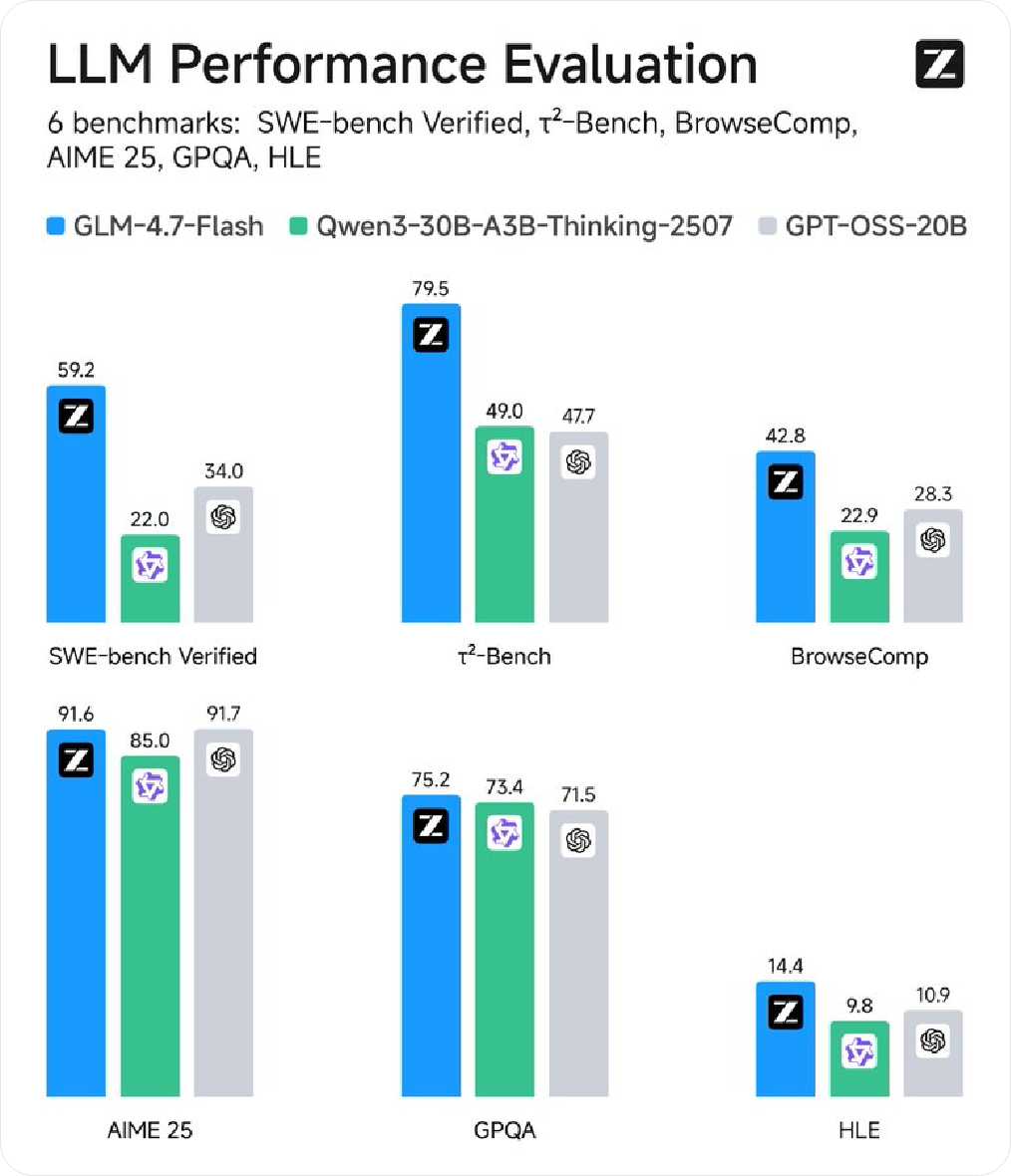
Z.ai verwandten Accounts veröffentlichten Informationen zu X und stellten das neue Modell GLM-4.7-Flash vor, das als "lokaler Codierungs- und Agentenassistent" positioniert ist und betonte, dass es hohe Leistung und Effizienz auf 30B-Ebene ausbalanciert, was es als leichte Bereitstellungsoption geeignet macht. Die Synchronisationsinformationen zeigen, dass Modellgewichte bereits in Hugging Face verfügbar sind und API-Aufrufe über Z.ai unterstützen.
Die offizielle Entwicklerdokumentation beschreibt GLM-4.7-Flash als ein kostenloses Tier-Modell mit einer "1-Nebenwahl"-Begrenzung; GLM-4.7-FlashX ist ebenfalls als optionale Version für "höhere Geschwindigkeit und wirtschaftlicher" erhältlich. Neben der Programmierung schlägt die öffentliche Einführung auch vor, dass es in Szenarien wie kreativem Schreiben, Übersetzung, Aufgaben mit langen Kontexten und Rollenspielen verwendet wird.
Es sollte beachtet werden, dass die tatsächliche Schwelle für das "lokale Ausführen" weiterhin von der Bereitstellungsmethode und den Hardwareressourcen abhängt; Zusätzlich sollten die Nebenläufigkeit der kostenlosen Stufe und die kommerziellen Nutzungsbedingungen auf der neuesten Preis- und Nutzungsseite der Plattform basieren, um zu vermeiden, dass der Demo-Kaliber als universelle Usability-Verpflichtung missverstanden wird.
FAQs
F: Wie ist die Kernpositionierung von GLM-4.7-Flash?
A: GLM-4.7-Flash konzentriert sich auf eine leichte Bereitstellung und konzentriert sich auf lokale Codierungsunterstützung und Agenten-Workflows.
F: Bietet GLM-4.7-Flash Downloads von Modellgewichten?
A: GLM-4.7-Flash-Gewichte sind bereits unter dem zai-org-Konto von Hugging Face verfügbar.
F: Ist die API von GLM-4.7-Flash kostenlos?
A: Die Z.ai-Dokumentation bezeichnet GLM-4.7-Flash als kostenlose Stufe, aber das Standardlimit beträgt 1 Nebenläufigkeit.
F: Was ist der Unterschied zwischen GLM-4.7-FlashX und GLM-4.7-Flash?
A: Die öffentliche Erklärung besagt, dass GLM-4.7-FlashX schneller und kostengünstiger ist und sich an höherfrequente Anrufszenarien richtet.
F: Für welche nicht-programmierenden Anwendungen eignet sich GLM-4.7-Flash?
A: Die öffentliche Einführung erwähnt, dass es für kreatives Schreiben, Übersetzen, Aufgaben mit langen Kontexten, Rollenspiele usw. verwendet werden kann.