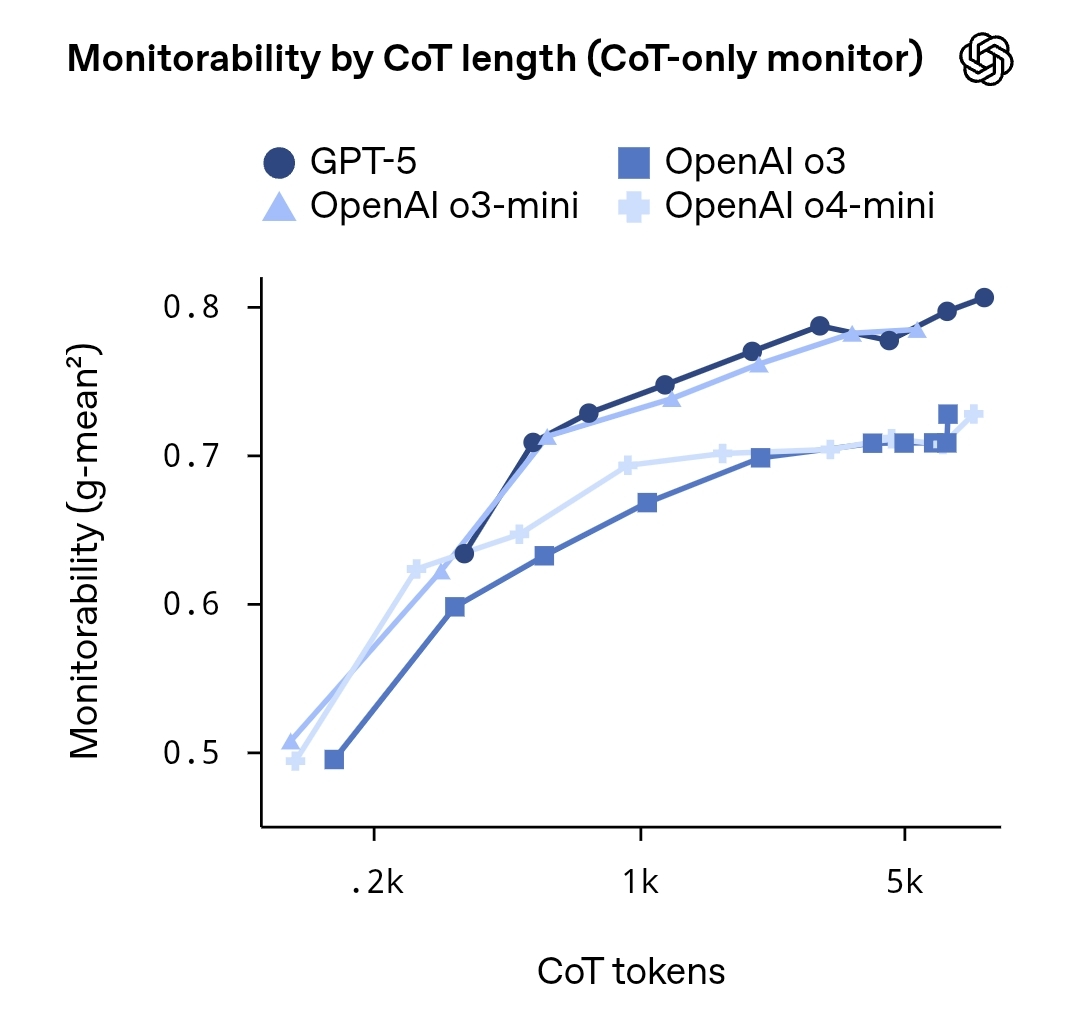
OpenAI a publié un rapport de recherche intitulé « Evaluating Chain-of-Thought Monitorability », qui évalue systématiquement la surveillabilité et l’impact sur la sécurité de la « Chain-of-Thought » (CoT) au sein de grands modèles de langage. Le rapport a souligné que, bien que le processus de raisonnement généré par le modèle puisse être prédit dans une certaine mesure par des incitations externes ou des modèles proxy, sa trajectoire de pensée complète et précise reste très incertaine et inreproductible.
L’équipe de recherche a utilisé différentes tailles de modèles et types de tâches dans de multiples expériences pour analyser comment évaluer la transparence et l’auditabilité de la chaîne de pensée du modèle via le « suivi par proxy model » et les « étapes de raisonnement par étiquetage implicite ». Les résultats montrent que les cibles d’inférence de haut niveau peuvent être partiellement surveillées, mais il existe toujours un risque d’aléa et de fuite d’informations sensibles dans les détails. Le rapport recommande de maintenir un équilibre entre sécurité et confidentialité, et à l’avenir, l’IA pourra être améliorée dans des scénarios critiques grâce à des mécanismes de supervision spécifiques, un raisonnement à sable et des cadres d’annotation explicative.
OpenAI a souligné à la fin de l’article que l’étude vise à fournir des références techniques pour la gouvernance de l’IA, l’audit des risques et la sécurité de la recherche scientifique, et ne signifie pas que le modèle public actuel possède ou expose une « chaîne de pensée complète » interne. Les recherches ultérieures porteront sur la manière d’améliorer la transparence des inférences et la vérification des processus sans affecter la performance du modèle.
FAQ Q : Quel est le sujet de cette étude ?
R : La recherche explore principalement si la « chaîne de pensée » dans les grands modèles de langage peut être surveillée, interprétée ou partiellement prédite, ainsi que les implications sécuritaires de cette visibilité.
Q : Qu’est-ce qu’une « chaîne de pensée » ?
R : Fait référence aux étapes de raisonnement intermédiaires ou processus logiques du modèle avant de générer les réponses, qui ne sont généralement pas visibles dans la sortie mais affectent le résultat final.
Q : Quelles sont les principales conclusions tirées de l’étude ?
R : Les chaînes de pensée peuvent être partiellement prédites, mais elles ne peuvent pas être entièrement reproductibles, et il existe des risques d’aléatoire, de vie privée et d’abus.
Q : Pourquoi étudier la surveillabilité des chaînes de pensée ?
R : Afin d’améliorer la sécurité et l’auditabilité des systèmes d’IA, les chercheurs peuvent mieux comprendre le comportement de raisonnement des modèles dans des tâches critiques.
Q : La recherche signifie-t-elle qu’OpenAI a révélé ses mécanismes de raisonnement internes ?
R : Non. Le rapport est uniquement destiné à l’évaluation académique et à la référence en gouvernance de la sécurité, et ne divulgue aucune interface ou fonctionnalité pouvant accéder à l’inférence interne du modèle.