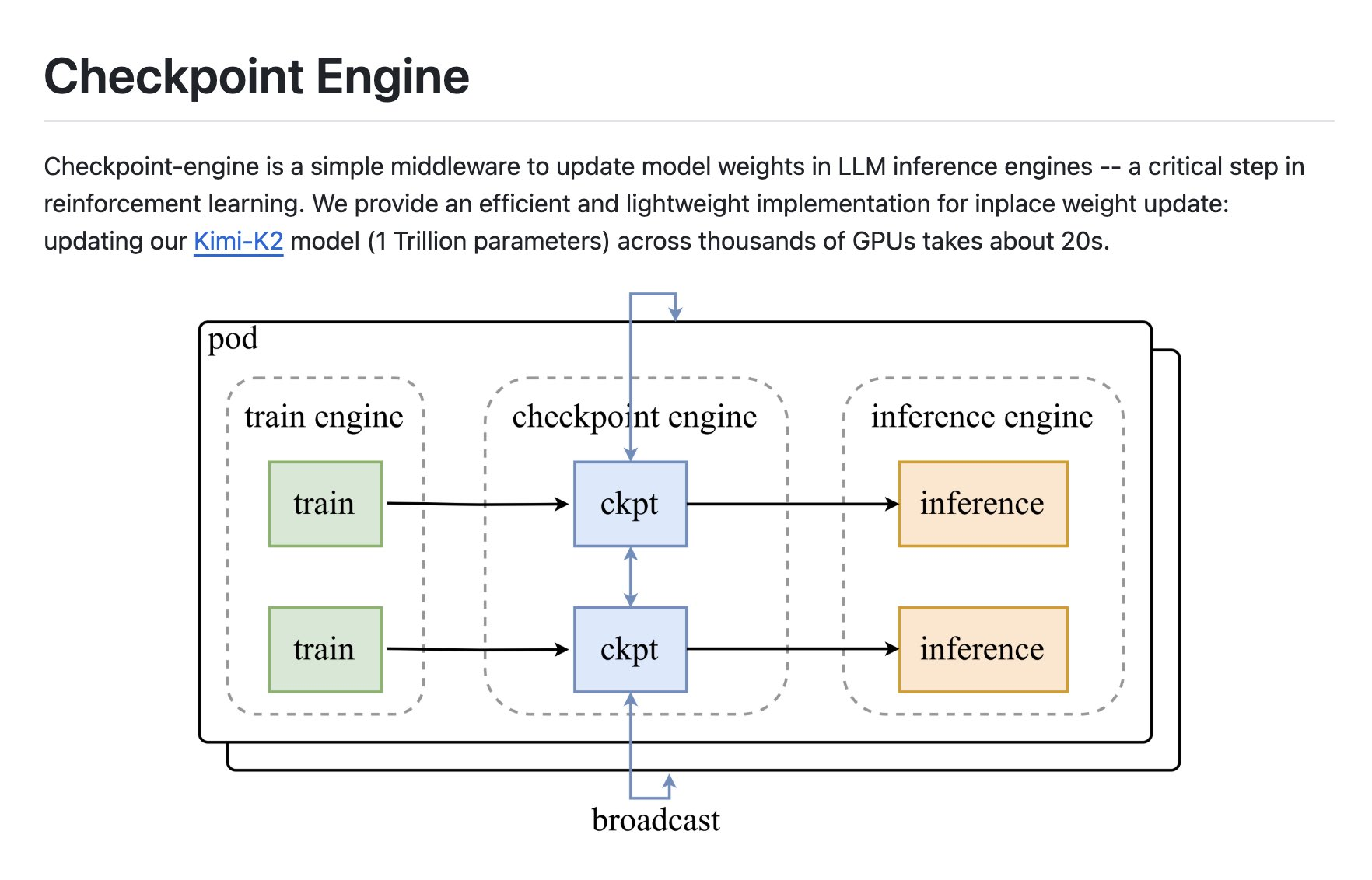
RL と大規模な LLM 推論のニーズに合わせて、checkpoint-engine は「インプレース重み更新」を実装し、ブロードキャスト同期と P2P 動的ルーティングをサポートし、通信とコピーの重複の最適化を組み合わせた軽量ミドルウェアです。 何千ものGPUクラスターで、1Tモデルの重みの更新を約20秒で完了できるため、RLポリシーがオンライン推論サービスへのループを迅速に閉じることができます。
1. それは何であり、どのような問題を解決しますか1
. RL を短縮するための更新 閉ループ
チェックポイント エンジンは、LLM 推論プロセス中にローカルの重みの更新を完了し、再起動と完全なリロードを回避します。 RL ループの場合、checkpoint-engine を使用すると、新しいポリシーをトレーニング側からオンライン推論側にすばやく同期できるため、「ビルド フィードバック - 更新」の待機時間が短縮されます。
2. デュアルチャネル配信: ブロードキャストと P2P
チェックポイント エンジンは、ブロードキャスト同期更新と P2P ダイナミック トポロジの両方をサポートします。 異なるコンピュータールームとネットワーク条件を柔軟に切り替えて、大規模モデルのマルチコピーの一貫性のコストを削減できます。
3. 軽量でスケーラブル
推論エンジンのバイパス ミドルウェアとして、チェックポイント エンジンは最小限の侵入で既存のサービスに接続します。 大規模な展開のためのパイプライン更新を提供し、主流の分散セグメンテーションソリューションと互換性があります。
2. なぜ速いのか、エンジニアリングのポイント1
. 通信とコピーの重複
チェックポイントエンジン更新パイプラインでは、通信とメモリコピーが並行して実行され、アイドル待機が減ります。 ストリームレベルのスケジューリングにより、重みをそのまま使用できるため、全体的なスループットが向上します。
2. オンデマンドの粒度とルーティングの最適化
RL 反復は通常、一部の重みまたは適応層のみを更新し、checkpoint-engine はチャンクと増分ルーティングをサポートし、クロスノード処理の量を削減し、1T レベルのモデルの更新時間をさらに圧縮します。
3. 安定性とロールバック
チェックポイント エンジンにはデフォルトでバージョンと検証があり、障害が発生した場合に古いバージョンをメモリ内でウォームアップし、迅速にロールバックし、オンライン推論の SLA を確保します。
3. 使用方法、実装するための 3 つのステップ
1. アクセス シナリオ
(1) RL 機能強化の微調整: 小さなステップで頻繁にポリシーを更新
する(2) オンライン A/B: 特定のテナントまたはトラフィックのグレースケール更新
