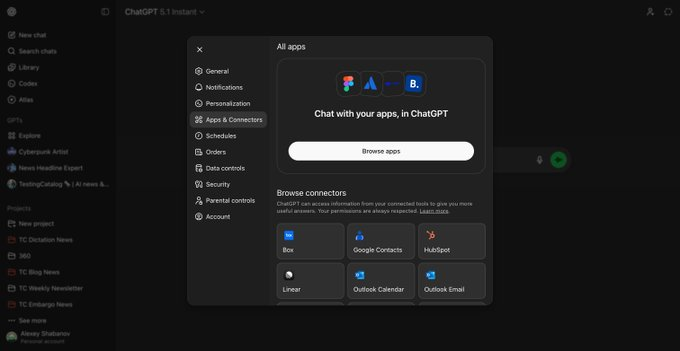
有用户发现 OpenAI ChatGPT设置页出现“Apps”入口 疑为应用目录上线前兆
有用户在 OpenAI 账户设置页面中发现全新的“Apps”号召性入口,点击后会跳转至 /apps 路径,但目前尚未提供实际功能。这一变化被普遍解读为 OpenAI 即将上线官方 App Directory 的前期准备,疑似处于小范围灰度测试阶段。 据反馈,该入口以醒目的按钮或卡片形式呈现,仅对部分...
Admin •
127
有用户在 OpenAI 账户设置页面中发现全新的“Apps”号召性入口,点击后会跳转至 /apps 路径,但目前尚未提供实际功能。这一变化被普遍解读为 OpenAI 即将上线官方 App Directory 的前期准备,疑似处于小范围灰度测试阶段。 据反馈,该入口以醒目的按钮或卡片形式呈现,仅对部分...
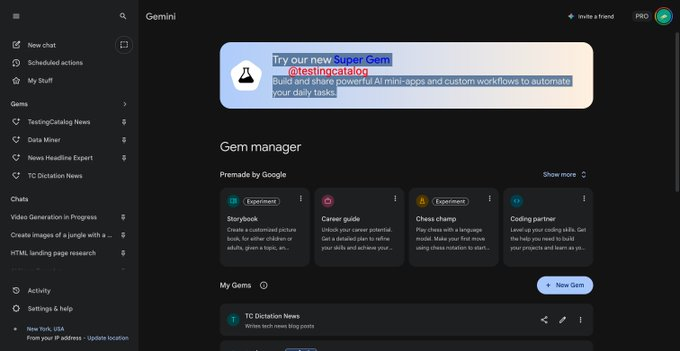
有开发者情报称,Google 可能计划把 Opal 代理流构建器直接集成到 Gemini 客户端中,作为一种名为「Super Gem」的高级能力入口。相关爆料文案显示,用户将可以在 Gemini 内构建和分享 AI 小应用与自定义工作流,用于自动化日常任务,而无需离开主对话界面。 Opal 当前是 ...

Cursor 发布博文介绍其针对 OpenAI 最新编码模型 GPT-5.1-Codex-Max 的代理框架升级。团队围绕内部评测套件 Cursor Bench 构建了更健壮的 Agent 测试体系,从成功率、工具调用能力和真实使用数据多维度优化 Codex 在 Cursor 环境中的表现,以便充分...
Google 面向 Google AI Ultra 订阅用户在 Gemini 应用中推出更新版 Gemini 3 Deep Think 模式,主打进一步提升复杂任务下的推理能力。官方介绍,这一模式通过“高级并行思考”机制,同时探索多种假设路径,再在内部整合评估,从而在数学推导、算法设计等场景中生成更...

AI 开发工具 Kiro 正式推出「Kiro powers」功能,主打解决 AI 代理在连接多个 MCP 服务器时出现的上下文过载与响应变慢问题。官方介绍称,传统做法会一次性加载所有工具定义与文档,轻易占满大部分上下文窗口,而 powers 则将 MCP 服务器、steering 文件和 hooks...
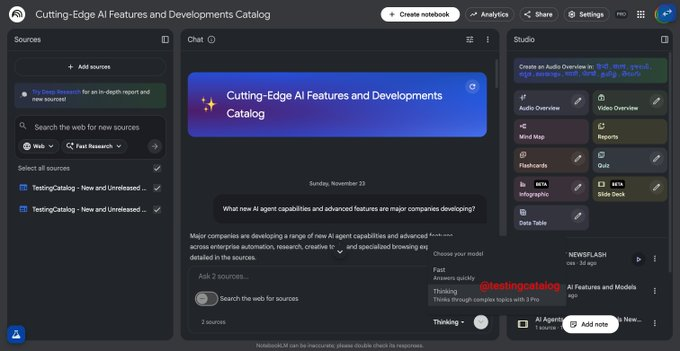
近期开发者社区流出信息称,Google 正在为 NotebookLM 开发内置模型选择器,在界面中提供下拉菜单,允许用户在 Gemini Flash 与 Pro 等不同模型之间切换,以便根据任务在响应速度与输出质量之间做取舍。相关描述显示,该功能尚处测试阶段,目前尚未在正式版 NotebookLM ...