1. Abstract
VTP (Visual Tokenizer Pre-training) ist ein Open-Source-Visual-Tokenizer-Pre-Training-Framework, das vom MiniMax (Hailuo)-Team entwickelt wurde und sich auf nächste generative Modelle wie Diffusionsmodelle und Diffusion Transformer (DiT) konzentriert. Das Projekt wies darauf hin, dass das traditionelle "Rebuild-only"-Tokenizer-Training den latenten Raum zugunsten niedrigstufiger Pixelinformationen verzerrt, was zu dem Problem der vortrainierenden Skalierung führt, dass "Rekonstruktion genauer, aber nicht unbedingt bessere Generierung ist". VTP wird gemeinsam das Repräsentationslernen und die Kompressionsrekonstruktion optimieren, sodass der Tokenizer stabiler in eine Qualitätsverbesserung der Downstream-Generierung umsetzen kann, wenn Modellgröße, Daten und Rechenleistung wachsen, und versucht, die Standard-DiT-Trainingsspezifikationen nicht zu ändern.
2. Kernmerkmale
- Gemeinsame Optimierung von drei Arten von Zielen: grafisches und textvergleichendes Lernen, selbstüberwachtes Lernen und Rekonstruktionsziel-gemeinsames Training unter Berücksichtigung semantischer Darstellung und Dekodierung.
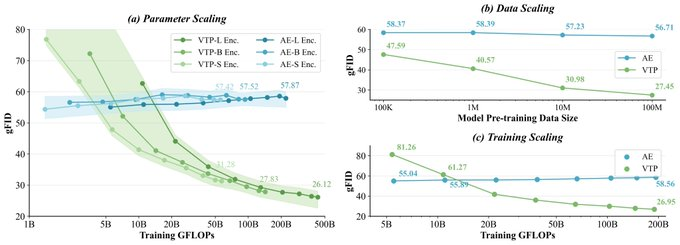
- Skalierbare Tokenizer-Skalierung: Betonung, dass die Investition von Rechenleistung in Tokenizer-Pre-Training Vorteile für die Downstream-Generierung bringen kann, anstatt nur geringere Rekonstruktionsfehler zu verfolgen.
- Generationsorientierte Evaluationsverbindung: Bietet eine integrierte Steuerung von Verständnis (Zero-Shot/lineare Sonde), Rekonstruktion (rFID) und Erzeugung (FID basierend auf LightningDiT).
- Open-Source-Gewichte und Modelle mit mehreren Größen: Hugging Face bietet Modellspezifikationen wie Small/Base/Large, um Kompromisse basierend auf Ressourcen und Effekten zu erleichtern.
3. Installation
- Erstellen Sie eine Umgebung: Conda erstellt eine Python 3.10-Umgebung und aktiviert sie.
- Submodule initialisieren: Das Warehouse verwendet Submodule, um einen abhängigen Code zu verwalten, der rekursiv abgerufen werden muss.
- Installationsabhängigkeiten: Installieren Sie Python-Abhängigkeiten entsprechend den Anforderungen.
- Ausführen Sie das Evaluationsskript: ändern Sie den Pfad gemäß der Skriptbeschreibung und führen Sie das Zero-Sample-, lineare Erkennungs-, Rekonstruktions- und Generierungsbewertungsskript aus; Generiere einen Evaluationslink und nutze LightningDiT-bezogene Skripte, um Feature-Extraktion, Training und Sampling durchzuführen.
4. Typische Anwendungsfälle
- Phase-1-Tokenizer des DiT/Diffusionsmodells: Überprüfen Sie den Einfluss von "stärkeren latenten" auf Erzeugungsqualität und Konvergenzgeschwindigkeit, ohne die Generatorstruktur zu verändern.
- Visuelle Repräsentationsextraktion: verwendet für Abruf, Klassifikation, Clustering oder nachgelagerte Lichtaufgaben (Zero-Shot und lineare Sonde).
- Kompromiss zwischen Forschungsrekonstruktion und semantischer Verarbeitung: Im Vergleich zum traditionellen VAE/VQ-Tokenizer werden die semantiken und generativen Lernänderungen des latenten Raums nach dem Hinzufügen von Repräsentationslernen analysiert.
- Reproduzieren der experimentellen Kurve: Basierend auf dem Open-Source-Skript wird der skalierende Vergleich von Parametern/Daten/Rechenleistungsdimensionen verwendet, um die Korrelationskurve zwischen Tokenizer- und Generationsleistung zu konstruieren.