(3) 混合負荷: オフライン バッチとオンライン要求が共存
する2. 展開プロセス
(1) 推論側でチェックポイントエンジンプロキシをロード
する(2) トレーニング側で重みブロックとメタデータインデックスを出力
する(3) ブロードキャストまたはP2Pルートを選択し、重複複製を有効にして検証を監視
する3. ガバナンスと観察
(1) 重み変更ごとにバージョン、ハッシュ、時間消費を記録
する(2) 同時実行とスロットリングのしきい値を設定してサービスの遅延を保護する
(3) テナントとモデル ドメインに応じて予算と頻度の制限を設
4. 比較と選択の提案
1. 従来の再起動/フル リロード
チェックポイント エンジンと比較して、ダウンタイムを第 2 レベルに短縮します。、これは高同時実行およびマルチレプリカクラスターに適しています。
2. VS純粋なパラメータサーバー
パラメータサーバーは、トレーニング側の勾配同期に焦点を当てています。 checkpoint-engine は、推論側の重み配分と in-situ 置換に重点を置いており、RL のオンラインとオフラインのハイブリッド閉ループにより適しています。
3. 最初に使用するタイミング
RL が頻繁に更新され、多数のモデルがあり、クラスター サイズが大きく、「無停止のオンボーディング」がハード インジケーターである場合は、チェックポイント エンジンが推奨されます。
よくある質問 (Q&A)
Q: CHECKPOINT-ENGINE は RL シーンの高速化にどのように役立ちますか?
A: LLM 推論側のインプレース重みを更新し、新しい RL 戦略をほぼ「瞬時に」アップロードし、トレーニングからサービスまでの閉ループ時間を大幅に短縮します。
Q: ブロードキャストと P2P のどちらを選択するにはどうすればよいですか?
A: 小規模または同種のネットワークは放送を好みます。 ラック/データセンターや複雑なトポロジーをまたいでP2Pダイナミックルーティングを選択し、重複するコピーを組み合わせて、より安定したスループットを実現します。
Q: 1T モデルは 20 秒のアップデートにどのような前提条件に依存していますか?
A: チャンクの増分、通信とコピーの重複、効率的なルーティングに依存します。 スケールは、数千のGPUの大規模なクラスターでより顕著であり、これは実際にはネットワークとセグメンテーション戦略に依存します。
Q: checkpoint-engine は既存の推論エンジンと互換性がありますか?
A: 軽量のミドルウェアとして、ビジネス ロジックを変更することなく、主流の分散推論スタックにアクセスできます。 安全なロールバックとグレースケールは、バージョン管理と検証によって実現されます。