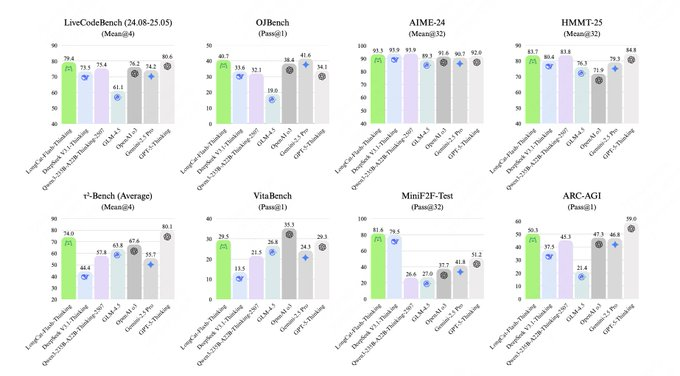
LongCat-Flash-Thinking combines AI with MoE, asynchronous RL, and agent-native tools, achieving state-of-the-art performance in logic, math, coding, and agent tasks. AIME25 achieves high accuracy with fewer tokens, making it suitable for enterprises to achieve high-quality inference and stable implementation at a low cost. I. Why It's Worth Deploying Now 1. Architecture Highlights: Dynamic MoE Activation (LongCat-Flash-Thinking) AI activates experts on demand through MoE, preserving deep inference while reducing inference overhead and memory usage, supporting long-chain problem decomposition and interpretable output. 2. Efficiency and Cost: AIME25 Saves Tokens (LongCat-Flash-Thinking) AI leverages native tools and agent-friendly strategies to significantly reduce the tokens required to achieve top-level accuracy, optimizing both inference cost and latency, and facilitating large-scale online services. 3. Infrastructure: Asynchronous RL Triple Acceleration (LongCat-Flash-Thinking) Asynchronous RL decouples sampling and optimization to improve throughput and stability. It combines data playback and automatic evaluation to shorten iteration cycles and form a fast closed loop from training to deployment.
II. Implementation methods and scenario list
1. Deployment path (LongCat-Flash-Thinking)
(1) Reasoning framework: prioritize vLLM or SGLang, combined with KV Cache and batch processing
(2) Resource strategy: simple tasks require long thinking, complex tasks require thinking and tools
(3) Observation indicators: record tokens, delays, success rates, and automate parameter adjustment
2. Prompt words and Agent pipeline (LongCat-Flash-Thinking)
(1) Determine whether a tool is needed before entering the function call
(2) Set fixed input and output templates for Math and Code
(3) Configure timeout, retry, and fallback paths for multiple tools concurrently
(3) Typical applications (LongCat-Flash-Thinking)
a. Code repair and regression location
b. Process-based agent with search and computation
c. Report generation and complex question-answering automation
III. Key Points for Performance Measurement and Governance
1. Performance (AI + LongCat-Flash-Thinking)
Evaluate based on accuracy, step explainability, and agent success rate, with a focus on long-term link stability and replayability.
2. Cost (AI + LongCat-Flash-Thinking)
Monitor per-task tokens, memory peaks, and end-to-end latency to quantify A/B benefits and enable continuous optimization.
3. Governance (AI + LongCat-Flash-Thinking)
Consolidate unified prompt templates, data versions, and logs to reduce prompt sensitivity and the risk of drift.
Frequently Asked Questions (Q&A)
Q: What is the performance of LongCat-Flash-Thinking in AI tasks?
A: It ranks among the open-source SOTA leaders in logic, mathematics, programming, and agent tasks, emphasizing stable reasoning and reproducible evaluation.
Q: Why is it more efficient in AIME25?
A: We leverage native tools and agent-friendly strategies to prioritize decisions before invoking them, reducing ineffective, long-term thinking and lowering inference costs while maintaining the same accuracy.
Q: What are the direct benefits of asynchronous RL for engineering?
A: Improved training throughput, more stable convergence, and faster iteration help us quickly bring model improvements online and verify their benefits.
Q: How can companies quickly get started and control costs?
A: Choose a high-throughput inference engine, enable batching and caching; use a thinking switch to differentiate task difficulty; continuously monitor tokens and latency, and automatically adjust parameters.