1. 要旨
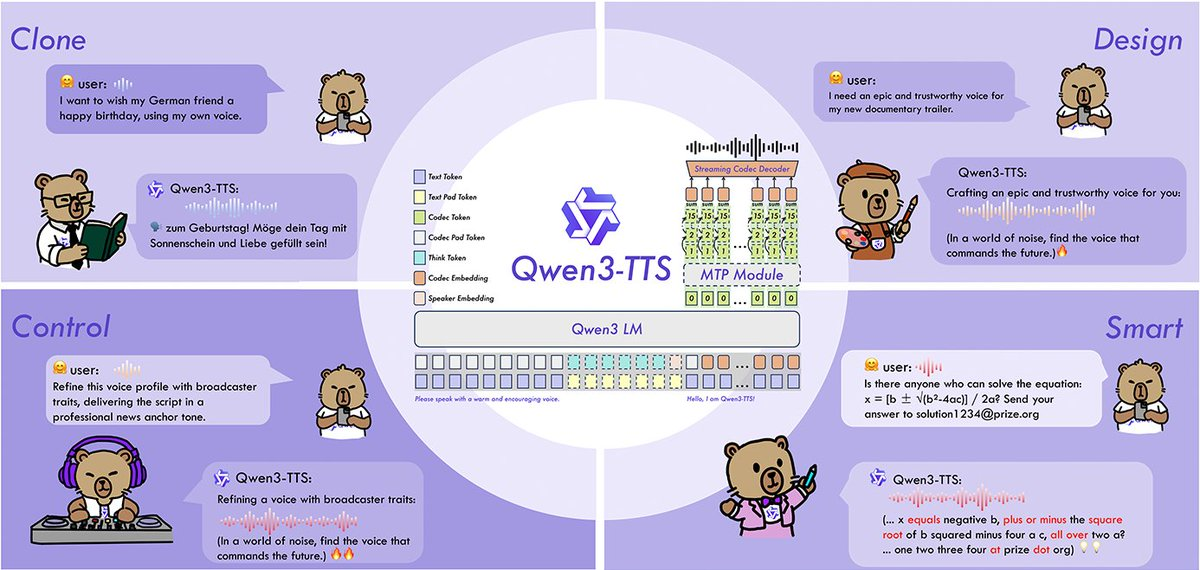
Qwen3-TTSは、Qwenチームによるオープンソースのテキスト読み上げ(TTS)モデル群で、VoiceDesign(テキスト説明から新しい音声を生成する)、CustomVoice(あらかじめ決められた高品質音声のコマンド制御)、Base(高速音声クローン作成および基礎の微調整)などが含まれます。 このプロジェクトはコードとウェイトの両方をオープンソース化し、12Hzの音声トークナイザーを提供して、リアルタイムの会話、吹き替え、パーソナライズされたボイスシナリオのために、より高い圧縮率とストリーミング合成能力を実現しています。
2. コア機能
1. ファミリー全体対応カバレッジ:VoiceDesign(無料のボイスデザイン)、CustomVoice(カスタム音色とスタイル制御)、Base(3秒間の高速音色クローン、フルファインチューニングに使用可能)。
2. 2つのスケール:公開モデルは約0.6Bおよび1.7Bのパラメータをカバーしています(一部の宣伝用キャリバーは約1.8Bと表記されるため、倉庫およびモデルカードの表示を参照することを推奨します)。
3. 10 言語サポート:中国語、英語、日本語、韓国語、ドイツ語、フランス語、ロシア語、ポルトガル語、スペイン語、イタリア語で、複数の方言・音色構成を提供します。
4. 12Hzトークナイザー高圧縮:低トークン周波数で音声を表現し、帯域幅と推論負荷を削減し、ストリーミングやオフライン合成に適しています。
5. 制御可能で堅牢:自然言語コマンドを用いて話す速度、感情、韻律などを制御し、ノイズの多いテキストや複雑な入力の安定性を向上させること。
6. 完全なファインチューニングパス:倉庫は関連するカタログや例のファインチューニングを提供し、業界コーパス、ブランドの音色、特定のアクセント適応に適しています。
3. 設置
- Python環境:新しいPython 3.12仮想環境の作成が推奨されます。
2. ワンクリックインストール:PyPIパッケージを直接インストールqwen-tts; ローカルな修正が必要な場合は、リポジトリをクローンしてpip install -e .してください。
- リソース最適化:公式の推奨はメモリ使用量を減らすためにFlashAttention 2をインストールすることです。 重さはHugging FaceやModelScopeからローカルで事前ダウンロードすることも可能です。
4. 典型的なユースケース
- 製品/カスタマーサービスボイス:低遅延ストリーミング放送、会話アシスタントおよびリアルタイム同時通訳に適応。
- コンテンツ制作と吹き替え:感情や話し方の速度をコントロールするコマンドを使い、多様なスタイルのナレーションを生成します。
- パーソナライズ音声:音色クローン作成のための3秒間の参照音声で、パーソナルアシスタントまたはバリアフリーリーディング(承認が必要)。
- ゲームと仮想人間:VoiceDesignはテキストの説明を通じてキャラクターの音色を素早く生成し、その後スタイルコントロールを重ね合わせます。
