1. 초록
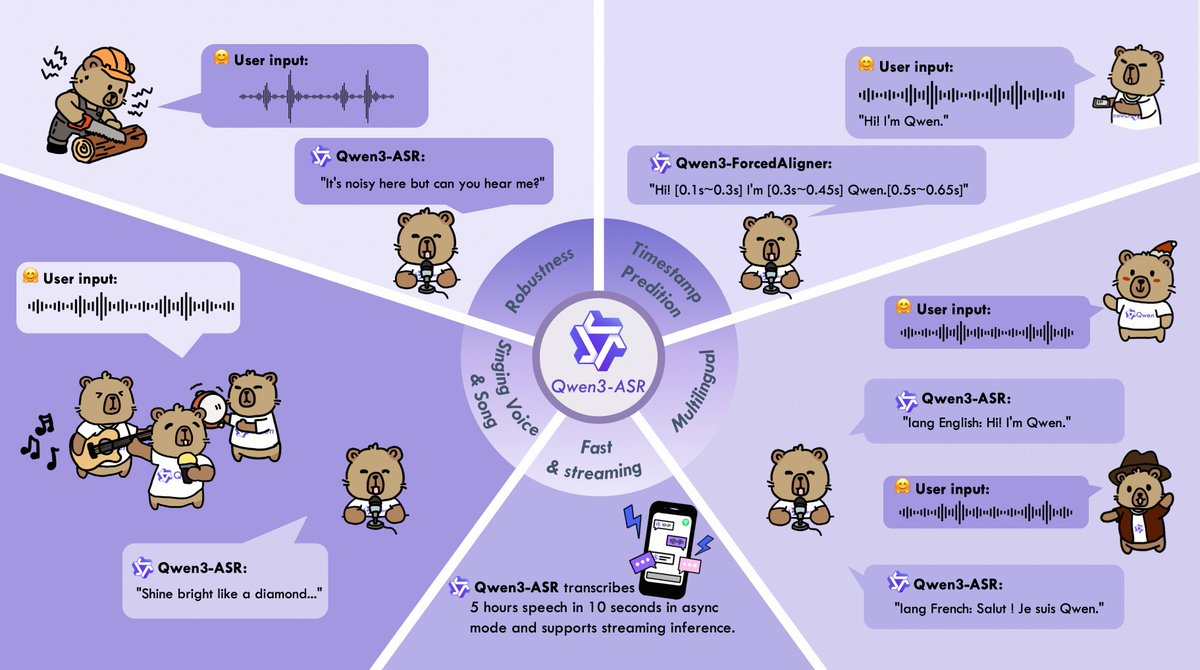
Qwen3-ASR과 Qwen3-ForcedAligner는 "노이즈, 복잡, 통제 불가능한" 실제 녹음 시나리오를 위한 오픈소스 음성 모델과 정렬 구성 요소입니다. 이들은 다국어 자동 인식, 노이즈 및 잔향에 대한 견고성, 최대 약 20분의 긴 오디오 처리, 특정 언어에서 단어/구절 수준의 고정밀 타임스탬프 정렬 기능에 중점을 두고 있으며, 배치 전사, 스트리밍 자막 제작, 온라인 서비스를 위한 오픈 소스 추론 및 미세 조정 엔지니어링 스택을 갖추고 있습니다.
2. 핵심 특징
- 다국어 및 자동 언어 인식: 52개 언어 및 방언/악센트(30개 언어 + 22개 방언/억양)를 커버하며, 자동 언어 식별(Language ID)을 지원합니다.
- 복잡한 오디오 견고성: 잡음, 다인, 원거리, 잔향 및 기타 상황에 최적화; 또한 보컬이나 노래 클립 같은 보다 '비정형적인' 오디오 형식도 다룹니다.
- 긴 오디오 지원: 단일 처리가 최대 약 20분까지 소요될 수 있어, 긴 녹음 세분화로 인한 맥락 단절과 엔지니어링 복잡성을 줄입니다.
- 단어/구문 단위 타임스탬프: Qwen3-ForcedAligner를 통해 11개 언어에서 고정밀 정렬을 제공하여 자막, 검색 및 검토 과정에서 사용자 친화적으로 만듭니다.
- 엔지니어링 스택: vLLM 배치 처리, 스트리밍 및 비동기 서비스 기능을 포함한 완전하고 오픈소스 추론 및 미세 조정 시스템을 제공하여 온라인 접속과 테스트를 용이하게 합니다.
3. 설치
- 코드 획득: 저장소를 복제한 후 README를 눌러 의존성을 설치하세요(격리된 환경과 고정된 버전을 사용하는 것이 권장됩니다).
- 가중치 획득: Hugging Face 또는 ModelScope에서 적절한 모델과 구성을 선택하세요.
- 운영 모드: 시나리오에 따라 배치 오프라인 전사(배치), 온라인 스트리밍(스트리밍) 또는 비동기 서빙(비동기 서빙)을 선택하고, 처리량에 따라 동시성 및 큐를 구성합니다.
