1. 초록
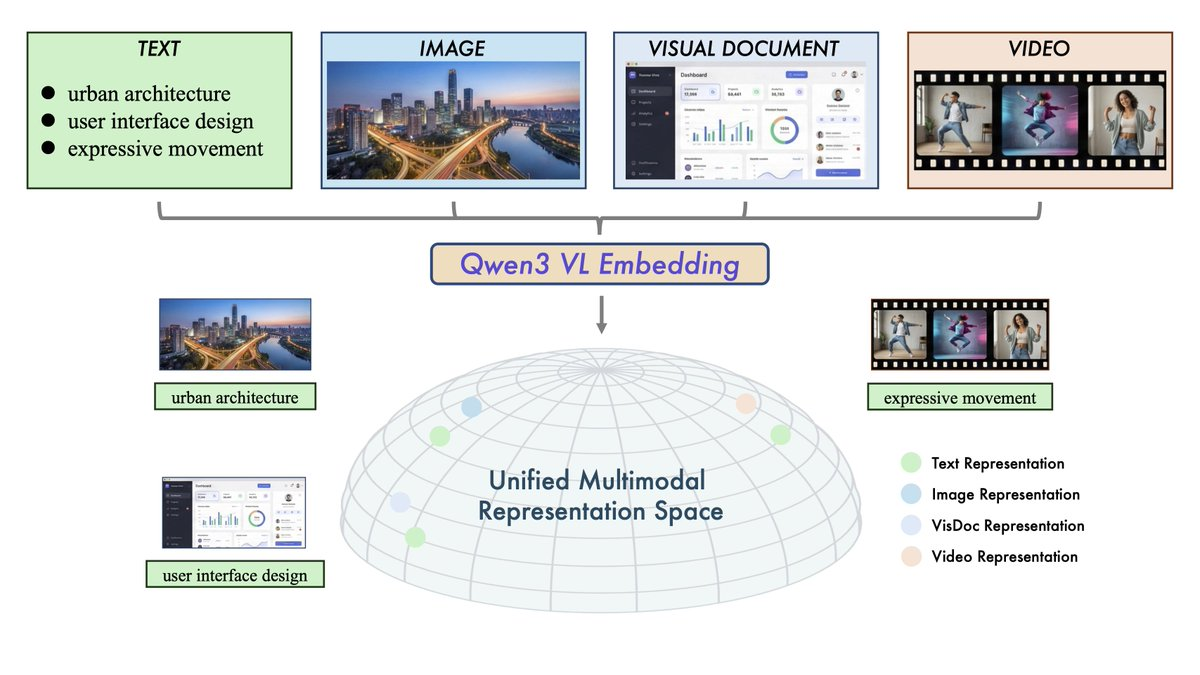
Qwen3-VL-Embedding과 Qwen3-VL-Reranker는 Qwen3-VL을 기반으로 한 오픈 소스 멀티모달 검색 모델 시리즈로, "텍스트 + 이미지 + 스크린샷 + 비디오 + 혼합 입력"의 교차 모달 이해 및 검색을 목표로 합니다. 전체적인 2단계 아키텍처가 채택되었습니다: 대규모 벡터 회상에는 임베딩(Embedding)이 사용되고, Reranker는 최종 검색 정확도를 높이고 30+ 언어 시나리오를 커버하기 위해 세밀한 상관 점수를 얻는 데 사용됩니다.
2. 핵심 특징
- 다중 모달 입력 통합: 동일한 프레임워크가 텍스트, 이미지, 스크린샷, 동영상 및 혼합 모달리를 처리합니다.
- 2단계 검색 패러다임: 임베딩은 효율적인 회상을 담당하며; Reranker는 미세 정렬과 오류 수정을 담당합니다.
- 구성 가능한 벡터 차원: 임베딩은 효과와 비용 균형을 맞추기 위해 주로 사용되는 유연한 출력 차원을 지원합니다.
- 맞춤형 명령어: "검색/클러스터링/VQA/다중 모달 RAG"와 같은 다양한 타겟을 작업 명령어를 통해 조정할 수 있습니다.
- 양자화 및 공학적 친화성: 저장 및 검색 비용을 줄이기 위해 임베딩 출력의 양자화를 지원합니다; 컨텍스트 길이는 긴 입력 장면 설계에 맞춰져 있습니다.
