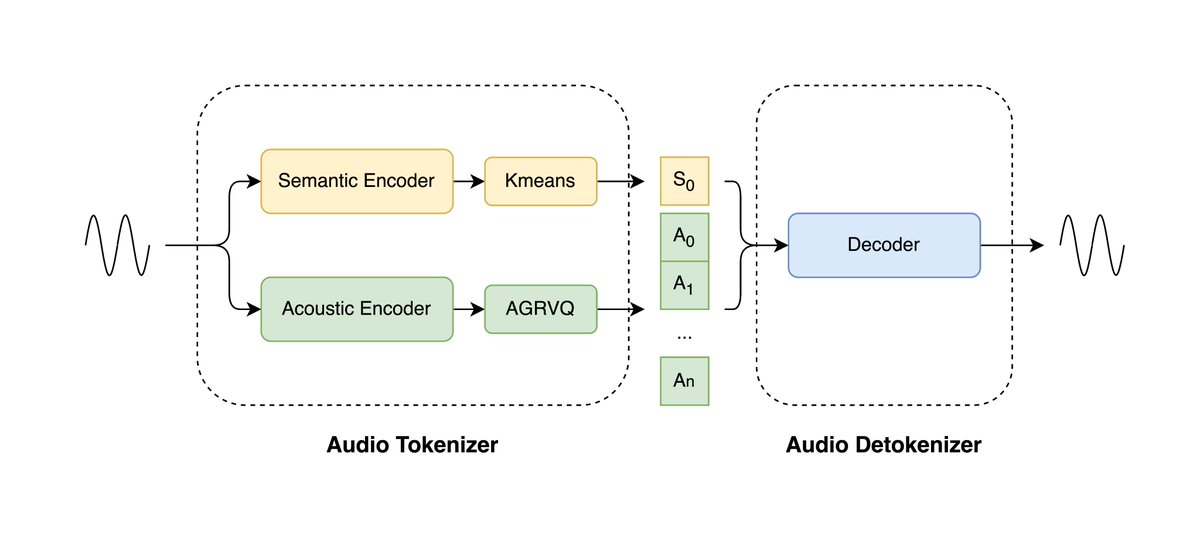
LongCat-Audio-Codec 开源:面向语音大模型的极低码率音频编解码方案
一、摘要 LongCat-Audio-Codec 是美团 LongCat 团队开源的音频编解码方案,专为语音大模型(Speech LLM)优化。项目以“双 Token”架构实现语义与声学信息的并行建模,在仅 0.43 kbps 的超低码率下仍保持语音可懂度与音质。其实时流式解码器延迟控制在百毫秒级,...
Admin •
137
一、摘要 LongCat-Audio-Codec 是美团 LongCat 团队开源的音频编解码方案,专为语音大模型(Speech LLM)优化。项目以“双 Token”架构实现语义与声学信息的并行建模,在仅 0.43 kbps 的超低码率下仍保持语音可懂度与音质。其实时流式解码器延迟控制在百毫秒级,...

一、摘要 Qwen3Guard 是阿里云 Qwen 团队推出的开源安全防护体系,旨在提升大语言模型在推理和输出阶段的安全性。该体系包含强化学习对齐模型 Qwen3-4B-SafeRL 与评测基准 Qwen3GuardTest 。前者利用来自 Qwen3Guard-Gen-4B 的安全反馈进行强化学习...
一、摘要 HunyuanImage 3.0 是腾讯混元开源的原生多模态文生图模型,采用 MoE 架构与 Transfusion 思路统一训练文本与图像。据官方信息:总参数超 80B,推理每 token 激活约 13B;支持理解千词级提示、在图像中精准生成文字,并强调“具备世界知识的推理”。当前版本聚...

一、摘要 Hunyuan3D-Part 是腾讯混元开源的部件级 3D 形状生成与分解方案,由 P3-SAM (原生 3D 部件分割)与 X-Part (可控部件生成)组成。其训练不依赖 2D SAM,基于约 370 万形状与干净部件标注,提供自动化 3D 分割与扩散式部件生成。论文报告在多个基准上达...

