I. 要約
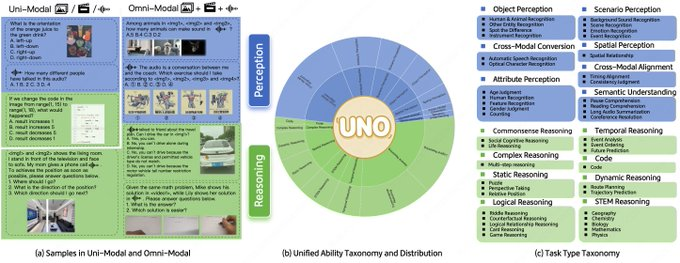
UNO-Benchは、「単一モデル/完全モデル」の質問の統合評価のためのオープンソースベンチマークであり、知覚と推論の両方の側面をカバーしています。中国語の実世界シナリオ問題と、多段階の自由回答形式の質問応答(MO)問題を提供します。データとツールは、高品質と人間主導の構築を重視しており、自動評価のための汎用的なスコアリングモデルを備えています。
II. コア機能
- 統合機能フレームワーク: 44 種類のタスク、5 つのモードの組み合わせ、単一モード タスクとフルモード タスクで同じ指標レベル。
- 高品質と解決可能性: 1,250 個のフルモーダル データ ポイント、人間によるレビュー済みの構築、モダリティ全体で 98% 解決可能。
- 効率の最適化: 18 個の公開ベンチマークの自動圧縮により、評価が約 90% 高速化され、一貫性が約 98% 向上します。
- より現実的な質問タイプ: 複雑な推論チェーンをカバーするために、複数ステップの自由形式の質問と回答が追加されました。
- 一般的なスコアリング: 6 種類の質問をサポートし、OOD シナリオでの注釈の一貫性は約 95% です。
- 主な調査結果: 強力なモデルは「べき乗法則の相乗効果」を示します (機能はモードの組み合わせによって乗法的に増加します)。
III. インストール
1. データセット: datasets.load_dataset("meituan-longcat/UNO-Bench") デフォルトのシャードを取得します。
- ソース コードとドキュメント: クローンされた GitHub リポジトリ内の README と評価スクリプトの例を表示します。
- 環境: Python/Transformers/Datasets。標準的な環境で十分です。リポジトリの指示に従って依存関係をインストールしてください。
IV. 典型的なユースケース
- モデルの横断的評価:統一された尺度で単一モデルと完全モデルの違いを比較します。
- 中国語シナリオ検証:現実生活/文化/社会状況における認識力と推論能力。
- 推論連鎖分析: 複数ステップの自由形式の質問応答を使用して、長連鎖推論の弱点を診断します。
- RAG/マルチモーダル システム: オーディオ、画像、ビデオの融合による全体的な利点を検証します。
V. 生態と競合相手
- エコシステム: データセット、リーダーボード、論文を提供します。ツールチェーンは現在開発中です。
- 競合製品: MMBEC、MMMU、MathVista などの視覚的/主題固有のベンチマークと比較して、UNO-Bench は「シングルモードからフルモードまでの統一された評価」と実際の中国語のシナリオを重視しており、その圧縮方式により複数のベンチマークの迅速な調整が容易になります。
VI. 制限事項と注意事項
- 自動圧縮の適用可能性はタスクごとに検証する必要があり、一部のサブタスクでは十分な情報が不足している可能性があります。
- 一般的なスコアリング モデルでは、長い回答や生成出力に対して依然としてバイアスがかかっている可能性があるため、サンプルを手動で確認することをお勧めします。
- 現在は中国語のシナリオに重点を置いており、多言語拡張や英語版の協力も求めています。
- 「べき乗則シナジー」は経験的な発見であり、新しいタスクに移行する際には再検証が必要です。
VII. プロジェクト住所
https://github.com/meituan-longcat/UNO-ベンチ
VIII. よくある質問
Q: UNO-Bench はどのようなモダリティとタスクをカバーしていますか?
A: 音声、画像、ビデオの組み合わせをカバーし、合計 5 つのモーダルの組み合わせと 44 のタスク カテゴリがあり、知覚と推論の両方の次元を対象としています。
Q: UNO-Bench ベンチマークをすばやく実行するにはどうすればよいですか?
A: Hugging Face 経由でデータをロードし、リポジトリのサンプル スクリプトと一般的なスコアリング モデルを使用して推論とスコアリングを実行します。
Q: 自動圧縮は結果の信頼性にどの程度影響しますか?
A: 公開されている 18 個のベンチマーク全体でランキングの一貫性は約 98% に維持されていますが、それでも元のセットのサンプリングと組み合わせることをお勧めします。
Q: 英語や複数の言語をサポートしていますか?
A: 現在、公式的には中国語版に重点を置いており、英語版や多言語版を共同開発するパートナーを探しています。
Q: べき乗法則コラボレーションはすべてのモデルに当てはまりますか?
A: これは主に強力なモデルで顕著ですが、弱いモデルの場合は「最弱リンク効果」のようなもので、具体的に評価および確認する必要があります。