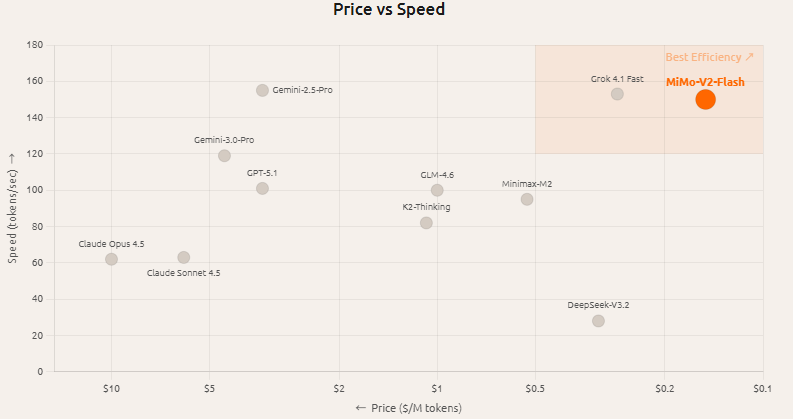
MiMo 技术架构速览:MoE、混合注意力与 MTP 提速
一、开源与获取 MiMo 已开放权重与配套资料。优先在 Hugging Face 的 XiaomiMiMo 组织页获取模型(含 MiMo-V2-Flash/Base 等),技术报告与部分代码在 GitHub;也提供在线 Studio 与 API 平台入口。 二、技术架构与数据 MiMo-V2-Fla...
Admin •
153
一、开源与获取 MiMo 已开放权重与配套资料。优先在 Hugging Face 的 XiaomiMiMo 组织页获取模型(含 MiMo-V2-Flash/Base 等),技术报告与部分代码在 GitHub;也提供在线 Studio 与 API 平台入口。 二、技术架构与数据 MiMo-V2-Fla...
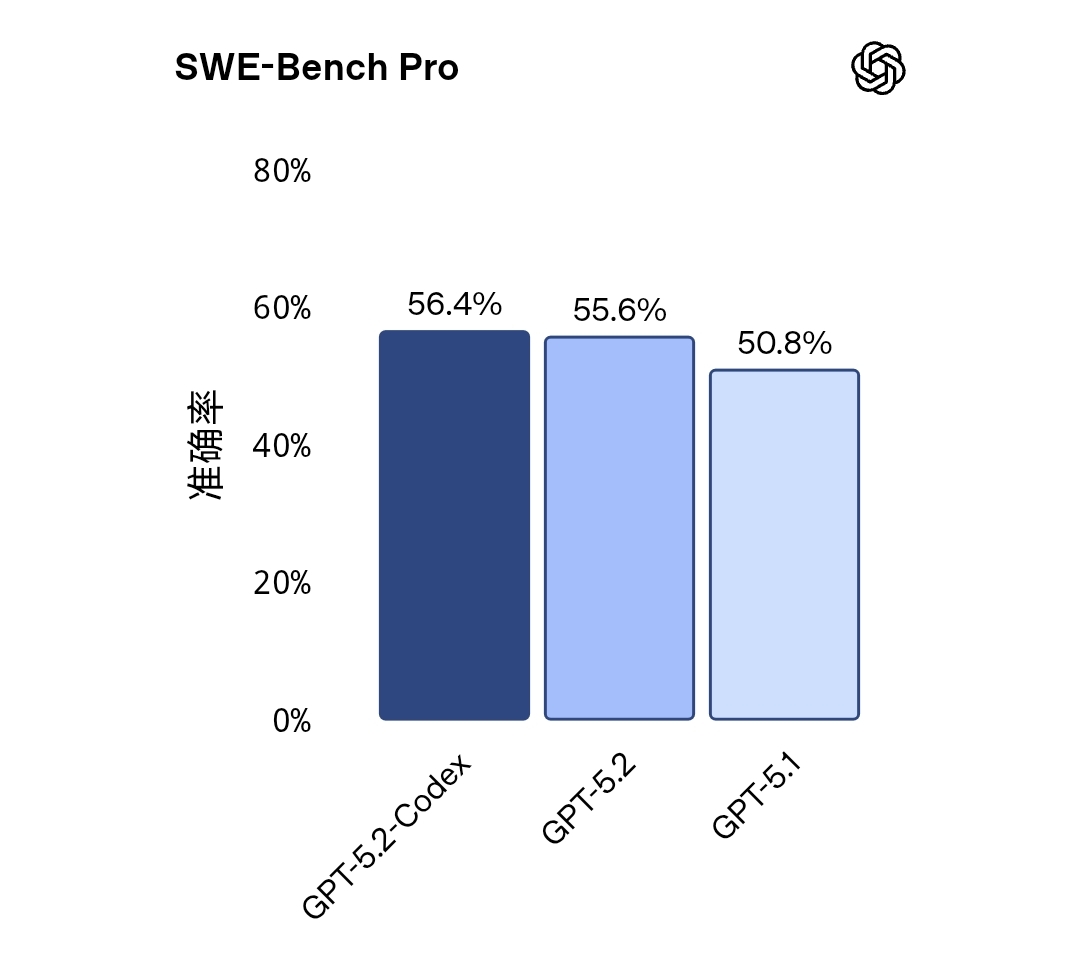
OpenAI正式发布GPT-5.2 Codex,这是GPT-5系列中专注于编程与软件工程场景的代码模型版本。官方介绍称,该模型在代码生成、理解、调试与重构等核心能力上较此前版本有所提升,目标是更好地服务真实开发环境中的复杂需求,而不仅限于单段代码补全。 GPT-5.2 Codex被定位为“工程导向”...
