1. Résumé
Qwen3-ASR et Qwen3-ForcedAligner sont des modèles vocaux open source et des composants d’alignement destinés à des scénarios d’enregistrement « bruyants, complexes et incontrôlables » dans le monde réel. Ils se concentrent sur la reconnaissance automatique multilingue, la robustesse au bruit et à la réverbération, un traitement audio long jusqu’à environ 20 minutes, ainsi que des capacités d’alignement temporel très précis au niveau mot/phrase dans certaines langues, et sont équipés d’une pile d’ingénierie open source pour l’inférence et le réglage fin pour la transcription en lot, le sous-titrage en streaming et les services en ligne.
2. Caractéristiques principales
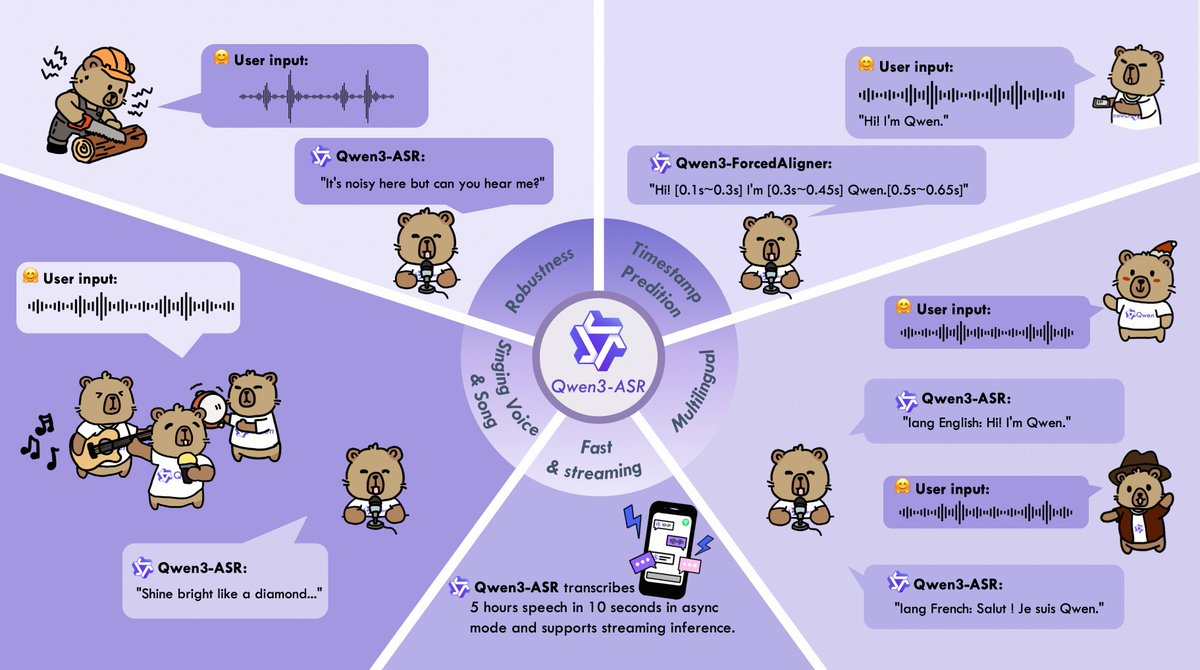
- Reconnaissance linguistique multilingue et automatique : couvre 52 langues et dialectes/accents (30 langues + 22 dialectes/accents), et prend en charge l’identification automatique des langues.
- Robustesse audio complexe : optimisée pour le bruit, les personnes multiples, le champ lointain, la réverbération et d’autres scénarios ; Il aborde également des formes audio plus « atypiques » (comme les voix et les extraits de chansons).
- Prise en charge audio longue : Un seul traitement peut durer jusqu’à environ 20 minutes, réduisant la rupture de contexte et la complexité technique causée par la segmentation longue de l’enregistrement.
- Horodatages au niveau des mots/phrases : Fournir un alignement de haute précision dans 11 langues avec Qwen3-ForcedAligner, ce qui le rend plus convivial pour les sous-titres, la recherche et la révision.
- Pile d’ingénierie : Fournit un système complet et open source d’inférence et d’ajustement fin, incluant des capacités de traitement par lots vLLM, de streaming et de service asynchrone, facilitant la mise en ligne et les tests.
3. Installation
- Obtenir le code : Après avoir cloné le dépôt, appuyez sur le README pour installer les dépendances (il est recommandé d’utiliser un environnement isolé et une version fixe).
- Obtenir les poids : Sélectionnez le modèle et la configuration appropriés depuis Hugging Face ou ModelScope.
- Mode de fonctionnement : Sélectionnez transcription hors ligne par lots (batch), streaming en ligne (streaming) ou service asynchrone (service asynchrone) selon le scénario, et configurez la concurrence et la file d’attente selon le débit.
