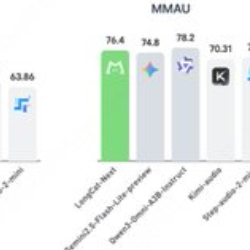
LongCat-Next 开源发布:统一文本、图像与音频的原生多模态模型
一、摘要 LongCat-Next 是美团 LongCat 团队开源的离散原生自回归多模态模型,目标是在同一框架中统一处理文本、视觉与音频。项目采用 MoE 架构,总参数约 68.5B、激活参数约 3B,强调“看、画、说”在单一离散 token 空间内协同完成,面向工业级多模态场景提供理解、生成和交...
Admin •
129
一、摘要 LongCat-Next 是美团 LongCat 团队开源的离散原生自回归多模态模型,目标是在同一框架中统一处理文本、视觉与音频。项目采用 MoE 架构,总参数约 68.5B、激活参数约 3B,强调“看、画、说”在单一离散 token 空间内协同完成,面向工业级多模态场景提供理解、生成和交...
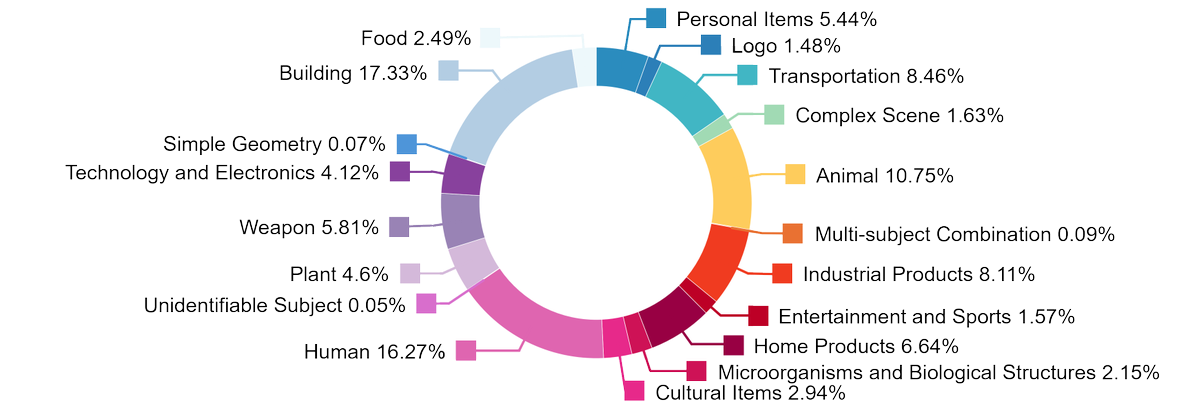
一、摘要 HY3D-Bench 是腾讯混元团队开源的统一 3D 资产数据生态,目标是缓解 3D 生成领域“数据稀缺、噪声大、评测不一致”的常见痛点。项目一次性发布三类互补数据子集:Full-level(252K+ 完整物体)、Part-level(240K+ 部件级结构分解)与 Synthetic(...
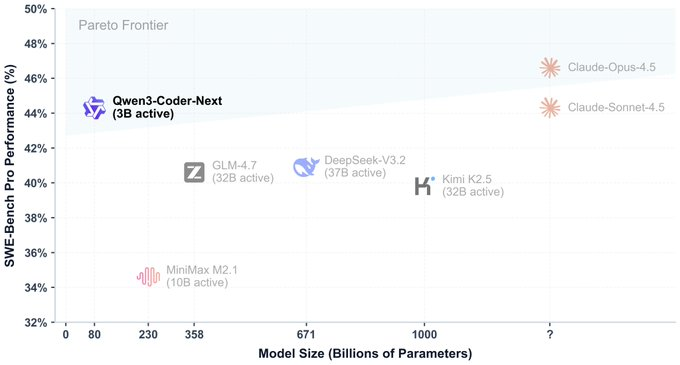
一、摘要 Qwen3-Coder-Next 是 Qwen Team 发布的开源权重代码模型,面向 Coding Agent 与本地开发场景。其核心思路是“超稀疏 MoE + 代理式训练”:总参数量约 80B,但每 token 仅激活约 3B 参数,以更低推理成本支撑长时、多轮的工具使用与代码修改工作...