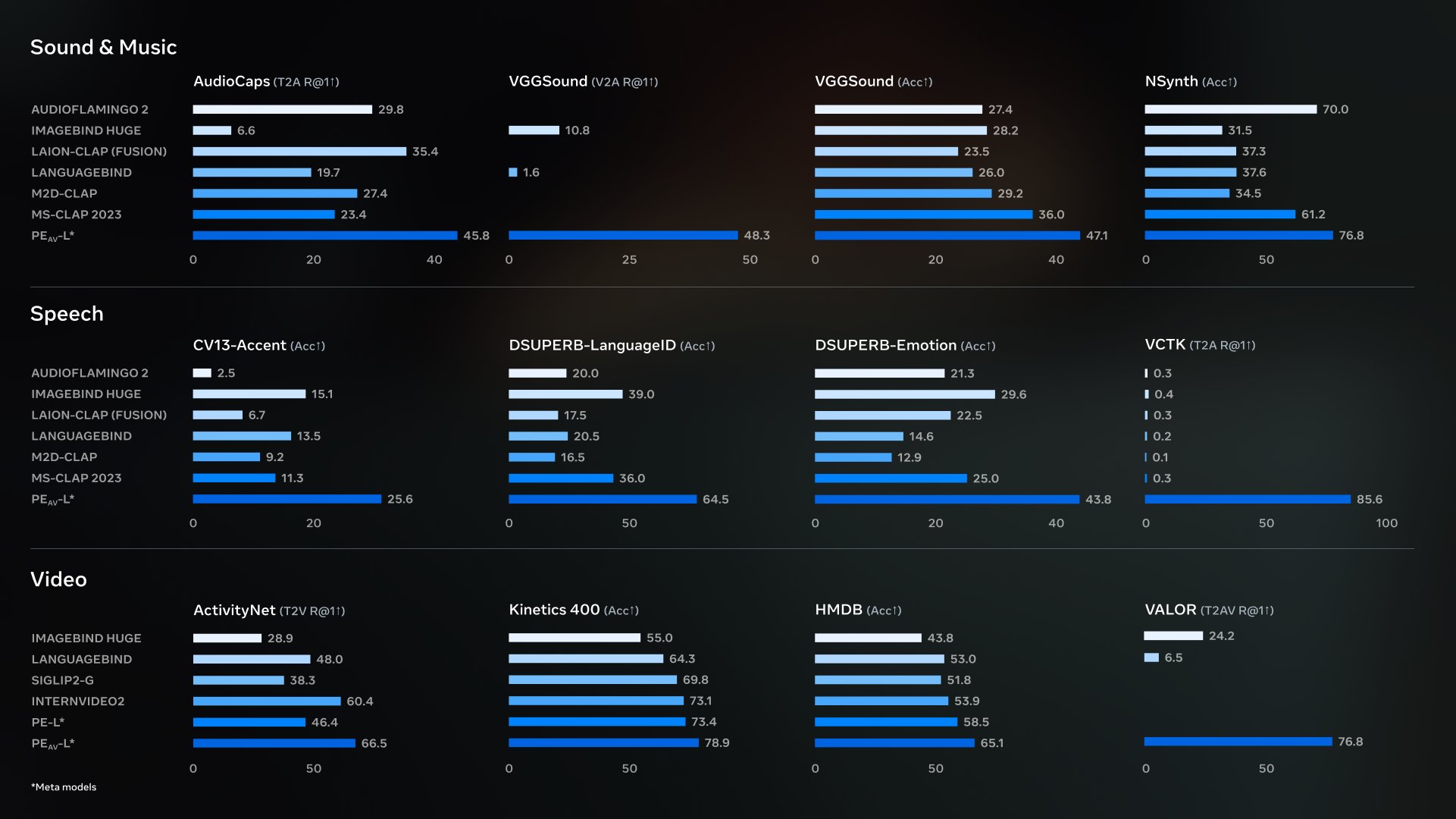
Meta旗下AI at Meta宣布开源Perception Encoder Audiovisual(PE-AV),并将其定位为推动SAM Audio达到前沿音频分离效果的关键技术引擎。PE-AV基于更早发布的Perception Encoder体系,将音频与视觉感知进行原生融合,用于在同一表示空间...