4. Cas d’usage typiques
- Transcription de centres d’appels/conférences : transcription en série et échantillonnage d’inspection qualité en cas de bruit, d’accent et de multiples haut-parleurs.
- Production de sous-titres et récupération : Utilisez ForcedAligner pour générer des horodatages au niveau des mots/phrases, supporter le « saut de points », surligner le suivi et relire les clips.
- Traitement court de vidéos et de matériel musical : Transcrire et expliquer les contenus contenant de la musique de fond, des extraits de rythme ou de chant évidents.
- Archivage des enregistrements longs : Simplifiez les stratégies de segmentation pour 10 à 20 minutes d’audio, combinées aux horodatages pour localiser rapidement les points clés.
- Mixage edge-to-cloud : L’extrémité edge effectue le prétraitement initial du filtrage ou de la réduction du bruit, et le cloud utilise des services batch/asynchrones pour transcrire et aligner centralement.
5. Écologie et produits concurrents
- Entrée écologique : GitHub fournit du code et des documents papier ; Hugging Face / ModelScope propose des collections de modèles et des démonstrations en ligne pour une évaluation et une intégration faciles.
- Idées de produits concurrentielles : Dans le domaine de l'« alignement fort », les solutions courantes incluent la MFA et les aligneurs basés sur des aligneurs de type CTC/CIF. Qwen3-ForcedAligner est positionné pour optimiser la précision et la stabilité des sous-titres et de la relecture, avec des capacités d’alignement comme composant posable à atterrissage. Il est toujours recommandé d’utiliser son propre jeu de données pour A/B (les différences d’accent, de bruit, de style de parole et de terminologie du domaine influenceront significativement les résultats).
6. Limitations et précautions
- Puissance de calcul et coût : l’audio multilingue, long format et l’alignement haute précision augmentent la latence d’inférence et l’occupation des ressources, et nécessitent une évaluation du débit et une conception d’élasticité élastique.
- Biais de distribution des données : Des accents extrêmes, une forte réverbération, des voix qui se chevauchent, une terminologie de domaine et des langues à faible ressource peuvent encore entraîner des erreurs d’identification ou des dérives temporelles, il est donc recommandé d’introduire une boucle fermée de révision manuelle.
- Stratégie audio longue : Même si un traitement unique de 20 minutes est pris en charge, il est toujours recommandé de combiner segmentation, fenêtres qui se chevauchent et post-traitement sur des séquences ultra-longues pour réduire les erreurs de frontière.
- Plage linguistique de l’alignement : L’alignement haute précision de ForcedAligner met actuellement l’accent sur la couverture de 11 langues ; Le reste des langues peut être recherché avec des horodatages au niveau des phrases ou paragraphes, puis complété selon les besoins.
7. Adresse du projet
https://github.com/QwenLM/Qwen3-ASR
8. Questions fréquemment posées
Q : Qwen3-ASR prend-il en charge l’identification automatique des langues pour 52 langues et dialectes ?
R : Oui, incluant 30 langues et 22 dialectes/accents, et il peut automatiquement reconnaître la langue et transcrire.
Q : Le Qwen3-ASR peut-il gérer des environnements bruyants ou un vrai son avec musique de fond et chant ?
R : L’objectif est d’améliorer la robustesse du bruit et de l’audio complexe, y compris l’adaptation aux morceaux/extraits vocaux, mais il est recommandé d’échantillonner vos images réelles.
Q : Combien de temps le Qwen3-ASR peut-il gérer en une seule session ?
R : Le nominal peut supporter jusqu’à environ 20 minutes/traitement du temps ; Des clips plus longs sont recommandés en combinaison avec la segmentation et les stratégies de fenêtres qui se chevauchent.
Q : Dans quelles langues l’horodatage « au niveau mot/phrase » de Qwen3-ForcedAligner est-il disponible ?
R : L’accent actuel est mis sur la fourniture de capacités d’alignement haute précision dans 11 langues, adaptées au sous-titrage, à la récupération et à la relecture.
Q : Quelle est la valeur de l’aligneur Qwen3-ForcedAligner par rapport aux aligneurs de type MFA/CTC/CIF ?
R : Se concentrer sur la transformation des capacités d’alignement en composants d’ingénierie directement intégrés, orientés vers la précision et la stabilité des horodatages au niveau des mots/phrases ; Au final, la comparaison de vos données de tâches prévaudra.
Q : Existe-t-il une chaîne d’outils d’inférence et d’ajustement fin prête à la production ?
R : Il fournit une pile open source complète couvrant les services vLLM batch, streaming et asynchrones, et inclut l’ajustement fin des processus associés pour faciliter le déploiement et l’itération.