LongCat-Flash-Thinking把AI与MoE、异步RL和Agent原生工具结合,在Logic、Math、Coding、Agent任务对齐SOTA;AIME25以更少Token达成高准确,适合企业用低成本获得高质量推理与稳定落地。
一、为什么它值得现在部署
1、架构亮点:MoE动态激活(LongCat-Flash-Thinking)
AI通过MoE按需启用专家,保留深度推理同时降低推理开销与显存占用,支撑长链路问题分解与可解释输出。
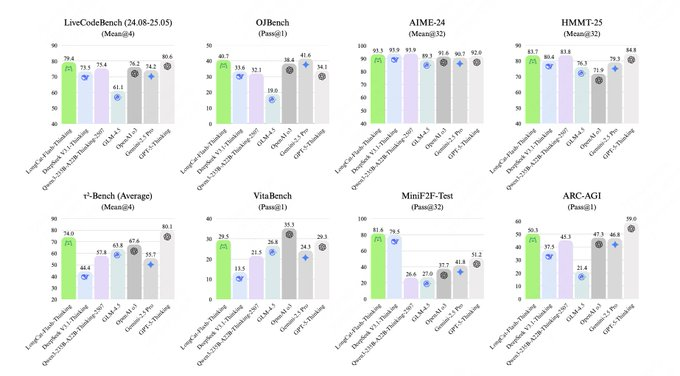
2、效率与成本:AIME25更省Token(LongCat-Flash-Thinking)
AI依托原生工具与Agent友好策略,达到顶级准确所需Token显著下降,推理成本与时延同步优化,利于大规模线上服务。
3、基础设施:异步RL三倍加速(LongCat-Flash-Thinking)
异步RL把采样与优化解耦,提高吞吐与稳定性;结合数据回放与自动评测,缩短迭代周期,形成训练到部署的快速闭环。
二、落地方法与场景清单
1、部署路径(LongCat-Flash-Thinking)
(1)推理框架:优先vLLM或SGLang,结合KV Cache与批处理
(2)资源策略:简单任务关长思考,复杂任务启思考与工具
(3)观测指标:记录Token、延迟、成功率,自动化调参
2、提示词与Agent管线(LongCat-Flash-Thinking)
(1)先判定是否需要工具,再进入函数调用
(2)为Math与Code设置固定输入输出模板
(3)多工具并发配置超时、重试与回退路径
(3)典型应用(LongCat-Flash-Thinking)
a. 代码修复与回归定位
b. 检索加计算的流程型Agent
c. 报表生成与复杂问答自动化
三、效果度量与治理要点
1、效果侧(AI+LongCat-Flash-Thinking)
以准确率、步骤可解释度与Agent成功率评估,并关注长链路稳定性与可回放性。
2、成本侧(AI+LongCat-Flash-Thinking)
围绕每任务Token、显存峰值与端到端时延做监控,量化A/B收益,形成持续优化。
3、治理侧(AI+LongCat-Flash-Thinking)
沉淀统一提示词模板、数据版本与日志,降低提示敏感性与漂移风险。
常见问题解答(Q&A)
Q:LongCat-Flash-Thinking在AI任务上处于什么水平?
A:在逻辑、数学、编程与Agent任务属于开源SOTA梯队,强调稳定推理与可复现评测。
Q:为什么在AIME25上能更省Token?
A:依靠原生工具与Agent友好策略,先判定再调用,减少无效长思考,在同等精度下降低推理成本。
Q:异步RL对工程有什么直接收益?
A:训练吞吐提升、收敛更稳、迭代更快,有助于迅速把模型改进推向线上并验证收益。
Q:企业如何快速上手并控成本?
A:选高吞吐推理引擎,启用批处理与缓存;用思考开关区分任务难度;持续监控Token与时延并自动调参。