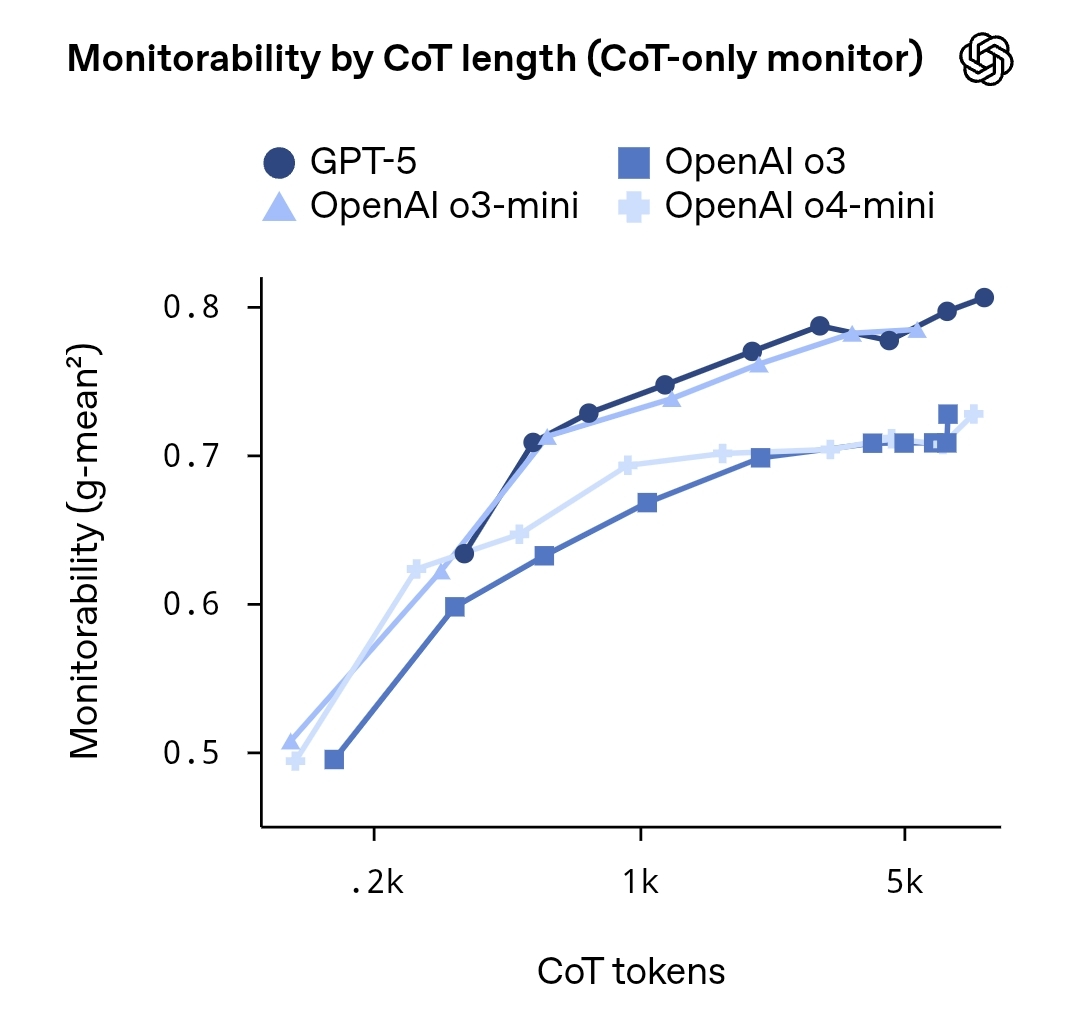
OpenAI发布研究报告《Evaluating Chain-of-Thought Monitorability》,系统评估大型语言模型内部“思维链”(Chain-of-Thought, CoT)的可监测性及安全影响。报告指出,尽管模型生成的推理过程可通过外部提示或代理模型在一定程度上预测,但其完整、...
