Qwen3-Next-80B-A3B se concentre sur 80B de paramètres totaux, seulement 3B d’activation par token, adopte une architecture hybride (Gated DeltaNet + Gated Attention), un MoE ultra-clairsemé (512 experts, 10 routes + 1 partage) et une prédiction multi-token Version pensante.
1. Résumé rapide
1. Paramètres de base et positionnement
Qwen3-Next-80B-A3B aligne la grande capacité du modèle avec les paramètres 80B, mais atteint un MoE extrêmement clairsemé grâce à l’activation 3B ; Pour les contextes longs supérieurs à 32K, il met l’accent sur un débit élevé et une faible latence, ce qui le rend adapté à l’amélioration de la récupération et aux flux de travail multi-documents.
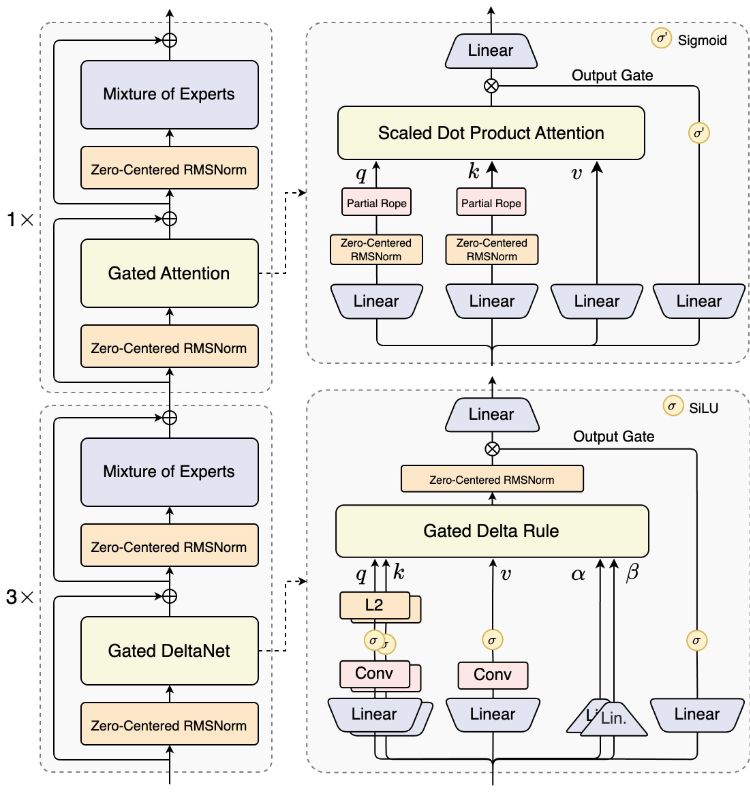
2. Points forts de l’architecture
La solution hybride introduit Gated DeltaNet et Gated Attention, et sélectionne 10+1 parmi 512 experts avec un contrôle de routage. Liaison de prédiction et de décodage de spéculation multi-tokens MTP pour améliorer l’efficacité et la stabilité de la production. La voie A3B garantit la rentabilité d’un « grand état-major et d’une petite activation ».
3. Analyse comparative des performances
Le calibre officiel a déclaré que le coût de la formation est inférieur d’environ un ordre de grandeur à celui du Qwen3-32B, et que le débit d’inférence des scènes 32K+ est considérablement amélioré ; Instruct est proche du produit phare 235B, et la version Thinking compare le modèle traditionnel de la chaîne de pensée dans des contextes d’inférence et de long.
2. Mise en œuvre et utilisation
1. Scénarios à forte valeur ajoutée
(1) RAG de documents longs et questions-réponses de récupération : s’appuyer sur un contexte long et un débit élevé pour traiter de grands blocs de connaissances
(2) Assistant commercial multi-tours : instructions inter-fichiers, tables et tâches mixtes de code
(3) Traitement par lots et génération hors ligne : MTP Optimiser le débit et les coûts avec des routes clairsemées
2. Suggestions de déploiement et de réglage
(1) Hiérarchisation KV-Cache et traitement par lots parallèles, en donnant la priorité à l’optimisation des engrenages 32K/64K
(2) Segmentation tensorielle parallèle selon un routage expert pour réduire les points chauds de bande passante
(3) Suivi rapide des mots : les modèles de récupération, de code et de chaîne de pensée sont conservés séparément
3. Liste de contrôle de migration et d’évaluation
(1) Établir une base de référence Qwen3-32B/Qwen3-235B et unifier le script d’évaluation
(2) Mesurer la qualité, le débit et le coût en trois dimensions, respectivement ; Enregistrer l’impact de la longueur du contexte sur les performances
(3) Remplacement des niveaux de gris : basculez d’abord entre des scénarios à forte simultanéité dans des contextes longs, puis couvrez progressivement le dialogue
3. Contrôle des risques et conformité
1. Coût et quota
(1) Définissez des quotas d’appels et des alarmes budgétaires en fonction des locataires et des projets
(2) Remplacer les tâches par lots volumineux par un traitement par lots hors ligne afin de réduire les pics de surcharge
(3) Surveiller le taux de réussite du jeton/KV par requête pour éviter le gaspillage implicite
2. Observabilité et régression de la qualité
(1) Appliquer la préservation des chaînes de pensée et des résumés de preuves de citation
(2) Activer l’échantillonnage manuel et la restauration pour les canaux clés
(3) Verrouillage de version : modèle, 3
. Licences et sécurité des données
(1) Respectez les poids des modèles et les termes de licence de l’API
(2) Accédez aux données de l’entreprise avec le moindre privilège et activez les journaux d’audit
(3) Configurez le filtrage et l’examen
sensible de sortie Foire aux questions Q
: Quels sont les avantages de l’A3B et du MoE ultra-clairsemé de Qwen3-Next-80B-A3B ?
R : A3B permet à l’état-major général de 80B de participer à l’avancement avec seulement 3B d’activation, et avec le routage 512 experts 10+1, il atteint un débit plus élevé et une facturation plus faible, ce qui convient aux charges de travail d’IA dans des contextes de 32K + et des scénarios de traitement par lots.
Q : Comment choisir le modèle avec Qwen3-32B et Qwen3-235B ?
R : Dans la poursuite de la rentabilité et de l’efficacité à long terme, choisissez Qwen3-Next-80B-A3B ; Les exigences phares qui exigent une qualité de pointe absolue et un contexte maximal sont prises en compte avant le 235B ; La chaîne de production de stock stable peut être temporairement maintenue à 32B comme référence de contrôle.
Q : Comment fonctionnent la prédiction multi-tokens et le décodage spéculatif en ingénierie ?
R : Après avoir activé MTP, utilisez une grande fenêtre de décodage parallèle et surveillez le taux de rejet ; Combiné au décodage spéculatif, la latence réelle peut être encore réduite, mais l’impact des différentes tâches sur la qualité doit être observé.
Q : Quelle est la différence entre les versions Instruct et Thinking ?
A : Instruct est orienté vers la conformité aux instructions et les tâches générales ; La pensée renforce la chaîne de pensée et de raisonnement, ce qui la rend plus stable dans la planification et l’utilisation des outils, et est plus adaptée aux tâches complexes de récupération et de liaison longue.