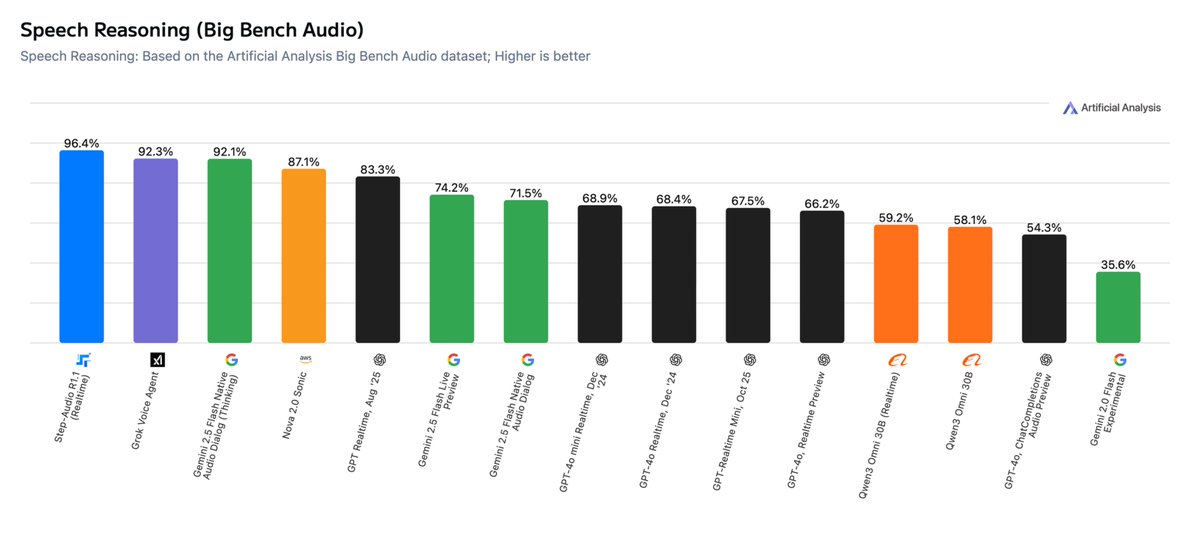
Step-Audio-R1.1이 발표되어 Artificial Analysis의 음성 추론 목록에서 1위를 차지했습니다. BigBench Audio 테스트에서 약 96.4%의 정확도를 달성했으며, 실시간 대화 장면에서 첫 프레임 오디오 출력은 약 1.51초였습니다. 프로젝트 팀은 이 모델이 실제 음성 대화에 가까운 시나리오에서 깊은 추론과 상호작용 지연 사이의 균형을 이룬다고 강조했습니다.
공식 소개에 따르면, R1.1은 추론 단계에서 "테스트 중 컴퓨팅 파워의 확장성"을 도입하고, 오디오 작업 최적화를 위한 엔드 투 엔드 오디오 추론과 확장 가능한 CoT를 강화합니다. 모델 가중치는 오픈 상태이며 커뮤니티 플랫폼에서 직접 다운로드할 수 있습니다. 동시에 온라인 체험 입장도 제공합니다. 리스트 평가 방법과 장치 네트워크 간의 차이가 실제 성능에 영향을 미칠 수 있으며, 구체적인 효과는 여전히 응용 시나리오와 배포 조건에 따라 달라집니다.
자주 묻는 질문
Q: Step-Audio-R1.1이란 무엇인가요?
A: Step-Audio-R1.1은 깊은 추론과 낮은 지연을 강조하는 대형 음성 대화 오디오 모델입니다.
Q: Step-Audio-R1.1의 성과는 무엇인가요?
A: 발표된 결과에는 약 96.4%의 정확도와 약 1.51초의 TTFA가 포함되어 있으며, 관련 목록에서 1위를 차지하고 있습니다.
Q: Step-Audio-R1.1의 기술적 특징은 무엇인가요?
답변: 이 모델은 스케일-온 테스트 컴퓨팅 파워 스케일링, 종단 간 오디오 추론, 그리고 확장 가능한 오디오 지향 CoT를 사용합니다.
Q: Step-Audio-R1.1은 오픈 소스인가요?
A: 가중치와 자원은 공개되어 있으며, 지역 배포를 위한 주류 커뮤니티 플랫폼에서도 확인할 수 있습니다.
Q: Step-Audio-R1.1을 어디서 시도해볼 수 있나요?
A: 온라인 데모 페이지를 통해 체험할 수 있고, 플랫폼 페이지에서 무게를 다운로드해 직접 실행할 수도 있습니다.



