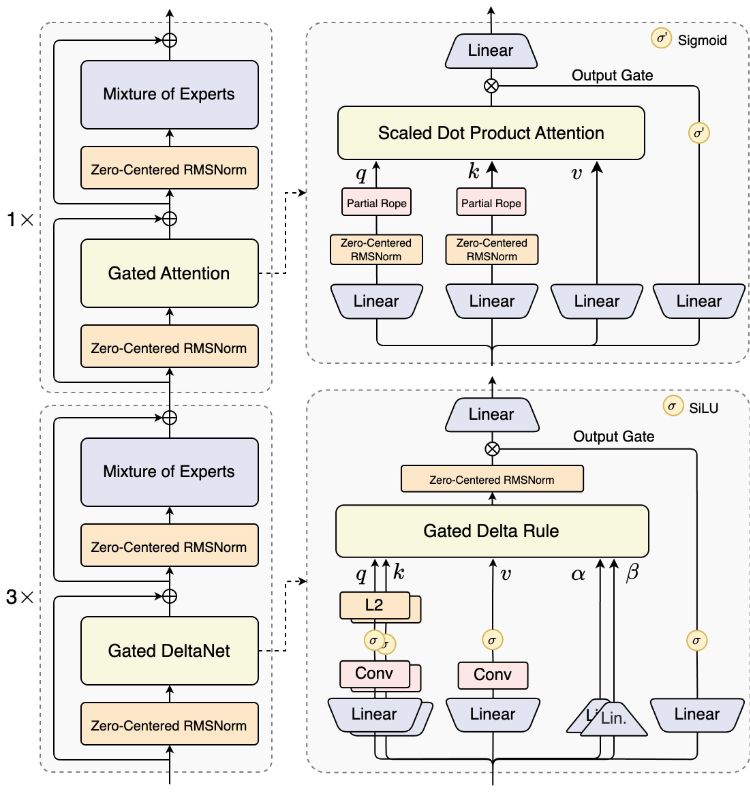
Qwen3-Next-80B-A3B konzentriert sich auf 80 Mrd. Gesamtparameter, nur 3 Mrd. Aktivierung pro Token, verwendet eine Hybrid-Architektur (Gated DeltaNet + Gated Attention), Ultra-spärliches MoE (512 Experten, 10 Routen + 1 Sharing) und Multi-Token-Vorhersage Denkende Version.
1. Schnelle Zusammenfassung
1. Kernparameter und Positionierung
Qwen3-Next-80B-A3B gleicht die Kapazität des großen Modells an den 80B-Parametern aus, erreicht aber durch 3B-Aktivierung ein extrem spärliches MoE; Für lange Kontexte über 32 KB liegt der Schwerpunkt auf einem hohen Durchsatz und einer geringen Latenz, wodurch es sich für die Verbesserung des Abrufs und Workflows mit mehreren Dokumenten eignet.
2. Highlights der Architektur
Die Hybridlösung führt Gated DeltaNet und Gated Attention ein und wählt 10+1 unter 512 Experten mit Routing-Gating aus. MTP-Multi-Token-Vorhersage und Spekulationsdekodierung der Verknüpfung zur Verbesserung der Erzeugungseffizienz und -stabilität. Die A3B-Route sichert die Wirtschaftlichkeit von "großem allgemeinem Personal und kleiner Aktivierung".
3. Leistungs-Benchmarking
Das offizielle Kaliber sagte, dass die Trainingskosten etwa eine Größenordnung niedriger sind als die von Qwen3-32B, und der Inferenzdurchsatz von 32K+-Szenen deutlich verbessert wird; Instruct steht dem 235B-Flaggschiff nahe, und die Thinking-Version vergleicht das Mainstream-Chain-of-Thought-Modell in Bezug auf Inferenz und lange Kontexte.
