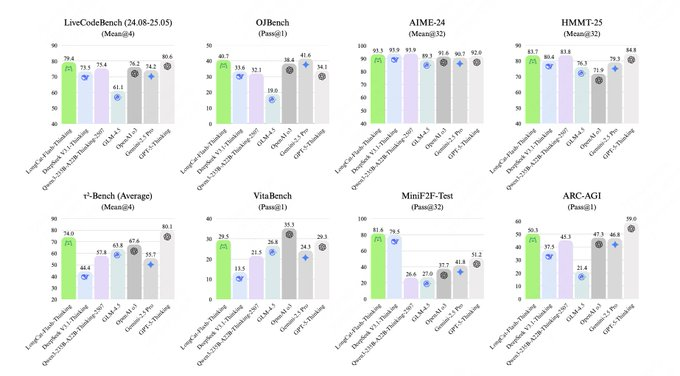
LongCat-Flash-Thinkingは、AIとMoE、非同期RL、エージェントネイティブツールを組み合わせ、ロジック、数学、コーディング、エージェントタスクで最先端のパフォーマンスを実現します。 AIME25は少ないトークンで高い精度を実現するため、企業が低コストで高品質の推論と安定した実装を実現するのに適しています。 I. 今すぐ導入する価値がある理由 1. アーキテクチャのハイライト:動的MoEアクティベーション(LongCat-Flash-Thinking) AIは、MoEを介してオンデマンドでエキスパートをアクティベートし、深い推論を維持しながら推論のオーバーヘッドとメモリ使用量を削減し、長鎖問題の分解と解釈可能な出力をサポートします。 2. 効率とコスト:AIME25はトークンを節約(LongCat-Flash-Thinking) AIはネイティブツールとエージェントフレンドリーな戦略を活用して、最高レベルの精度を達成するために必要なトークンを大幅に削減し、推論コストとレイテンシの両方を最適化し、大規模なオンラインサービスを促進します。 3. インフラストラクチャ: 非同期強化学習トリプルアクセラレーション (LongCat-Flash-Thinking) 非同期強化学習は、サンプリングと最適化を分離することで、スループットと安定性を向上させます。データ再生と自動評価を組み合わせることで、反復サイクルを短縮し、トレーニングからデプロイメントまでの高速な閉ループを形成します。
II. 実装方法とシナリオリスト
1. デプロイメントパス (LongCat-Flash-Thinking)
(1) 推論フレームワーク: vLLM または SGLang を優先し、KV Cache とバッチ処理を組み合わせる
(2) リソース戦略: 単純なタスクには長い思考が必要で、複雑なタスクには思考とツールが必要
(3) 観測指標: トークン、遅延、成功率を記録し、パラメータ調整を自動化する
2.プロンプトワードとエージェント パイプライン (LongCat-Flash-Thinking)
(1) 関数呼び出しに入る前にツールが必要かどうかを判断する
(2) Math と Code の固定の入力および出力テンプレートを設定する
(3) 複数のツールのタイムアウト、再試行、フォールバック パスを同時に構成する
(3) 一般的なアプリケーション (LongCat-Flash-Thinking)
a. コード修復と回帰の場所
b. 検索と計算を備えたプロセスベースのエージェント
c. レポート生成と複雑な質問応答の自動化
III. パフォーマンス測定とガバナンスの重要なポイント
1.パフォーマンス(AI + LongCat-Flash-Thinking)
精度、ステップの説明可能性、エージェントの成功率に基づいて評価し、長期的なリンクの安定性と再生可能性に重点を置きます。
2. コスト(AI + LongCat-Flash-Thinking)
タスクごとのトークン、メモリのピーク、エンドツーエンドのレイテンシを監視して、A/B の利点を定量化し、継続的な最適化を可能にします。
3. ガバナンス(AI + LongCat-Flash-Thinking)
プロンプトの感度とドリフトのリスクを軽減するために、統合されたプロンプト テンプレート、データ バージョン、およびログを統合します。
よくある質問(Q&A)
Q: AI タスクにおける LongCat-Flash-Thinking のパフォーマンスはどの程度ですか?
A: 論理、数学、プログラミング、エージェント タスクにおいて、オープンソースの SOTA リーダーにランクされており、安定した推論と再現可能な評価を重視しています。
Q: AIME25 でより効率的なのはなぜですか?
A: ネイティブ ツールとエージェントに適した戦略を活用して、決定を呼び出す前に優先順位を付けることで、非効率的な長期的な思考を減らし、推論コストを削減しながら、同じ精度を維持しています。
Q: エンジニアリングにおける非同期強化学習の直接的なメリットは何ですか?
A: トレーニング スループットの向上、収束の安定性の向上、反復の高速化により、モデルの改善を迅速にオンライン化し、そのメリットを検証できます。
Q: 企業はどのように迅速に開始し、コストを管理できますか?
A: 高スループットの推論を選択するエンジンは、バッチ処理とキャッシュを有効にし、思考スイッチを使用してタスクの難易度を区別し、トークンとレイテンシを継続的に監視し、パラメータを自動的に調整します。