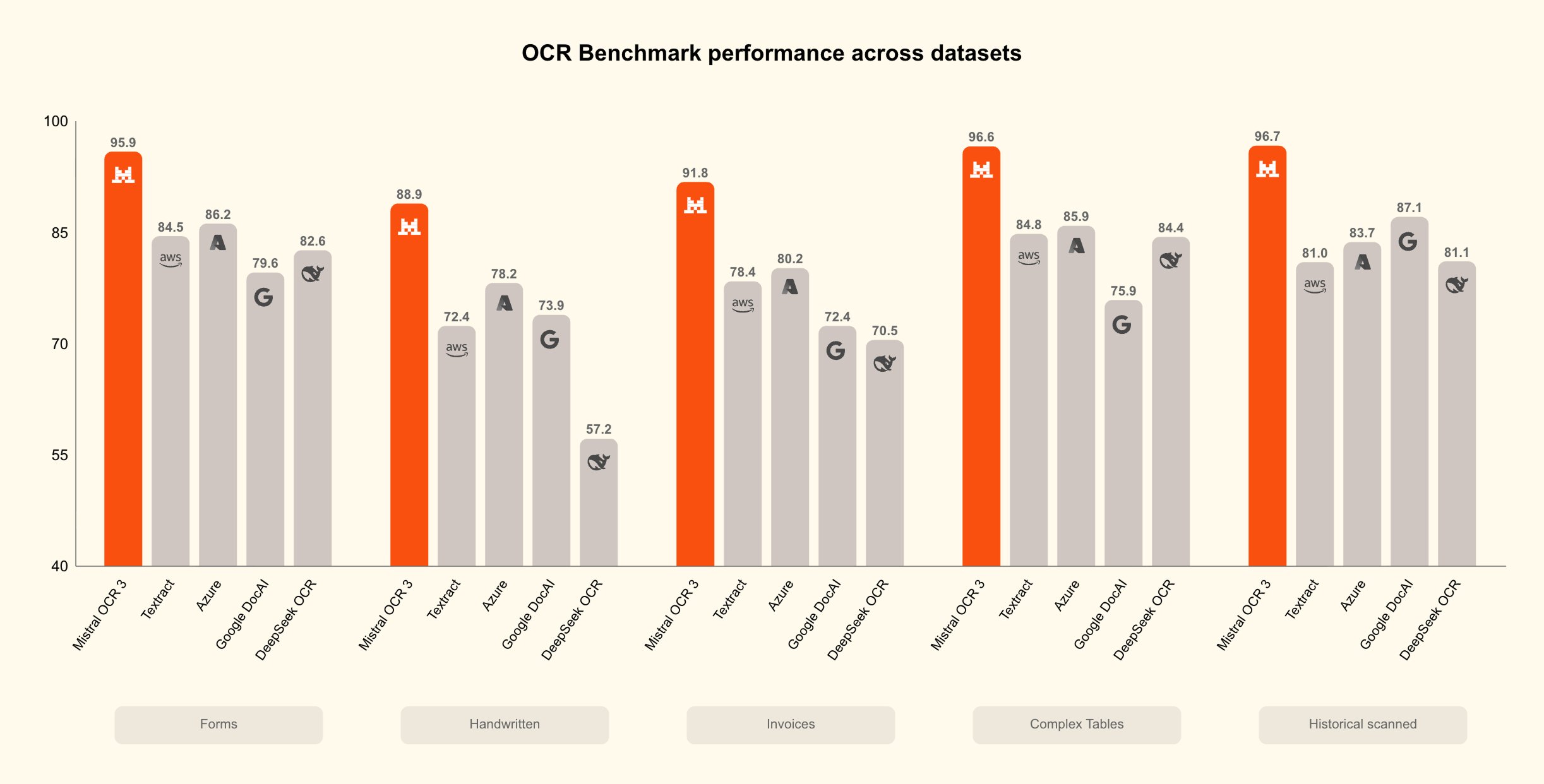
法国AI公司Mistral宣布推出第三代光学字符识别模型Mistral OCR 3,并将其定位为“文档智能”核心能力,面向表单、扫描PDF、复杂表格与手写内容等企业常见场景。官方披露,该模型在其对比评测中取得约74%的“整体胜率”,并宣称在准确率与效率上优于传统企业文档处理方案及部分AI原生OCR系...