2. Implementierung und Verwendung
1. Szenarien mit hohem Wert
(1) RAG für lange Dokumente und Fragen und Antworten: Verlassen Sie sich auf langen Kontext und hohen Durchsatz, um große Wissensblöcke zu verarbeiten
(2) Multi-Round-Business-Assistent: dateiübergreifende Anweisungen, Tabellen und Code-gemischte Aufgaben
(3) Batch-Verarbeitung und Offline-Generierung: MTP Optimieren Sie Durchsatz und Kosten mit spärlichen Routen
2. Bereitstellungs- und Optimierungsvorschläge
(1) KV-Cache-Tiering und parallele Batch-Verarbeitung, wobei die Optimierung von 32K/64K-Geräten im Vordergrund steht
(2) Parallele Tensorsegmentierung nach Experten-Routing zur Reduzierung von Bandbreiten-Hotspots
(3) Prompt Word Tracking: Abruf-, Code- und Gedankenkettenvorlagen werden getrennt gepflegt
3. Checkliste für Migration und Evaluierung
(1) Erstellen einer Qwen3-32B/Qwen3-235B-Baseline und Vereinheitlichen des Evaluierungsskripts
(2) Messen von Qualität, Durchsatz und Kosten in drei Dimensionen; Erfassen Sie die Auswirkungen der Kontextlänge auf die Leistung
(3) Graustufenersetzung: Wechseln Sie zunächst zwischen Szenarien mit hoher Parallelität in langen Kontexten und decken Sie dann schrittweise den allgemeinen Dialog
ab 3. Risikokontrolle und Compliance
1. Kosten und Quoten
(1) Legen Sie Anrufkontingente und Budgetalarme entsprechend Mietern und Projekten
fest (2) Ändern Sie große Batch-Aufgaben in Offline-Batch-Verarbeitung, um den Spitzen-Overhead zu reduzieren
(3) Überwachen Sie die Trefferquote von Token/KV pro Anforderung, um implizite Verschwendung zu vermeiden
2. Beobachtbarkeit und Qualitätsregression
(1) Erzwingen Sie die Beibehaltung von Gedankenketten und Zusammenfassungen von Zitationsbeweisen
(2) Aktivieren Sie manuelles Sampling und Rollback für Schlüsselkanäle
(3) Versionssperre: Modell, 3
. Lizenzierung und Datensicherheit
(1) Befolgen Sie Modellgewichtungen und API-Lizenzbedingungen
(2) Greifen Sie mit den geringsten Rechten auf Unternehmensdaten zu und aktivieren Sie Überwachungsprotokolle
(3) Konfigurieren Sie die Filterung und manuelle Überprüfung
Häufig gestellte Fragen (Q&A)
F: Was sind die Vorteile von Qwen3-Next-80B-A3B's A3B und Ultra-Sparse MoE?
A: A3B ermöglicht es dem allgemeinen Personal von 80B, mit nur 3B-Aktivierung an der Vorwärtsbewegung teilzunehmen, und mit dem 512 Expert 10+1-Routing wird ein höherer Durchsatz und eine niedrigere Abrechnung erreicht, was für KI-Workloads in 32K+ langen Kontexten und Batch-Verarbeitungsszenarien geeignet ist.
F: Wie wähle ich das Modell mit Qwen3-32B und Qwen3-235B aus?
A: Auf der Suche nach Kosteneffizienz und Effizienz im langen Kontext wählen Sie Qwen3-Next-80B-A3B. Flaggschiff-Anforderungen, die absolute Spitzenqualität und maximalen Kontext erfordern, werden vor dem 235B berücksichtigt; Die Produktionslinie mit stabilem Lagerbestand kann vorübergehend bei 32 B als Kontrollbasis beibehalten werden.
F: Wie funktionieren Multi-Token-Vorhersage und spekulative Dekodierung im Engineering?
A: Verwenden Sie nach dem Aktivieren von MTP ein großes paralleles Dekodierungsfenster und überwachen Sie die Ablehnungsrate. In Kombination mit spekulativer Dekodierung kann die tatsächliche Latenz weiter reduziert werden, aber die Auswirkungen verschiedener Aufgaben auf die Qualität müssen beachtet werden.
F: Was ist der Unterschied zwischen den Versionen Instruct und Thinking?
A: Instruct orientiert sich an der Einhaltung von Anweisungen und allgemeinen Aufgaben; Denken stärkt die Denk- und Argumentationskette, macht sie stabiler in der Planung und Werkzeugnutzung und eignet sich besser für komplexe Retrieval- und Long-Link-Aufgaben.