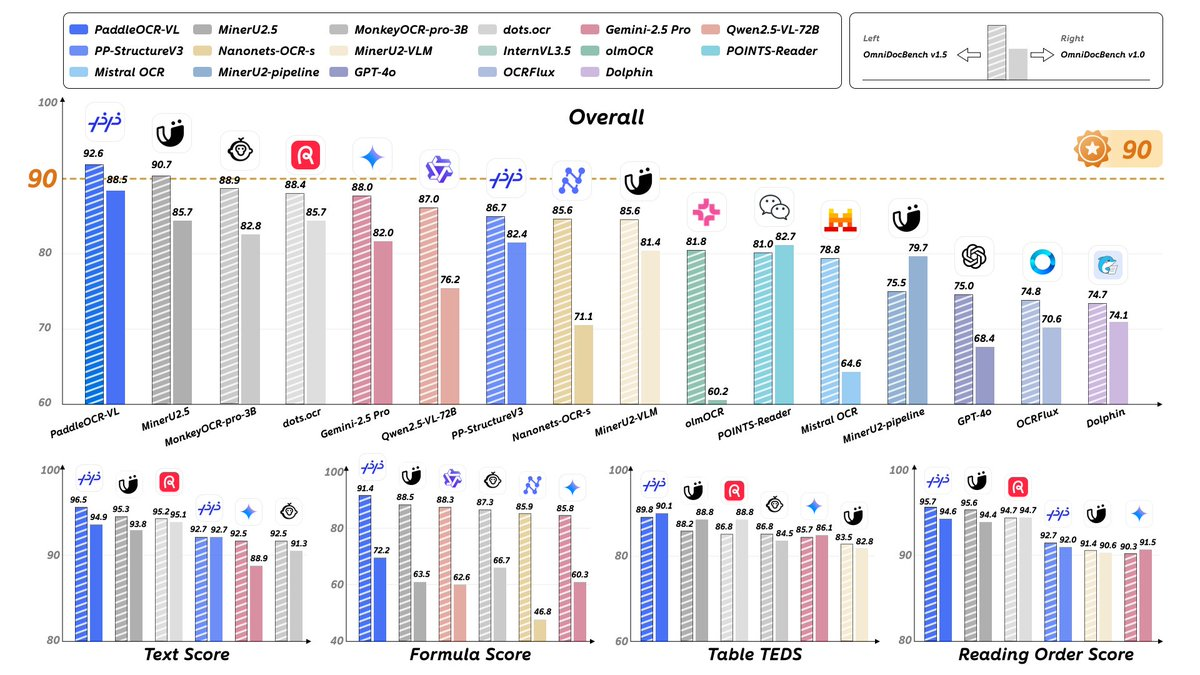
2025 年 10 月 16 日,PaddleOCR 宣布推出多模态文档解析模型 PaddleOCR-VL,并在 3.3.0 版本中作为核心能力上线。该模型规模约 0.9B,采用 NaViT 风格的动态分辨率视觉编码器,结合 ERNIE-4.5-0.3B 语言模型,实现对文本、表格、公式、图表与手写体等要素的统一识别与结构化输出。官方在 OmniDocBench 等公开与自建数据集上的评测显示,PaddleOCR-VL 在页级解析与要素级识别均达到或刷新 SOTA。
在多语言方面,PaddleOCR-VL 宣称覆盖 109 种语言与多脚本场景,适配中文、英文、日文、拉丁及阿拉伯、斯拉夫、西里尔、天城文等体系,面向实际生产的推理效率做了优化,可与 PaddleOCR 的 PP-StructureV3、PP-OCRv5 等组件协同使用。模型与文档已在 GitHub、HuggingFace 与官方文档同步上线;具体基准、可视化样例与部署方式以官方页面为准,后续细节如数据集版本与评测范围更新需关注仓库动态。
常见问题
Q:PaddleOCR-VL 是什么?
A:一个约 0.9B 参数的视觉语言模型,用于端到端文档解析,可同时处理文本、表格、公式、图表与手写体,并输出结构化结果。
Q:它为何被称为“超小型”?
A:在多模态 VLM 中,0.9B 规模相对小而推理高效;通过 NaViT 动态分辨率与 ERNIE-4.5-0.3B 的组合,在保持精度的同时降低算力需求。
Q:是否真的达到 SOTA?
A:官方在 OmniDocBench v1.5/v1.0 等基准及自建集展示了领先结果,涵盖整体、阅读顺序、表格、公式等多项指标;结论以公开报告与模型卡给出的图表与说明为依据。
Q:支持哪些语言与应用场景?
A:覆盖 109 种语言,适用于多脚本混排、历史文档与复杂版面等场景,可与 PP-StructureV3 的版面/表格结构化能力联动,用于真实业务解析。
Q:在哪里获取与如何试用?
A:GitHub 提供版本说明与命令行/Python API;HuggingFace 提供模型卡与在线 Demo 链接;文档站点给出部署与加速(如 vLLM/sglang 服务端)指南。