一、摘要 Qwen3-VL 是阿里云 Qwen 团队开源的视觉-语言模型,面向图像、视频与文本的统一理解与推理。其亮点包括:原生 256K(可扩展至 1M)上下文、最长期约 2 小时视频的事件“精定位”、OCR 语种由 19 扩展至 32(含稀有字符与倾斜文本)、在真实场景风险检测上的领先表现;并展...
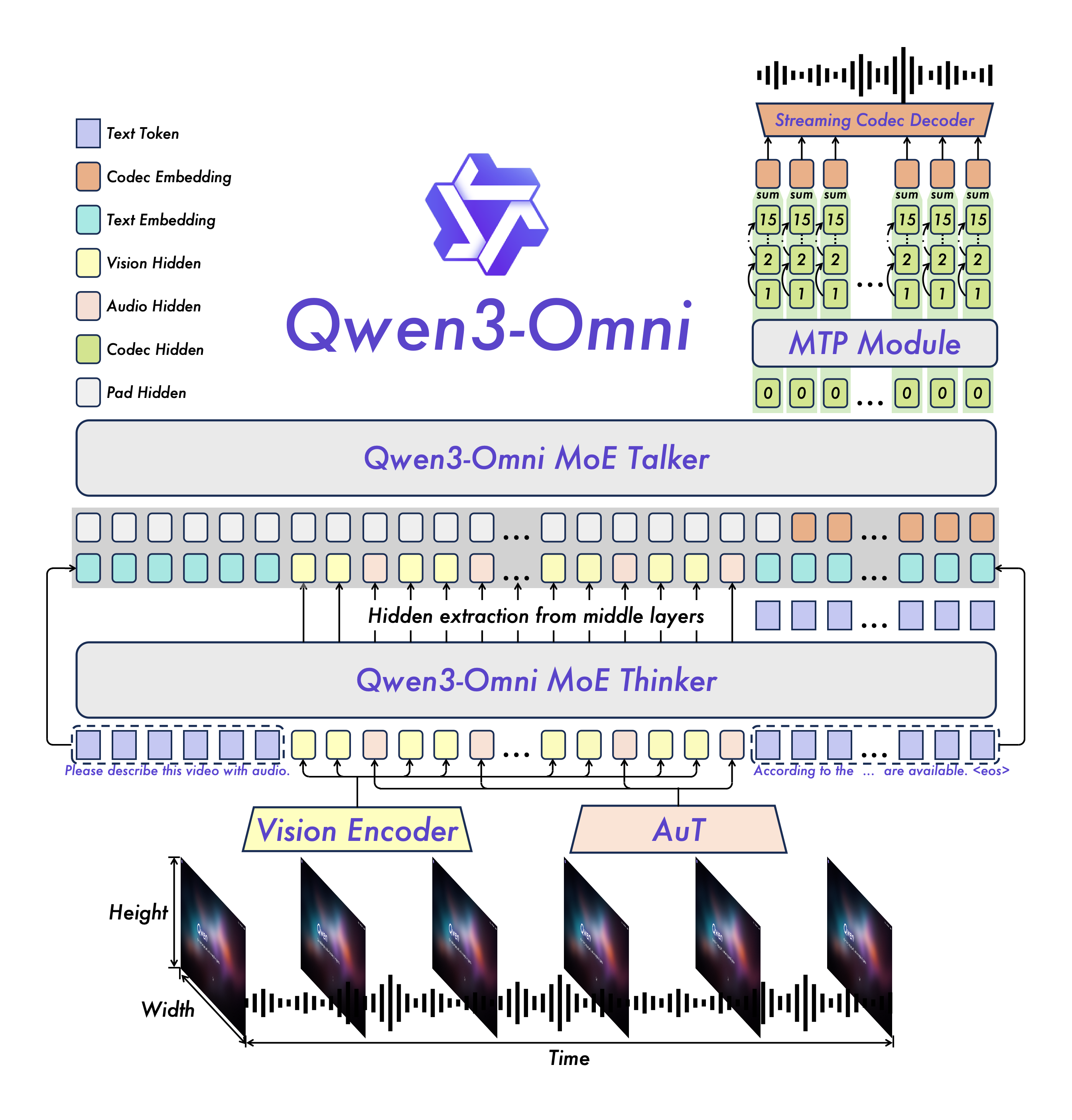
Qwen3-Omni把多模态AI与端到端推理结合到一起:用一个模型统一文本、图像、音频、视频的输入输出,兼顾速度与准确率。在公开测试中,Qwen3-Omni在大量音频与音视频基准上达到领先,并开放多款可用权重,适合快速上手与二次开发。 一、为什么这次的“端到端多模态AI”重要 1、真正统一的多模态A...