1. 초록
HY3D-Bench는 텐센트의 훈위안 팀이 만든 오픈 소스 통합 3D 자산 데이터 생태계로, 3D 생성 분야에서 흔히 겪는 "데이터 희소성, 높은 잡음, 일관성 없는 평가"라는 공통 문제를 완화하는 것을 목표로 하고 있습니다. 이 프로젝트는 세 가지 유형의 보완 데이터 하위 집합을 동시에 공개합니다: 풀레벨(252K+ 완전 객체), 파트 레벨(240K+ 컴포넌트 레벨 구조 분해), 합성(125K+ AIGC 합성 롱테일 카테고리), 그리고 경량 및 재현 가능한 베이스라인 모델인 Hunyuan3D-Shape-v2-1 Small(0.8B)을 제공합니다.
2. 핵심 특징
- 훈련 준비 품질: 메쉬는 세척, 노멀리제이션, 방수/매니폴드 처리를 거쳐 비매니폴드 및 구멍 파손 같은 훈련 소음을 줄입니다.
- 통합 형식 및 메타데이터: 하위 집합마다 파일 구성과 필드가 더 일관되어 있어 데이터 파이프라인과 평가 프로세스를 구축하기가 용이합니다.
- 완전 전체 레벨 객체: 방수 메시, 다중 뷰 렌더링 및 샘플링 포인트를 포함하여 단일 뷰에서 3D, 재구성 및 생성 훈련에 적합합니다.
- 부품 수준 컴포넌트 수준 분해: 컴포넌트 라벨, 컴포넌트 독립 메쉬 및 컴포넌트 어셈블리 렌더링을 제공하고, 세밀한 제어 생성, 구조 편집 및 로봇 운영 관련 연구를 지원합니다.
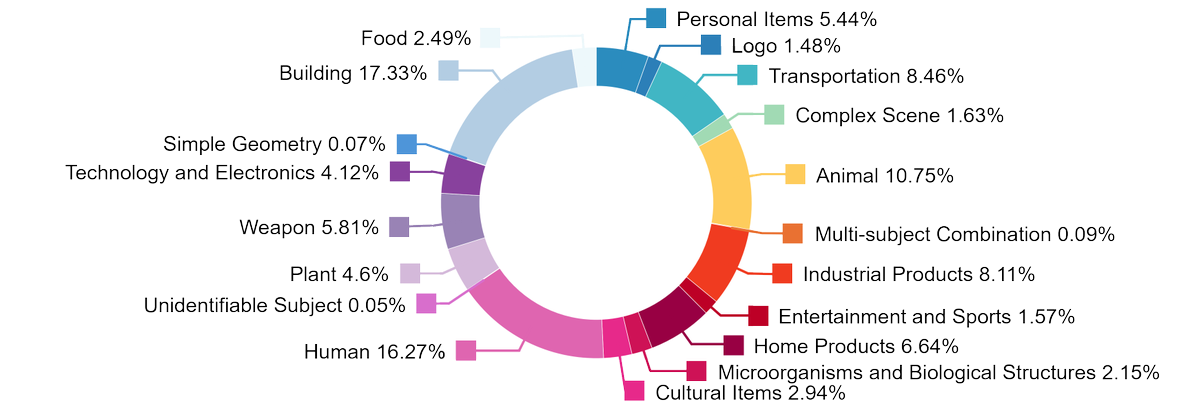
- 합성 롱테일 완성: 1,252개의 미세한 하위 분류, 범주 불균형 및 롱테일 일반화를 포괄하며, 데이터 증강 및 제로 샷 평가 보완에 적합합니다.
- 경량 기준선: 재현성 실험의 임계값을 낮추기 위해 0.8B 스케일 DiT 형태 기준선(2048/4096 토큰 버전)을 제공합니다.
3. 설치
- 환경 준비: Linux + Python(PyTorch/일반적인 딥러닝 스택 포함)을 사용하고 충분한 용량(약 11TB, 부분 약 5TB, 합성 약 6.5TB)을 예약하는 것이 권장됩니다.
2. 데이터 획득 (권장): Hugging Face CLI를 설치한 후 hf download 사용해 전체 데이터를 추출하거나 하위 단위로 다운로드하세요.
- 기준선 복제: 저장소를 복제하고, 기준선 디렉터리 설명에 따라 의존성을 설치하며, 학습/평가 스크립트를 시작하기 위한 데이터 경로를 설정합니다.
4. 일반적인 사용 사례
- 3D 생성 훈련 세트: 확산/GAN/자기회귀와 같은 3D 생성 모델을 위한 통합 학습 데이터 소스입니다.
- 단일/다중 뷰에서 3D로: 표준화된 렌더링 원근법과 기하학적 감독을 통한 재구성 및 평가.
