1. 추상
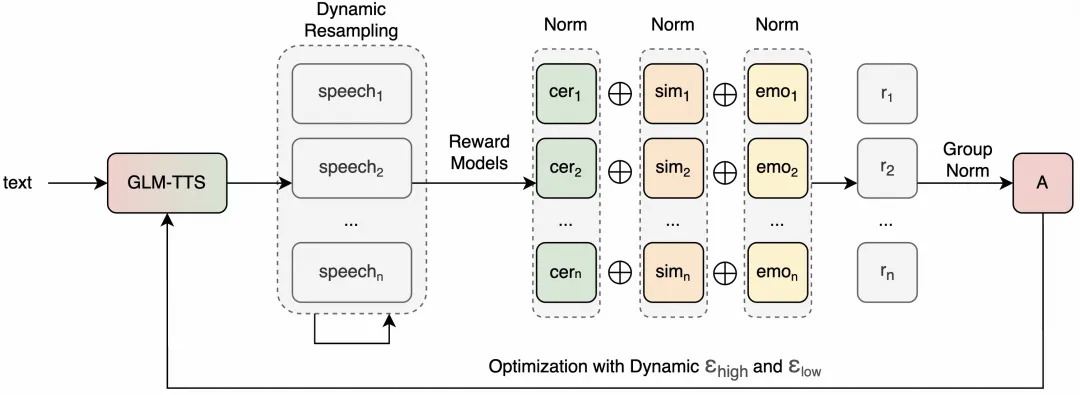
GLM-TTS는 산업용 음성 생성을 위한 오픈소스 TTS 시스템으로, 음성 샘플의 음색 복제를 단 3초 만에 지원하고 감정 표현을 제어할 수 있습니다. 아키텍처는 2단계 생성 과정을 채택하며, 문자 오류율(CER)과 감성 측면에서 오픈 소스 중 선도적인 수준을 달성하는 GRPO 기반 강화 학습 메커니즘을 도입합니다. 이 프로젝트는 낮은 교육 비용과 높은 확장성을 강조하며, 교육, 전자책, 오디오 콘텐츠, 지능형 고객 서비스 등 다양한 상황에 적합합니다.
2. 핵심 특징
1. 빠른 음색 복제: 3초에 불과한 발화를 바탕으로 개별 음색과 말하는 스타일을 학습합니다.
2. 2단계 생성 아키텍처: 분리 지속 시간, 리듬, 보코더 모듈을 통해 안정성과 제어성을 향상시킵니다.
3. 감정 표현 조절: 행복, 슬픔, 분노 등 다양한 감정을 지원하며, 긴 텍스트 독서와 캐릭터 묘사 장면에 적합합니다.
4. GRPO 강화 학습은 표현력 향상: CER을 감소시키고, 음색 유사성을 개선하며, 다차원적 보상을 통해 감정적 수행을 향상시킵니다.
5. 낮은 교육 및 추론 비용: 100,000시간의 데이터 교육, 그리고 사전 학습은 단일 기계에서 4일 만에 완료할 수 있습니다; 톤 LoRA와 RL 교육도 단일 기계에서 하루 만에 완료할 수 있습니다.
6. 다중 플랫폼 오픈 소스 및 추론 예시: GitHub, Hugging Face, ModelScope 등 완전한 자원을 제공하여 기업 구현을 용이하게 합니다.
3. 설치
- 저장소 복제:
git clone https://github.com/zai-org/GLM-TTS
- 의존성 설치:
저장소에서 제공하는 환경 파일이나 샘플 스크립트에 따라 파이썬 및 딥러닝 프레임워크를 구성합니다.
- 모델 무게 다운로드:
기본 모델, 프리미엄 음색, RL 버전의 무게는 ModelScope나 Hugging Face에서 받을 수 있습니다.
- 추론 배포:
GPU 환경에서 텍스트 음성 변환, 음색 재생, 파라메트릭 제어를 지원하는 샘플 추론 스크립트를 실행합니다.
4. 일반적인 사용 사례
1. 교육 시나리오: 교과서, 문제은행, 평가 과제의 표준 발음을 생성하고, 다음절 단어, 공식 기호, 희귀 단어에 적응합니다.
2. 전자책 및 오디오 콘텐츠: 장편 읽기를 지원하며, 등장인물마다 다른 음색과 감정 스타일로 제본할 수 있습니다.
3. 지능형 고객 서비스: 절제되고 전문적인 고객 서비스 톤을 생성하여 가변 정보를 자연스럽게 스크립트에 삽입하고 일관된 리듬을 유지할 수 있습니다.
4. 음색 재현 및 콘텐츠 제작: 팟캐스트, 오디오 해설, 짧은 영상 제작을 위해 저자, 앵커 또는 내레이터의 음색을 빠르게 복제합니다.
5. 생태계와 경쟁자
1. 생태계: 가중치, 추론 스크립트, API 문서, 온라인 경험 포털을 제공하여 개발자가 로컬 또는 클라우드에 배포할 수 있도록 지원합니다.
2. 경쟁사 비교: VITS, CosyVoice, FishSpeech 등과 같은 오픈소스 TTS 모델과 비교할 때, GLM-TTS는 CER, 감정 표현, 저비용 교육에서 우위를 가지고 있습니다; 하지만 구체적인 효과는 비즈니스 텍스트 유형, 음향 조건, 추론 구성에 따라 달라집니다.
6. 제한 및 주의사항
- 감정 제어는 훈련 데이터의 품질에 의존하며, 일부 복잡하거나 혼합된 감정은 여전히 불안정하다.
- 긴 텍스트와 실시간 음성 상호작용에서는 운율적 일관성이 추론 속도와 맥락적 전략에 의해 제한될 수 있습니다.
- 음성 복제는 데이터 승인 요건을 준수해야 하며, 무단 음향 재생에 사용해서는 안 됩니다.
- 플랫폼별로 가중치에 약간의 차이가 있을 수 있으며, 해당 모델 버전을 적용 시나리오에 따라 선택해야 합니다.
7. 프로젝트 주소
https://github.com/zai-org/GLM-TTS
8. 자주 묻는 질문
Q: GLM-TTS 음성 복제에는 얼마나 많은 음성이 필요한가요?
A: 음색 복제를 완성하기 위해 3초 샘플을 지원하지만, 더 긴 샘플은 안정성을 향상시킬 수 있습니다.
Q: 감정 조절에 도움이 되나요?
A: Happy, Sad, Angry 등과 같은 감정 태그를 지지하고, 공개 리뷰에서 앞장서세요.
Q: 추론의 비용은 무엇인가요?
A: 추론은 독립형 GPU 환경에서 수행할 수 있으며, 대규모 콘텐츠 라이브러리의 배치 합성에 적합합니다.
Q: 이 모델이 상업적 배포에 적합한가요?
A: Apache 라이선스 하에 오픈 소스이며, 사운드 라이선스 사양을 조건으로 연구 및 상업적 시나리오에 자유롭게 사용할 수 있습니다.
Q: 온라인 API가 있나요?
답변: 네. 텍스트 음성 변환 및 음색 재생 인터페이스는 오픈 플랫폼을 통해 제공됩니다.