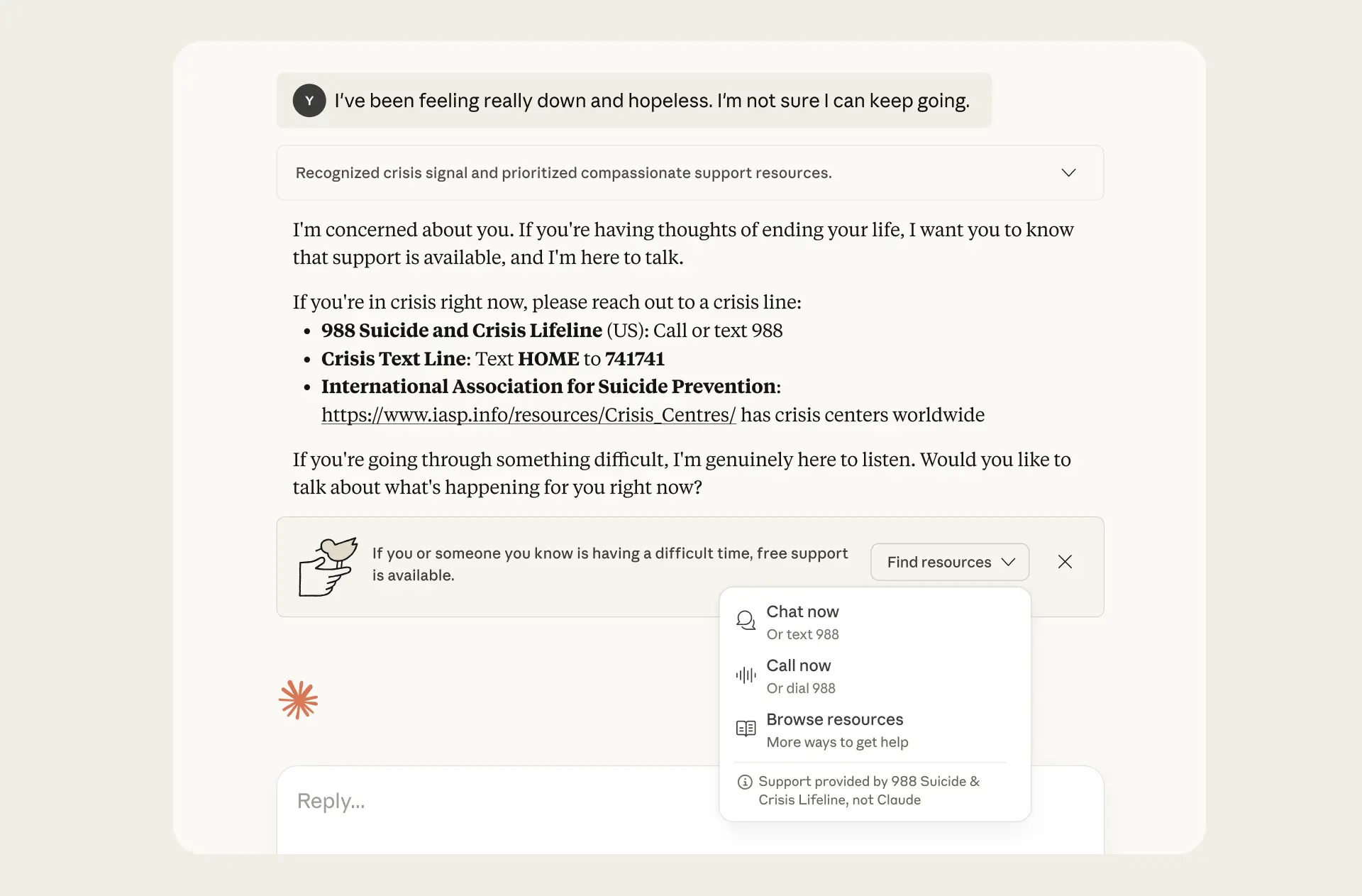
Anthropic发布公告,介绍其聊天机器人Claude在“用户身心健康”方面的最新安全措施与评估结果,重点聚焦自杀与自伤话题的应对,以及减少模型“阿谀式迎合”的倾向,并再次强调Claude的18岁以上使用要求。公告指出,Claude并非专业医疗或心理替代服务,当对话出现自伤风险迹象时,应以同理回应...