- 제어 가능한 편집 및 구조적 일관성: 부품 수준의 그리드와 라벨을 사용하여 "부품별로 생성/교체/재조립".
- 로봇 및 시뮬레이션 자산 라이브러리: 저렴한 학습, 숙달 계획, 구성 요소 분해를 포함한 인터랙티브 시뮬레이션을 지원합니다.
- 롱테일 및 범주 균형: 합성 자산을 사용해 희귀 범주를 완성하여 일반화 비교 실험의 견고성과 설명 가능성을 향상시킵니다.
5. 생태와 경쟁 제품
- 생태학: GitHub는 데이터 설명과 기준 코드를 제공합니다; Hugging Face는 커뮤니티 재현성을 위해 데이터셋 호스팅과 기준선 가중치 다운로드를 제공합니다.
- 경쟁 제품/대조군: 일반적인 3D 자산 라이브러리나 대규모 3D 데이터셋은 규모가 충분하지만, 노이즈, 구조적 세분성 부족, 평가 수준 차이 등의 문제가 발생할 수 있습니다. HY3D-Bench의 차이는 "훈련 준비 가능한 세척 + 구성 요소 수준 구조 + 합성 롱테일 완성 + 재현 가능한 경량 기준선"의 조합에 있습니다. 실제 장단점은 과제 지표와 소작 실험에 따라 권장됩니다.
6. 제한 및 주의사항
- 높은 저장 및 대역폭 비용: 전체 데이터 용량이 크므로 하위 집합/주문형으로 단계별로 다운로드 및 학습하는 것이 권장됩니다.
- 라이선스 및 준수: 데이터는 다중 소스 처리 및 재배포에서 올 수 있으므로, 각 하위 집합의 저장소 라이선스 파일과 소스/배포 지침을 반드시 읽어 상업적 사용과 재배포 경계를 확인하세요.
- 구성 요소 라벨링 적용 범위: 구성 요소 정의와 세분화는 범주에 따라 다를 수 있으므로, 클래스 간 일반화나 구조적 일관성 평가를 수행할 때 설계 지표는 신중하게 설계되어야 합니다.
- 합성 데이터 편향: AIGC 자산은 스타일 분포 변화를 일으킬 수 있으므로, 실제 데이터 혼합 비율 및 카테고리 재샘플링 전략과 함께 이를 완화하는 것이 권장됩니다.
7. 프로젝트 주소
https://github.com/Tencent-Hunyuan/HY3D-Bench
8. 자주 묻는 질문
Q: HY3D-Bench 데이터셋에는 어떤 하위 집합(풀레벨/파트 레벨/합성)이 포함되어 있나요?
A: 풀레벨은 렌더링/샘플링 포인트가 있는 252K+ 완전 방수 객체를 제공합니다; 파트 레벨은 240K+ 파트 레벨 분해 및 어셈블리 렌더링을 제공합니다; Synthetic은 1,252개의 세분화된 하위 클래스에 걸쳐 125K+ 합성 자산을 제공합니다.
Q: 공간을 절약하기 위해 HY3D-Bench를 어떻게 다운로드할 수 있나요?
A: Hugging Face의 per-path include 메서드를 사용하여 full/**, part/**, synthetic/**만 끌어오고, 작은 부분집합이나 검증 세트부터 시작하는 것을 선호합니다.
Q: Hunyuan3D-2.1-Small / Hunyuan3D-Shape-v2-1 Small 기준선의 관계는 무엇인가요?
답변: 논문에서는 경험적 검증을 위해 Hunyuan3D-2.1-Small을 사용한다고 언급합니다; 데이터 페이지는 또한 풀 레벨 훈련을 기반으로 한 경량 형태 기준 체중(0.8B)도 제공합니다. 재생산 실험 설정은 저장소 기준선 설명을 기준으로 선택하는 것이 권장됩니다.
Q: 부품 수준 데이터를 "부품에 의해 생성/편집"할 수 있나요?
A: 교육 감독 및 평가 벤치마크(부품 라벨 + 부품 메시 + 조립 렌더링)로 사용할 수 있지만, 부품 정의와 카테고리의 차이가 제어 가능한 효과에 영향을 미치므로 작업 설계 및 지표와 조율해야 합니다.
Q: Synthetic 하위 집합은 직접 마스터 훈련 세트에 적합한가요?
A: 더 일반적인 사용법은 롱테일을 채우고 데이터 향상을 하는 것입니다; 만약 이 부분을 주 훈련 세트로 사용할 경우, 분포 편향에 주의를 기울이고 실제 부분집합과 대조 실험에 혼합하는 것이 권장됩니다.