一、摘要
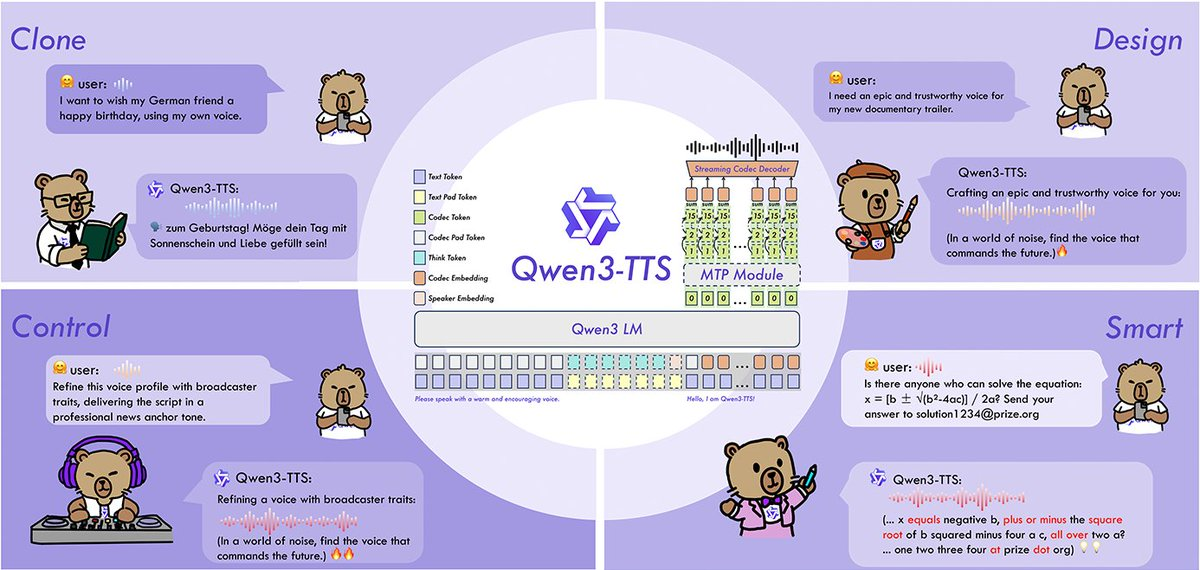
Qwen3-TTS 是 Qwen 团队开源的文本转语音(TTS)模型系列,包含 VoiceDesign(文字描述生成新音色)、CustomVoice(指令控制既定高质量音色)与 Base(快速音色克隆与微调基座)。项目同时开源代码与权重,并提供 12Hz 语音 tokenizer 以实现更高压缩与流式合成能力,面向实时对话、配音与个性化语音等场景。
二、核心特性
1、全家族能力覆盖:VoiceDesign(自由语音设计)、CustomVoice(定制音色与风格控制)、Base(3 秒级快速音色克隆、可用于全量微调)。
2、两档规模:已发布模型覆盖约 0.6B 与 1.7B 两个参数规模(部分宣传口径会写作约 1.8B,建议以仓库与模型卡标注为准)。
3、10 语言支持:中文、英文、日文、韩文、德语、法语、俄语、葡语、西语、意语,并提供多种方言/音色配置。
4、12Hz tokenizer 高压缩:以更低 token 频率表达语音,降低带宽与推理负担,适配流式与离线合成。
5、可控与鲁棒:支持用自然语言指令控制语速、情绪、韵律等,针对噪声文本与复杂输入提升稳定性。
6、全量微调路径:仓库提供 fine-tuning 相关目录与示例,便于做行业语料、品牌音色或特定口音适配。
三、安装
1、Python 环境:建议新建 Python 3.12 虚拟环境。
2、一键安装:直接安装 PyPI 包 qwen-tts;需要本地修改则克隆仓库并 pip install -e .。
3、资源优化:官方建议可选安装 FlashAttention 2 以降低显存占用;也可通过 Hugging Face / ModelScope 预下载权重到本地。
四、典型用例
1、产品/客服语音:低延迟流式播报,适配对话式助手与实时同传。
2、内容创作与配音:用指令控制情绪与语速,生成多风格旁白。
3、个性化语音:3 秒参考音频做音色克隆,用于个人助手或无障碍朗读(需确保授权)。
4、游戏与虚拟人:VoiceDesign 通过文字描述快速生成角色音色,再叠加风格控制。
5、行业微调:用自有语料做全量微调,提升术语读法、口音一致性与品牌音色稳定性。
五、生态与竞品
1、生态:提供 Hugging Face/ModelScope 模型集合与在线 Demo;本地支持 Web UI 启动;同时给出 DashScope/Model Studio 相关 API 文档;并提到 vLLM-Omni 的集成方向。
2、竞品:开源侧常见方案包括 Coqui TTS、Bark、XTTS、StyleTTS2 等,侧重点在多语言、克隆质量、可控性与部署成本上各不相同。Qwen3-TTS 的差异点更集中在“语音设计 + 克隆 + 流式低延迟 + 12Hz 高压缩 tokenizer + 微调链路”一体化。
六、局限与注意事项
1、算力与显存:更大模型与高质量输出通常更吃 GPU;流式服务还需关注并发与延迟抖动。
2、音色合规:音色克隆与拟声可能涉及肖像权/声音权与内容合规,务必获得授权并做好使用边界。
3、质量边界:不同语言、口音、极端情绪或超长文本下仍可能出现发音偏差与韵律不稳,建议加入人工抽检与后处理。
4、生产部署:浏览器麦克风权限、HTTPS、网关与证书配置会影响 Demo/服务可用性,需按官方说明处理。
七、项目地址
https://github.com/QwenLM/Qwen3-TTS
八、常见问题
Q: Qwen3-TTS 支持哪些语言与音色?
A: 已覆盖 10 种语言,并提供多种方言/音色配置;具体以模型卡与仓库说明为准。
Q: Qwen3-TTS 的 VoiceDesign 与 Voice Clone 有什么区别?
A: VoiceDesign 用文字描述“设计”新音色;Voice Clone 用短参考音频(如 3 秒)复制目标说话人音色。
Q: Qwen3-TTS 12Hz tokenizer 的价值是什么?
A: 更低频率的语音 token 表达可带来更高压缩与更低延迟潜力,适配流式实时合成与成本控制。
Q: Qwen3-TTS 能不能做全量微调(fine-tuning)?
A: 可以,仓库提供 fine-tuning 相关代码与示例流程,适合做行业语料与品牌音色适配。
Q: Qwen3-TTS 如何快速体验 Demo?
A: 可用 Hugging Face/ModelScope 在线 Demo,或本地安装 qwen-tts 后启动官方 Web UI 命令进行体验。