5. Ökologie und konkurrierende Produkte
- Verwandte Ökologie: Die Trainings- und Evaluationsverbindung umfasst vergleichendes Lernen, selbstüberwachtes Repräsentationslernen und DiT-Generierungsbewertungsprozesse, was praktisch ist, um sich an gängige visuelle Repräsentations- und Diffusionsgenerierungssysteme anzupassen.
- Ausrichtung der konkurrierenden Produkte: traditionelle LDM verwendeten häufig rekonstruierte VAE, VQ-VAE/VQGAN usw. als Tokenizer; Es gibt auch verbesserte Wege, um den latenten Raum durch Destillation oder Regelmäßigkeit zu erhöhen. Der Unterschied von VTP besteht darin, dass es "Verständnis/Charakterisierung" als Schlüsselfaktor für generative Skalierbarkeit nimmt und dessen Gewinn für die nachgelagerte Generierung mit systematischer Bewertung überprüft.
6. Einschränkungen und Vorsichtsmaßnahmen
- Ressourcenschwellenwert: Die vollständige Reproduktion der großflächigen Tokenizer-Vorschulung und Generierungsbewertung erfordert starke Rechenleistung, Daten- und Engineering-Pipelines.
- Kosten für die technische Integration: Bevor der bestehende Tokenizer ersetzt wird, ist es notwendig, die latente variable Schnittstelle, das Kompressionsverhältnis, die Dekodiergeschwindigkeit und die End-to-End-Stabilität zu bewerten.
- Die Ergebnisse hängen von der Trainingsformel ab: Unterschiedliche Datenverteilungen, Stichprobenstrategien und Generatoreinstellungen beeinflussen die endgültigen Indikatoren, und es wird empfohlen, einen strikten Budgetvergleich und eine visuelle Inspektion durchzuführen.
- Das Projekt entwickelt sich noch weiter: Einige Modelle/Skripte und Anweisungen können mit Versionsupdates angepasst werden, und es wird empfohlen, auf die neuesten Inhalte des Repositorys und der Modellseiten zu schauen.
7. Projektadresse
https://github.com/MiniMax-AI/VTP
8. FAQs
F: Welches Kernproblem wird durch VTP (Visual Tokenizer Pre-training) gelöst?
A: Lösen Sie das "Visual Tokenizer-Pre-Training Scale-Problem", das heißt, es ist für herkömmliche Tokenizer, die nur das Training neu aufbauen, schwierig, um mehr Rechenleistung stabil in eine nachgelagerte DiT/Diffusion-Generierungsverbesserung umzuwandeln.
F: Warum legt VTP bei der Erzeugung (Diffusion Transformer/DiT) mehr Wert auf repräsentationelles Lernen?
A: Die Idee ist, einen lernbaren latenten Raum zu erzeugen, der mehr auf hochrangiger Semantik und Struktur setzt; Nur die Genauigkeit der Rekonstruktion auf Pixelebene kann den latenten Raum leicht zu Low-Level-Informationen machen, was zu einer Stagnation der Erzeugungserlöse führt.
F: Kann VTP die Erzeugungsqualität verbessern, ohne die Trainingsleistung des Generators zu erhöhen?
A: Das Ziel ist es, das Hauptinkrementer auf der Tokenizer-Vortrainingsseite zu legen und zu versuchen, die Standard-DiT-Trainingsspezifikationen vergleichbar zu halten, um zu besserer Generierung mit besserer Latenz zu führen.
F: Wie sollte ich VTP-Small/Base/Large auf Hugging Face wählen?
A: Im Allgemeinen haben größere Tokenizer stärkere Repräsentationsfähigkeiten, aber einen höheren Ressourcenbedarf; Du kannst Small/Base nutzen, um zuerst den Bewertungslink durchzugehen und dann die Vorteile von Large unter demselben Budget zu bewerten.
F: Worauf sollte ich mich beim Austausch des VAE/VQ-Tokenizers eines bestehenden LDM konzentrieren?
A: Fokus auf latente Variablenformen und Schnittstellenkompatibilität, Kompressionsrate und Dekodierungsgeschwindigkeit, Stabilität des Generationstrainings sowie FID/Konvergenzgeschwindigkeit und subjektive Qualität im gleichen Trainingsbudget.