- 業界のファインチューニング:独自のコーパスを使って用語の読み方、アクセントの一貫性、ブランドの音色の安定性を向上させる完全なファインチューニングを行います。
5. 生態系と競合製品
- エコシステム:Hugging Face/ModelScopeモデルコレクションとオンラインデモの提供; ネイティブでWeb UIのローンチをサポートしています。 同時に、DashScope/Model Studioに関連するAPIドキュメントも提供してください。 そしてvLLM-Omniの統合方向についても言及しました。
- 競合製品:オープンソース側でよく見られるソリューションには、Coqui TTS、Bark、XTTS、StyleTTS2などがあり、多言語性、クローン品質、管理可能性、導入コストに焦点を当てています。 Qwen3-TTSの違いは、「音声デザイン+クローン+ストリーミング低遅延+12Hz高圧縮トークナイザー+ファインチューニングリンク」の統合により焦点が当てられています。
6. 制限事項と注意事項
- 計算能力とビデオメモリ:大型モデルや高品質な出力は通常、より多くのGPUを消費します。 ストリーミングサービスも並行処理や遅延のジッターに注意を払う必要があります。
- 音色の遵守:音色のクローンや擬音語は肖像権や音色権、内容の遵守を伴うことがあるため、必ず許可を取得し、使用境界をしっかり守ってください。
- 品質の境界:発音の偏差や韻律の不安定さは、異なる言語、アクセント、極端な感情、または超長いテキストでも依然として発生する可能性があるため、手動サンプリングと後処理の追加が推奨されます。
- 本番展開:ブラウザのマイク権限、HTTPS、ゲートウェイ、証明書の設定はデモやサービスの利用可能性に影響し、公式の指示に従って処理する必要があります。
7. プロジェクトアドレス
https://github.com/QwenLM/Qwen3-TTS
8. よくある質問
Q: Qwen3-TTSはどのような言語や音声をサポートしていますか?
A: 10言語をカバーし、複数の方言・音色構成が利用可能です。 具体的な詳細はモデルカードと倉庫の説明に従属します。
Q: Qwen3-TTSのVoiceDesignとVoice Cloneの違いは何ですか?
A: VoiceDesignは新しい音の「デザイン」を言葉で表現します。 Voice Cloneは、3秒などの短い参照音声でターゲットスピーカーの音色を再現します。
Q: Qwen3-TTS 12Hzトークナイザーの価値はどのくらいですか?
A: 低周波の音声トークン表現は、より高い圧縮率と低遅延の可能性をもたらし、ストリーミングのリアルタイム合成やコスト管理に適しています。
Q: Qwen3-TTSはファインチューニングが可能ですか?
A: はい、倉庫では業界コーパスやブランドのトーン適応に適した、コードやサンプルプロセスの微調整を提供しています。
Q: Qwen3-TTSはデモをどのように迅速に体験していますか?
A: Hugging FaceやModelScopeのオンラインデモを使うか、ローカルインストール後に公式のウェブUIコマンドを起動して体験qwen-ttsできます。