4. 일반적인 사용 사례
- 콜센터/컨퍼런스 전사: 소음, 억양, 다중 화자의 경우 배치 전사 및 품질 검사 샘플링.
- 자막 제작 및 재생 검색: ForcedAligner를 사용해 단어/구문 단위 타임스탬프를 생성하고, "도트 점프"를 지원하며, 팔로우 하이라이트 표시, 클립 리뷰를 수행합니다.
- 짧은 비디오 및 음악 자료 처리: 배경 음악, 명확한 리듬 또는 노래 클립이 포함된 자료를 전사하고 설명하는 출력물.
- 긴 녹음 아카이빙: 10–20분 분량의 오디오에 대해 타임스탬프와 결합하여 핵심 지점을 빠르게 찾기 위한 세분화 전략을 단순화합니다.
- 엣지-투-클라우드 혼합: 엣지 엔드가 초기 스크리닝 또는 노이즈 감소 전처리를 수행하며, 클라우드는 배치/비동기 서비스를 이용해 중앙에서 전사 및 정렬합니다.
5. 생태와 경쟁 제품
- 생태 입구: GitHub는 코드와 종이 자료를 제공합니다; Hugging Face / ModelScope는 모델 컬렉션과 온라인 데모를 제공하여 쉽게 평가하고 통합할 수 있습니다.
- 경쟁 제품 아이디어: '강한 정렬' 분야에서 일반적인 해결책으로는 MFA와 CTC/CIF 스타일 정렬기를 기반으로 한 정렬기가 있습니다. Qwen3-ForcedAligner는 자막과 교정의 정확성과 안정성을 최적화하는 데 위치하며, 정렬 기능을 활용할 수 있는 구성 요소로 활용됩니다. A/B 점수는 여전히 자신의 데이터셋을 사용하는 것이 권장됩니다(억양, 소음, 말투, 도메인 용어의 차이가 결과에 큰 영향을 미칩니다).
6. 제한 및 주의사항
- 컴퓨팅 파워와 비용: 다국어, 장기 오디오 및 고정밀 정렬은 추론 지연과 자원 점유를 증가시키므로 처리량 평가와 탄력적 확장 설계가 필요합니다.
- 데이터 분배 편향: 극심한 억양, 강한 잔향, 겹치는 목소리, 도메인 용어, 자원이 부족한 언어는 여전히 오식별이나 타임스탬프 드리프트를 초래할 수 있으므로, 수동 검토의 폐쇄 루프를 도입하는 것이 권장됩니다.
- 긴 오디오 전략: 20분 단일 처리가 지원되더라도, 경계 오류를 줄이기 위해 초긴 영상에서는 세그먼트, 겹치는 창, 후처리 스플라이싱을 결합하는 것이 여전히 권장됩니다.
- 정렬 언어 범위: ForcedAligner의 고정밀 정렬은 현재 11개 언어 커버리지를 강조합니다; 나머지 언어들은 문장/단락 수준의 타임스탬프로 검색하고 필요에 따라 보충할 수 있습니다.
7. 프로젝트 주소
https://github.com/QwenLM/Qwen3-ASR
8. 자주 묻는 질문
Q: Qwen3-ASR이 52개 언어와 방언에 대해 자동 언어 식별을 지원하나요?
A: 네, 30개 언어와 22개 방언/억양을 포함하며, 언어를 자동으로 인식하고 전사할 수 있습니다.
Q: Qwen3-ASR이 시끄러운 환경이나 배경 음악과 노래가 포함된 실제 오디오를 처리할 수 있나요?
A: 목표는 노이즈와 복잡한 오디오의 견고성을 향상시키는 것이며, 노래나 보컬 클립에 대한 적응도 포함되지만, 실제 영상을 샘플링하는 것이 권장됩니다.
Q: Qwen3-ASR은 한 세션에서 얼마나 오래 처리할 수 있나요?
A: Nominal은 최대 20분/시간 처리를 지원할 수 있습니다; 긴 영상은 세그먼트 및 겹치는 창 전략과 함께 사용하는 것이 권장됩니다.
Q: Qwen3-ForcedAligner의 "단어/구문 수준 타임스탬프"는 어떤 언어에서 사용 가능한가요?
답변: 현재 중점은 자막 작성, 검색, 교정에 적합한 11개 언어로 고정밀 정렬 기능을 제공하는 데 있습니다.
Q: Qwen3-ForcedAligner의 가치는 MFA/CTC/CIF 스타일 교정기와 비교했을 때 어떻게 되나요?
A: 정렬 기능을 단어/구문 수준의 타임스탬프의 정확성과 안정성에 맞춘 직접 통합된 엔지니어링 구성 요소로 만드는 데 집중합니다; 결국, 작업 데이터의 비교가 우선입니다.
Q: 프로덕션 준비가 된 추론 및 미세 조정 툴체인이 있나요?
A: vLLM 배치, 스트리밍, 비동기 서비스를 아우르는 완전한 오픈소스 스택을 제공하며, 배포와 반복이 용이하도록 관련 프로세스의 미세 조정도 포함합니다.