1. Abstract
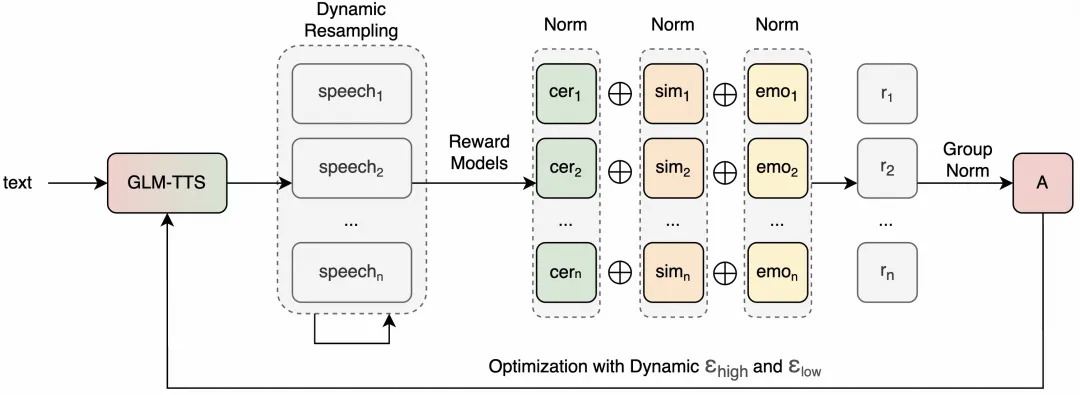
GLM-TTS is an open-source TTS system for industrial-grade speech generation, supporting timbre cloning of voice samples in just 3 seconds and providing controllable emotional expression. Its architecture adopts a two-stage generation process and introduces a GRPO-based reinforcement learning mechanism, which achieves the leading level of open source in the dimensions of character error rate (CER) and sentiment. The project emphasizes low training costs and high scalability, and is suitable for scenarios such as education, e-books, audio content, and intelligent customer service.
2. Core Features
1. Fast Timbre Cloning: Learn individual timbre and speaking style based on speech as short as 3 seconds.
2. Two-stage generation architecture: separation duration, rhythm and vocoder module to improve stability and controllability.
3. Controllable emotional expression: supports a variety of emotions such as happiness, sadness, anger, etc., and is suitable for long text reading and characterization scenes.
4. GRPO Reinforcement Learning Enhances Expressiveness: Reduces CER, improves timbre similarity, and enhances emotional performance through multi-dimensional rewards.
5. Low training and inference cost: 100,000 hours of data training, and the pre-training can be completed in 4 days on a single machine; Tone LoRA and RL training can also be completed in 1 day on a single machine.
6. Multi-platform open source and inference examples: Provide complete resources such as GitHub, Hugging Face, and ModelScope to facilitate enterprise implementation.
3. Installation
- Clone the repository:
git clone https://github.com/zai-org/GLM-TTS
- Install dependencies:
Configure Python and deep learning frameworks according to the environment files or sample scripts provided by the repository.
- Download model weights:
You can get the weights of the base model, premium timbre, and RL version from ModelScope or Hugging Face.
- Inference Deployment:
Run sample inference scripts in a GPU environment, supporting text-to-speech, timbre reproduction, and parametric control.
4. Typical use cases
1. Educational scenarios: Generate standard pronunciation for textbooks, question banks, and evaluation tasks, and adapt to multi-syllable words, formula symbols, and rare words.
2. E-books and audio content: Support long-form reading, and different characters can be bound with different timbres and emotional styles.
3. Intelligent customer service: Generate restrained and professional customer service tones, which can naturally insert variable information into the script and maintain consistent rhythm.
4. Timbre reproduction and content creation: Quickly clone the timbre of the author, anchor or narrator for podcasts, audio commentary and short video production.
5. Ecology and competitors
1. Ecosystem: Provide weights, inference scripts, API documentation, and online experience portals to facilitate developers to deploy locally or in the cloud.
2. Comparison of competitors: Compared with open-source TTS models (such as VITS, CosyVoice, FishSpeech, etc.), GLM-TTS has advantages in CER, emotional expression, and low-cost training; However, the specific effect depends on the business text type, acoustic conditions, and inference configuration.
6. Limitations and precautions
- Emotion control depends on the quality of training data, and some complex or mixed emotions are still unstable.
- In long text and real-time voice interactions, prosodic consistency may be limited by reasoning speed and contextual strategy.
- Voice cloning must comply with data authorization requirements and shall not be used for unauthorized sound reproduction.
- There may be slight differences in the weights of different platforms, and the corresponding model version needs to be selected according to the application scenario.
7. Project Address
https://github.com/zai-org/GLM-TTS
8. FAQs
Q: How much voice is required for GLM-TTS voice cloning?
A: Support for 3-second samples to complete timbre replication, but longer samples can improve stability.
Q: Does it support emotion control?
A: Support sentiment tags like Happy, Sad, Angry, etc., and lead the way in public reviews.
Q: What is the cost of inference?
A: Inference can be completed in a stand-alone GPU environment, which is suitable for batch synthesis of large-scale content libraries.
Q: Is the model suitable for commercial deployment?
A: It is open-source under the Apache License and can be freely used for research and commercial scenarios, subject to the sound licensing specifications.
Q: Is there an online API available?
A: Yes. Text-to-speech and timbre reproduction interfaces are available through the open platform.