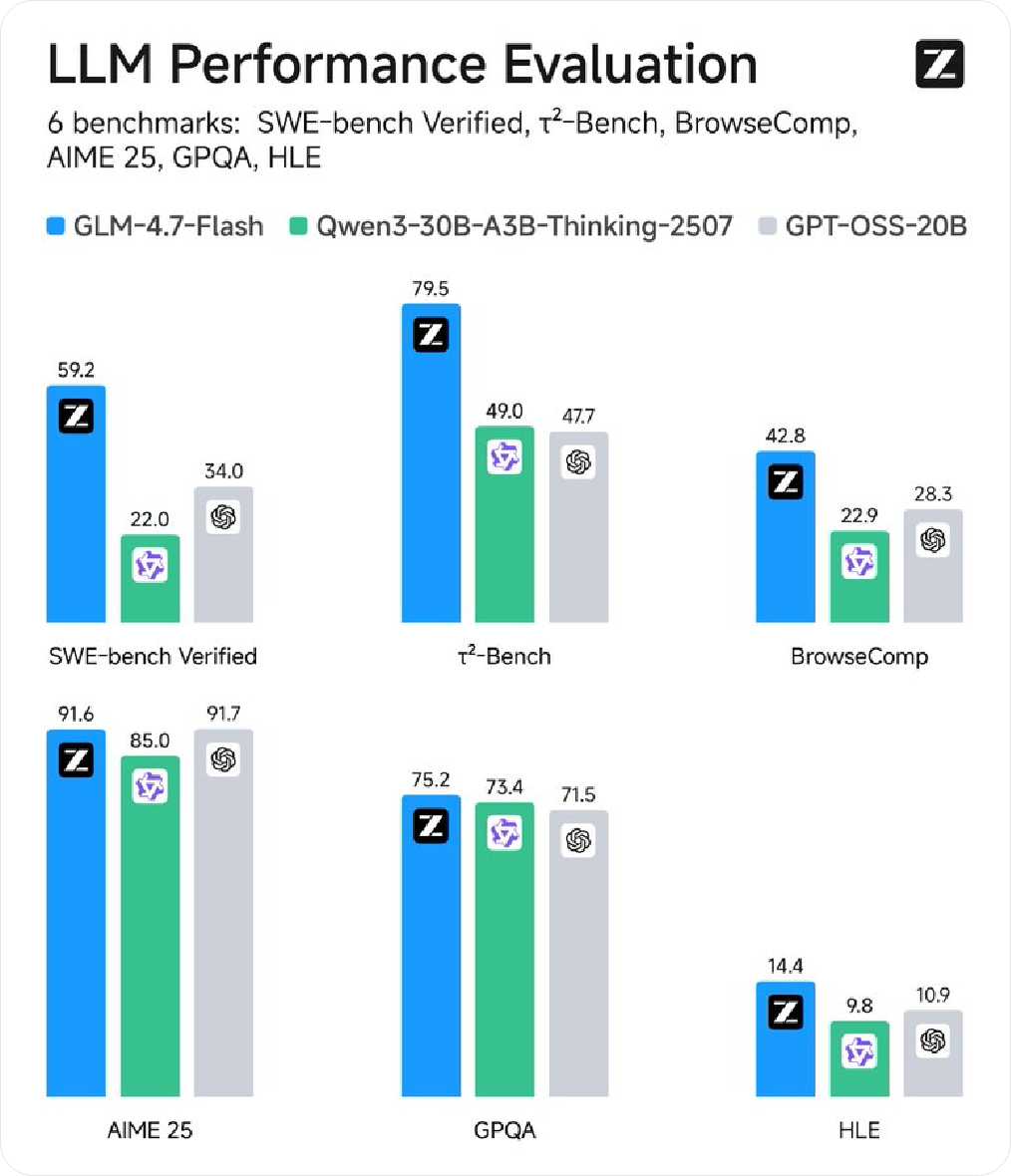
관련 Z.ai 관련 기사들은 X에 관한 정보를 게시하며, "로컬 코딩 및 에이전트 어시스턴트"로 포지셔닝된 새로운 모델 GLM-4.7-Flash를 소개하며, 30B 수준에서 높은 성능과 효율성을 균형 있게 유지하여 경량 배포 옵션으로 적합하다고 강조했습니다. 동기화 정보에 따르면 모델 가중치는 Hugging Face에서 이미 제공되고 Z.ai 를 통한 API 호출도 지원합니다.
공식 개발자 문서에는 GLM-4.7-Flash를 "1 동시성" 제한이 있는 무료 등급 모델로 설명되어 있습니다; GLM-4.7-FlashX는 "더 빠른 속도와 더 경제적"이라는 이유로 선택 사양으로도 제공됩니다. 프로그래밍 외에도, 공개 서문에서는 창작 글쓰기, 번역, 장기 맥락 작업, 역할극 등 다양한 상황에서도 사용할 것을 권장합니다.
"로컬 실행"의 실제 임계값은 배포 방식과 하드웨어 자원에 따라 달라진다는 점에 유의해야 합니다; 또한, 무료 티어 동시성 및 상업용 사용 조건은 플랫폼의 최신 가격 및 이용 약관 페이지를 기준으로 하여 데모 수준을 보편적 사용성 약속으로 오해하지 않도록 해야 합니다.
자주 묻는 질문
Q: GLM-4.7-Flash의 핵심 포지셔닝은 무엇인가요?
A: GLM-4.7-Flash는 경량 배포에 중점을 두며, 로컬 코딩 지원과 에이전트 워크플로우에 중점을 둡니다.
Q: GLM-4.7-Flash가 모델 무게 다운로드를 제공하나요?
A: GLM-4.7-플래시 웨이트는 이미 Hugging Face의 zai-org 계정에서 이용 가능합니다.
Q: GLM-4.7-Flash의 API는 무료인가요?
답변: Z.ai 문서에서는 GLM-4.7-Flash를 무료 등급으로 분류하지만, 기본 동시성 제한은 1회입니다.
Q: GLM-4.7-FlashX와 GLM-4.7-Flash의 차이점은 무엇인가요?
답변: 공개된 설명에 따르면 GLM-4.7-FlashX는 더 빠르고 비용 효율적이며, 고주파 통화 시나리오를 대상으로 한다고 합니다.
Q: GLM-4.7-플래시는 프로그래밍 외 용도에 적합한가요?
A: 공개 서문에서는 창작 글쓰기, 번역, 장기 맥락 작업, 역할극 등에도 사용할 수 있다고 언급되어 있습니다.