一、摘要
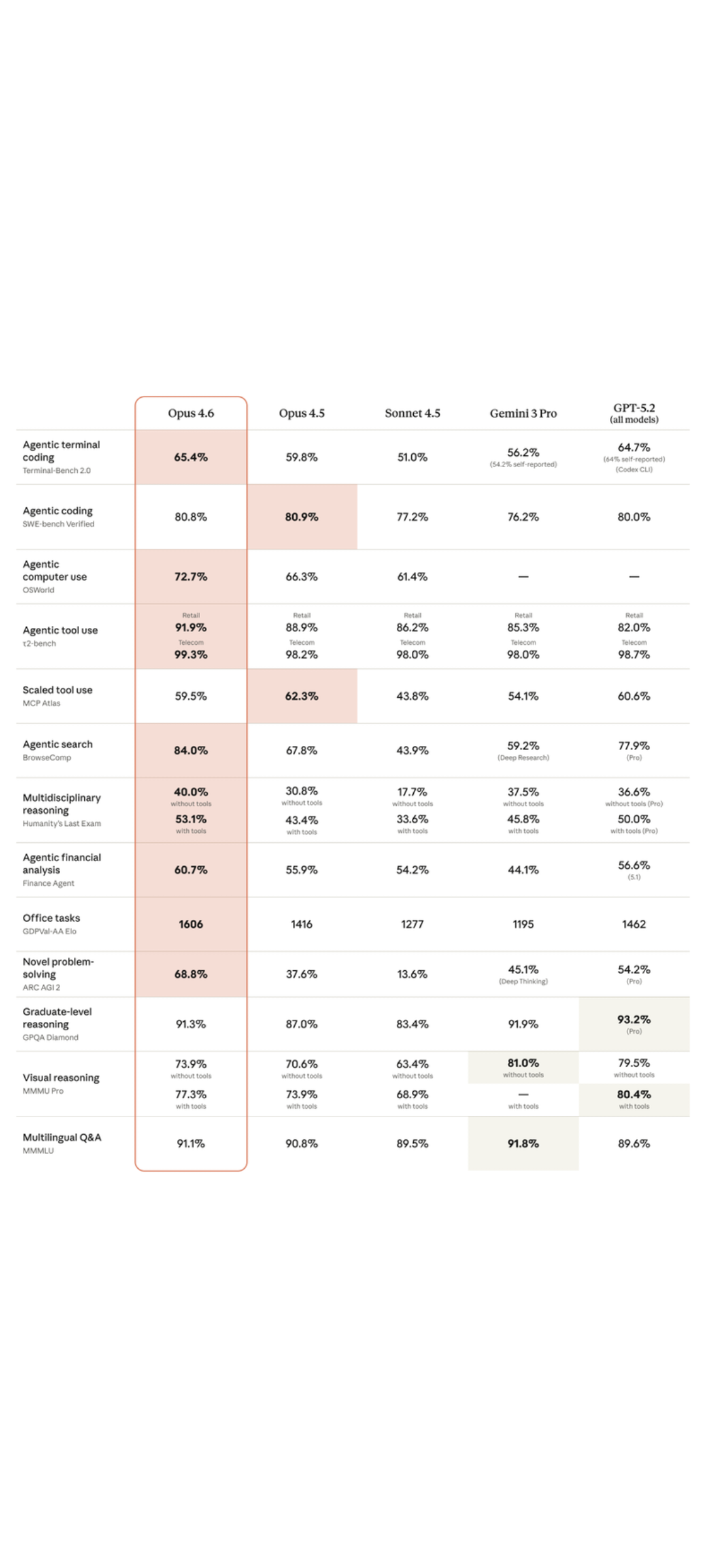
HY3D-Bench 是腾讯混元团队开源的统一 3D 资产数据生态,目标是缓解 3D 生成领域“数据稀缺、噪声大、评测不一致”的常见痛点。项目一次性发布三类互补数据子集:Full-level(252K+ 完整物体)、Part-level(240K+ 部件级结构分解)与 Synthetic(125K+ AIGC 合成长尾类目),并提供轻量可复现的基线模型 Hunyuan3D-Shape-v2-1 Small(0.8B)。
二、核心特性
1、训练就绪质量:网格经过清洗、归一化与 watertight/流形处理,减少非流形、破洞等训练噪声。
2、统一格式与元数据:不同子集在文件组织与字段上更一致,便于构建数据管线与评测流程。
3、Full-level 完整物体:包含 watertight meshes、多视角渲染图与采样点,适合单视图到 3D、重建与生成训练。
4、Part-level 部件级分解:提供部件标签、部件独立网格与部件装配渲染,支持细粒度可控生成、结构编辑与机器人操作相关研究。
5、Synthetic 合成长尾补齐:覆盖 1,252 个细粒度子类,面向类别不均衡与长尾泛化,适合做数据增强与零样本评估补充。
6、轻量基线:提供 0.8B 规模的 DiT 形状基线(2048/4096 tokens 版本),降低复现实验门槛。
三、安装
1、环境准备:建议使用 Linux + Python(配合 PyTorch/常见深度学习栈),并预留足够磁盘(Full 约 11TB、Part 约 5TB、Synthetic 约 6.5TB)。
2、获取数据(推荐):安装 Hugging Face CLI 后使用 hf download 拉取全量或按子集增量下载。
3、基线复现:克隆仓库,按 baselines 目录说明安装依赖并配置数据路径,即可启动训练/评测脚本。
四、典型用例
1、3D 生成训练集:扩散/GAN/自回归等 3D 生成模型的统一训练数据来源。
2、单视图/多视图到 3D:用标准化渲染视角与几何监督做重建与评测。
3、可控编辑与结构一致性:利用部件级网格与标签做“按部件生成/替换/重组”。
4、机器人与仿真资产库:以部件分解支持可供性学习、抓取规划、交互仿真。
5、长尾与类别均衡:用合成资产补齐稀有类别,提升鲁棒性与泛化对比实验的可解释性。
五、生态与竞品
