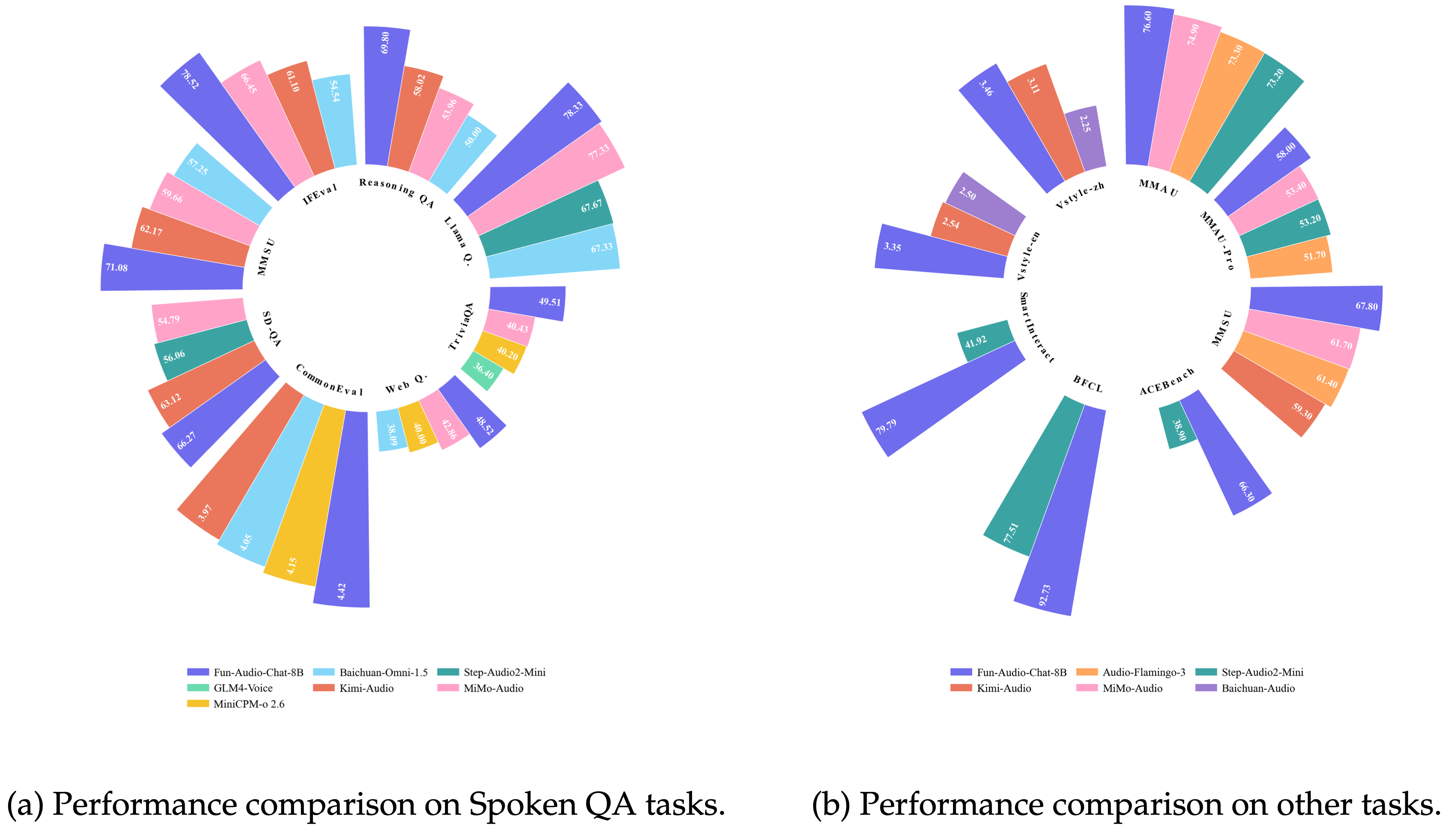
Qwen发布Qwen3-TTS新阵容,推出VoiceDesign-VD-Flash与VoiceClone-VC-Flash两条能力线:前者以“自由文本指令”对语气、节奏、情绪与人设进行细粒度控制,强调不依赖预设音色;后者主打仅需约3秒音频即可进行声音克隆,并在多语言生成与更自然的语速停连上强化表现。官方宣传称,两者在部分角色扮演与多语评测中优于若干竞品或同类系统。
从适用范围看,VoiceClone-VC-Flash宣称可生成10种语言语音(含中英日西等),并给出相对WER下降等指标,但公开口径未必覆盖全部数据集、噪声条件与评测流程,实际效果可能随口音、录音质量、文本领域而波动。相关能力已在Qwen Chat与公开演示页面展示,开发者侧亦可参考云端模型与TTS文档;同时,语音克隆涉及肖像权、隐私与授权边界,使用样本与生成内容需确保获得明确同意并避免冒充风险。
常见问题
Q:这次Qwen3-TTS新增的VoiceDesign与VoiceClone分别解决什么问题?
A:VoiceDesign用于用文本指令“设计与控制”声音风格;VoiceClone用于用短音频样本快速复刻特定说话人音色并多语言合成。
Q:VoiceClone-VC-Flash进行3秒语音克隆对音频有什么要求?
A:通常需要清晰人声、较少背景噪声与失真;样本越干净、说话越稳定,克隆相似度与可懂度一般越好。
Q:VoiceClone-VC-Flash支持哪些语言与常见限制是什么?
A:官方宣称支持10种语言(含中文、英文、日文、西班牙语等);跨语言时可能出现口音迁移、个别专名读音偏差与可懂度波动。
Q:使用语音克隆功能最容易踩到哪些风险点?
A:未经授权克隆他人声音、用于冒充或误导传播;以及将含个人敏感信息的音频样本上传到不明环境。