I. 초록
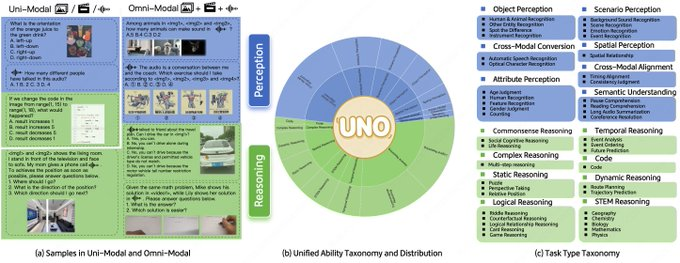
UNO-Bench는 지각과 추론 차원을 모두 포괄하는 "단일 모델/전체 모델" 문제의 통합 평가를 위한 오픈소스 벤치마크입니다. 중국어 실제 상황 문제와 다단계 주관식 질의응답(MO) 문제를 제공합니다. 데이터와 도구는 고품질의 인간 주도적 구성을 강조하며, 자동 평가를 위한 일반 채점 모델을 갖추고 있습니다.
II. 핵심 기능
- 통합 역량 프레임워크: 44가지 유형의 작업, 5가지 모달 조합, 단일 모달 및 전체 모달 작업에 대해 동일한 지표 수준을 제공합니다.
- 높은 품질과 해결 가능성: 1,250개의 전체 모달 데이터 포인트, 사람이 검토한 구조, 모달리티 전반에 걸쳐 98% 해결 가능.
- 효율성 최적화: 18개의 공개 벤치마크를 자동으로 압축하여 평가 속도를 약 90% 높이고 일관성을 약 98% 향상시킵니다.
- 더욱 현실적인 질문 유형: 복잡한 추론 과정을 포괄하기 위해 여러 단계로 구성된 개방형 질문과 답변이 추가되었습니다.
- 일반 채점: OOD 시나리오에서 약 95%의 주석 일관성을 갖춘 6가지 유형의 질문을 지원합니다.
- 주요 결과: 강력한 모델은 "멱수 법칙 시너지"(능력은 모달 조합에 따라 곱셈적으로 증가)를 보입니다.
III. 설치
1. 데이터 세트: datasets.load_dataset("meituan-longcat/UNO-Bench") 기본 샤드를 검색합니다.
- 소스 코드 및 문서: 복제된 GitHub 저장소에서 README 및 평가 스크립트 예를 확인하세요.
- 환경: Python/Transformers/Datasets. 표준 환경이면 충분합니다. 저장소 지침에 따라 종속성을 설치하세요.
IV. 일반적인 사용 사례
- 모델 횡단면 평가: 통합된 척도에서 단일 모델과 전체 모델 간의 차이점을 비교합니다.
- 중국 시나리오 검증: 실제/문화/사회적 맥락에서의 지각 및 추론 능력.
- 추론 사슬 분석: 다단계 개방형 질문에 대한 답변을 사용하여 긴 사슬 추론의 약점을 진단합니다.
- RAG/멀티모달 시스템: 오디오, 이미지, 비디오 융합의 전반적인 이점을 검증합니다.
V. 생태학과 경쟁자들
- 생태계: 데이터 세트, 리더보드, 논문을 제공하며, 툴체인은 개발 중입니다.
- 경쟁 제품: MMBEC, MMMU, MathVista와 같은 시각/과목별 벤치마크와 비교했을 때, UNO-Bench는 "단일 모드에서 전체 모드까지의 통합 평가"와 실제 중국어 시나리오를 강조합니다. 또한, 압축 방식을 통해 여러 벤치마크를 빠르게 정렬할 수 있습니다.
VI. 제한 사항 및 주의사항
- 자동 압축의 적용 가능성은 작업별로 검증해야 합니다. 일부 하위 작업에는 충분한 정보가 없을 수 있습니다.
- 일반적인 채점 모델은 긴 답변이나 생성 출력에 대해 여전히 편향이 있을 수 있으므로 샘플을 수동으로 검토하는 것이 좋습니다.
- 현재는 중국어 시나리오에 중점을 두고 있으며, 다국어 확장 및 영어 버전에 대한 협업도 계속 모색하고 있습니다.
- "멱수 법칙 시너지"는 경험적 발견이며, 새로운 작업에 적용할 때 재검증이 필요합니다.
VII. 프로젝트 주소
https://github.com/meituan-longcat/UNO-벤치
VIII. 자주 묻는 질문
질문: UNO-Bench는 어떤 양식과 업무를 다루나요?
A: 오디오, 이미지, 비디오의 조합을 포괄하며, 총 5가지 모달 조합과 44가지 유형의 과제를 포함하고 있으며, 지각과 추론 차원을 모두 타겟으로 합니다.
질문: UNO-Bench 벤치마크를 빠르게 실행하려면 어떻게 해야 하나요?
답변: Hugging Face를 통해 데이터를 로드하고, 저장소의 샘플 스크립트와 일반 스코어링 모델을 사용하여 추론과 스코어링을 수행합니다.
질문: 자동 압축은 결과의 신뢰도에 얼마나 영향을 미치나요?
답변: 18개의 공개적으로 사용 가능한 벤치마크에서 순위 일관성은 약 98%로 유지되지만, 여전히 이것을 원래 세트의 샘플링과 결합하는 것이 좋습니다.
질문: 영어나 여러 언어를 지원하나요?
A: 현재 공식적으로는 중국어 버전에 집중하고 있으며, 영어와 다국어 버전을 공동으로 개발할 파트너를 찾고 있습니다.
질문: 거듭제곱 법칙 협업은 모든 모델에 적용됩니까?
A: 주로 강력한 모델에서 의미가 있고, 약한 모델에서는 "가장 약한 고리 효과"와 유사하며 구체적으로 평가하고 확인할 필요가 있습니다.