1、生态:GitHub 提供数据说明与基线代码;Hugging Face 提供数据集托管与基线权重下载,便于社区复现。
2、竞品/对照:常见 3D 资产库或大规模 3D 数据集在规模上充足,但可能存在噪声、结构粒度不足、评测口径不一等问题;HY3D-Bench 的差异点在于“训练就绪清洗 + 部件级结构 + 合成长尾补齐 + 可复现轻量基线”的组合。实际优劣仍建议以你的任务指标与消融实验为准。
六、局限与注意事项
1、存储与带宽成本高:全量数据体量大,建议按子集/按需下载与分阶段训练。
2、许可证与合规:数据可能来自多源处理与再分发,务必阅读仓库许可文件与各子集的来源/分发说明,确认商用与再发布边界。
3、部件标注的适用范围:部件定义与粒度可能随类目不同而差异,做跨类泛化或结构一致性评测时应谨慎设计指标。
4、合成数据偏差:AIGC 资产可能带来风格分布偏移,建议与真实数据混合比例、类别重采样策略一起做消融。
七、项目地址
https://github.com/Tencent-Hunyuan/HY3D-Bench
八、常见问题
Q: HY3D-Bench 数据集包含哪些子集(Full-level/Part-level/Synthetic)?
A: Full-level 提供 252K+ 完整 watertight 物体与渲染/采样点;Part-level 提供 240K+ 部件级分解与装配渲染;Synthetic 提供 125K+ 合成资产覆盖 1,252 细粒度子类。
Q: HY3D-Bench 怎么下载更省空间?
A: 优先用 Hugging Face 的按路径 include 方式只拉取 full/**、part/** 或 synthetic/**,并先从小子集或验证集开始。
Q: Hunyuan3D-2.1-Small / Hunyuan3D-Shape-v2-1 Small 基线是什么关系?
A: 论文提到用 Hunyuan3D-2.1-Small 做实证验证;数据页同时提供了基于 Full-level 训练的轻量形状基线权重(0.8B)。建议以仓库 baselines 说明为准选择复现实验设置。
Q: Part-level 数据能做“按部件生成/编辑”吗?
A: 可以作为训练监督与评测基准(部件标签 + 部件网格 + 装配渲染),但部件定义与类目差异会影响可控效果,需要配合任务设计与指标。
Q: Synthetic 子集适合直接当主训练集吗?
A: 更常见的用法是补齐长尾与做数据增强;若作为主训练集,建议关注分布偏差并与真实子集混合做对照实验。