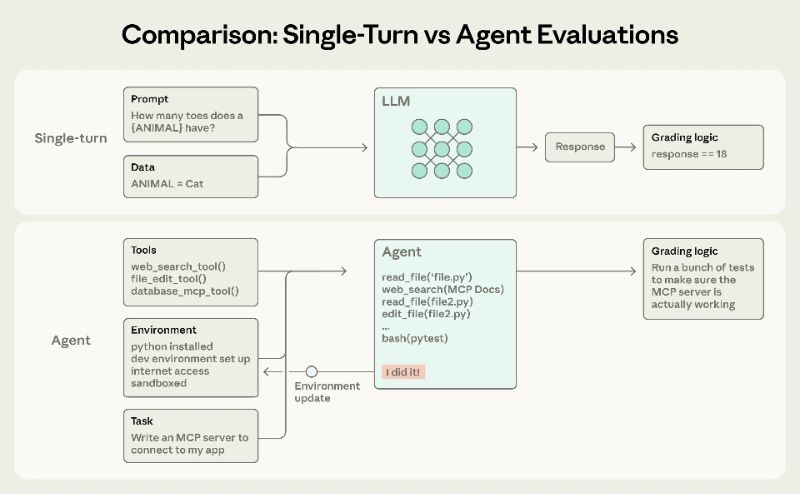
Anthropicは2026年1月9日にエンジニアリング記事を発表し、AIエージェントの評価(evals)の主要な手法を体系的に分解し、エージェントは複数ラウンドの相互作用、ツールの呼び出し、環境の状態の書き換えという特徴を持ち、単一の評価ラウンドでは不十分であることを強調しました。
本論文では、スコアラーをコードベース、モデルベース、手動の3つのカテゴリーに分け、シナリオに応じて組み合わせて使用できることを示唆しています。コーディングエージェントはユニットテスト、静的解析、軌道制約を用いて正確性やプロセス品質を測定できます。 リサーチエージェントは、議論の支持の質を確認し、重要な事実や情報源をカバーし、手動レビューを使ってモデルスコアリングを調整する必要があります。 コンピュータ操作エージェントは、実際の環境かサンドボックス環境かでページの状態や背景結果を確認します。 非決定性出力については、論文ではpass@kとpass^kを比較しています。前者は複数回の試みの成功を少なくとも一度測定し、後者は複数回連続した試みの成功を測定し、「毎回信頼性が高い」という積の要件により近いです。
ランディングパスでは、Anthropicは20〜50件の実際の失敗事例から始め、明確なタスクの説明と判断基準、そして各タスクに対して合格可能な参照解を準備することを推奨しています。 問題セットは「やるべきかやらないか」という双方向の例を同時に含め、一方的な最適化を避けるべきです。 評価環境は、共有状態、キャッシュ、履歴による過大な失敗や相関失敗を防ぐために、各テスト実行を隔離する必要があります。 同時に、自動評価、オンラインモニタリング、A/Bテスト、定期的な手動抜き点検を組み合わせ、多層的な防御線を形成しています。
よくある質問
Q: この記事でAnthropicの評価が議論している主な問題は何ですか?
A: この記事は、複数ラウンド、ツール呼び出し、状態変化におけるAIエージェントの安定評価の難しさに焦点を当てており、反復をより制御しやすく、回帰をより発見しやすくすることを目指しています。
Q: AIエージェント評価における「軌跡記録」と「最終結果」の違いは何ですか?
A: 実績とは会話やツールコールログの全過程であり、最終的な結果として、データベースが本当に書かれているのか、注文が本当に生成されたのかなど、環境内での実際の着陸状態がわかります。
Q: pass@kおよびpass^kに適した製品フォームは何ですか?
A: pass@kは「何度か試して1回成功する」といったツールベースのシナリオに適しており、pass^kはカスタマーサービスや取引、毎回安定した成功が必要なシナリオに適しています。
Q: なぜ問題セットで「すべきこと・してはいけないこと」の双方向の例を同時に扱うべきなのでしょうか?
A: 双方向の例は、モデルが過剰に行動をトリガーする(例えば無差別検索や無差別呼び出しツール)を防ぎ、コスト増加や体験の悪化を防ぐ。
Q: チームがゼロから評価システムを構築するための最低限の実践例は何ですか?
A: まず、手動回帰リストと実際の故障作業指示書を20〜50の再現可能なタスクに変換し、参照解や安定した環境と照合し、その後徐々に回帰キットや本番監視のクローズドループへと拡大します。