3-TTS ?
R : VoiceDesign décrit la « conception » d’un nouveau son en mots ; Voice Clone reproduit le timbre du haut-parleur cible avec un son de référence court, comme 3 secondes.
Q : Quelle est la valeur du tokeniseur Qwen3-TTS 12Hz ?
R : L’expression des jetons vocaux à basse fréquence peut entraîner une compression plus élevée et un potentiel de latence plus faible, adaptés à la synthèse en temps réel en streaming et au contrôle des coûts.
Q : Qwen3-TTS peut-il être un ajustement fin ?
R : Oui, l’entrepôt propose des processus de réglage fin du code et des échantillons, ce qui convient à l’adaptation du corpus industriel et du ton de la marque.
Q : Comment Qwen3-TTS expérimente-t-il rapidement la démo ?
R : Vous pouvez utiliser la démo en ligne de Hugging Face/ModelScope, ou lancer la commande web officielle après l’avoir installée qwen-tts localement pour en profiter.