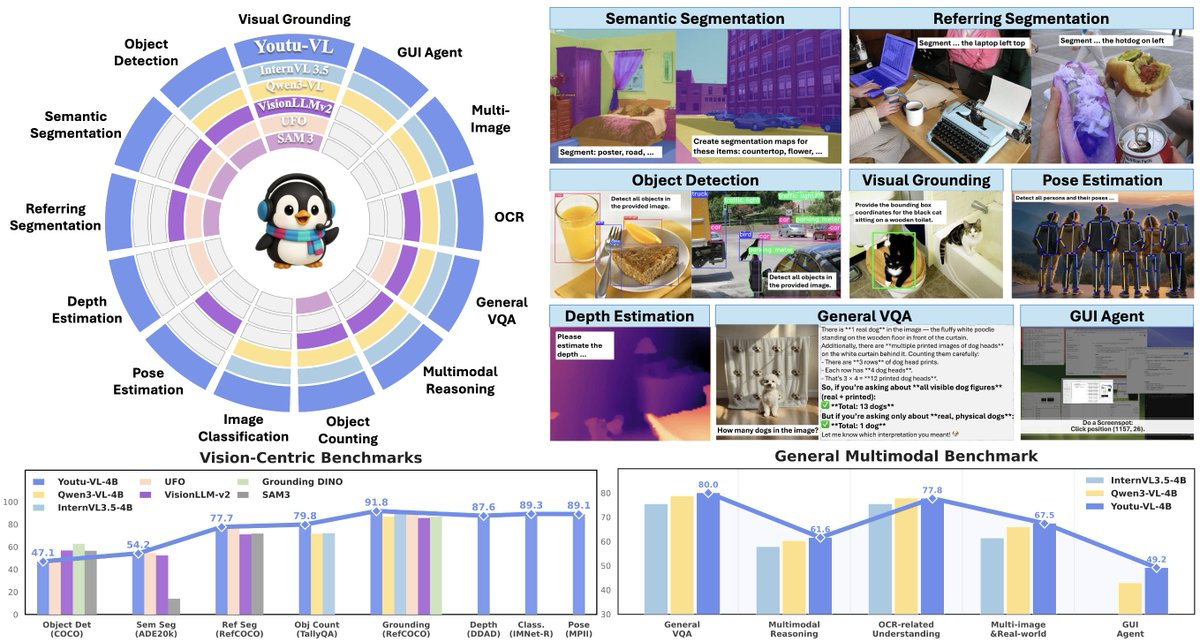
一、摘要 Youtu-VL-4B-Instruct 是腾讯优图开源的紧凑型视觉语言模型(4B 参数),核心提出 VLUAS(Vision-Language Unified Autoregressive Supervision),将“视觉从输入变为可预测目标”,以统一自回归监督保留细粒度视觉信息。其目...
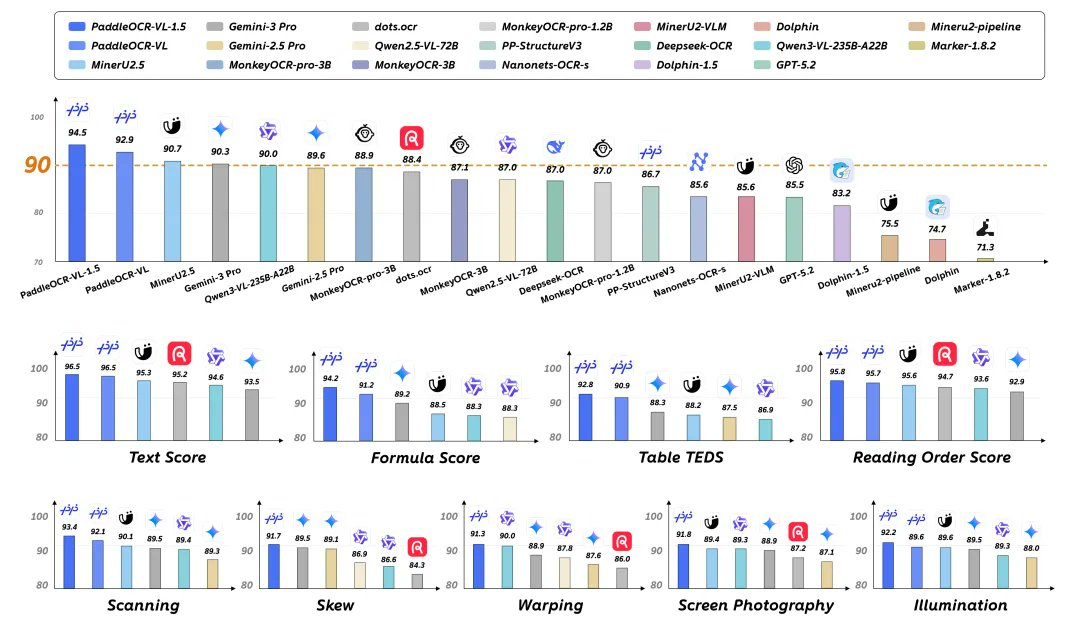
一、摘要 PaddleOCR-VL-1.5 是 PaddlePaddle 开源的 0.9B 参数文档多模态模型,面向“弯曲、扭曲、倾斜、屏摄、复杂光照”等真实采集场景,提供从版面定位、阅读顺序到文本/表格/公式等结构化解析的一体化能力。官方公开结果显示其在 OmniDocBench v1.5 与 R...

一、摘要 PaddleOCR 是基于飞桨(PaddlePaddle)的开源 OCR 与文档解析工具箱,面向图片与 PDF 的“文字识别 + 结构化抽取”。在 3.x 体系中,PP-OCRv5 覆盖通用文字检测与识别,PP-StructureV3 进一步提供复杂文档版面解析能力,可输出更接近原版式的结...