3. 설치
- 저장소를 복제하고 스크립트에 따라 환경을 생성한다(저장소는 예시 재현에 적합한 원클릭 환경 스크립트를 제공함).
- 무게 다운로드: Hugging Face나 ModelScope에서 해당 크기(2B/8B)의 임베딩 및 리랭커를 가져올 수 있습니다.
- 의존성 실행 준비: 일반적인 의존성으로는 Transformers, PyTorch, 멀티모달 전처리와 관련된 툴킷이 있습니다; 버전은 저장소/모델 카드를 기반으로 합니다.
4. 일반적인 사용 사례
- 그래픽 및 텍스트 검색: 텍스트를 사용해 사진을 찾고, 그림을 사용해 텍스트를 찾으세요(전자상거래, 미디어 자료 라이브러리, 지식 기반).
- 비디오 검색/비디오-텍스트 매칭: 자연어로 비디오 클립이나 후보 비디오를 검색합니다.
- 멀티모달 RAG: 그래픽 페이지, 스크린샷, 차트 및 기타 콘텐츠를 벡터화한 후, Reranker를 사용해 답변 기반의 품질을 향상시킵니다.
- 시각적 Q&A 및 콘텐츠 클러스터링: 유사한 콘텐츠 집계, 중복 제거 및 주제 그룹화를 위해 통합 벡터 공간을 사용합니다.
- 다국어 시각 검색: 다국어 쿼리 및 교차 모달 콘텐츠 정렬(국제 사이트, 국경 간 비즈니스).
5. 생태와 경쟁 제품
- 생태계: 모델은 GitHub, Hugging Face, ModelScope에서 다운로드 및 예제를 제공하여 기존 벡터 라이브러리/검색 프레임워크에 접근하기 쉽게 합니다. 관계자는 또한 향후 클라우드 API 배포 기능이 제공될 것이라고 언급했습니다.
- 경쟁 제품: 멀티모달 벡터 검색의 일반적인 경로로는 CLIP/SigLIP/OpenCLIP과 같은 '그래픽-텍스트 비교 학습' 벡터 모델과 다양한 멀티모달/크로스 인코더 미세 배열 모델이 있습니다. Qwen3-VL-Embedding + Reranker의 차이는 상동 멀티모달 기반, 2단계 협업, 지시화 및 구성 가능성 차원이 가져오는 공학적 유연성에 있습니다.
6. 제한 및 주의사항
- 2단계 링크는 더 복잡합니다: 벡터 라이브러리의 유지보수와 미세 조정 서비스가 필요하며, 시스템 설계 및 모니터링 비용이 더 높습니다.
- 비디오 및 긴 컨텍스트 비용: 비디오 디코딩/프레임 추출과 긴 시퀀스 추론은 연산 능력과 지연 시간을 크게 증가시킵니다.
- 지시 및 데이터 민감도: 서로 다른 비즈니스 말뭉치, 언어, 모달 분포가 영향을 미치므로, 소규모 주석 평가와 프롬프트 반복을 권장합니다.
- 정량화 검증: 정량화는 정확도 변동을 초래할 수 있으며, 주요 지표에 대해 회귀 검사를 수행해야 합니다.
7. 프로젝트 주소
https://github.com/QwenLM/Qwen3-VL-Embedding
8. 자주 묻는 질문
Q: Qwen3-VL-Embedding은 다중 모달 검색 회상에 어떻게 사용되나요?
A: 먼저, "이미지/텍스트/비디오 콘텐츠(또는 그 표현)"를 벡터 저장소로 인코딩하세요; 쿼리 측은 또한 유사성 검색을 위해 후보 집합을 얻기 위해 벡터로 인코딩합니다.
Q: Qwen3-VL-Reranker는 검색 과정에서 어떤 문제를 해결하나요?
A: "벡터 회상 불일치, 모달리티 간 약한 정렬"과 같은 문제를 완화하고 top-K 정확도를 향상시키기 위해 미세한 상관관계를 가진 후보자를 채점합니다.
Q: 구성 가능한 임베딩 차원이 비용에 미치는 영향은 무엇인가요?
A: 차원이 작을수록 저장 및 벡터 검색 속도가 더 유리합니다. 하지만 일부 표현 능력이 손실될 수 있으므로 비즈니스 지표를 신중히 평가할 필요가 있습니다.
Q: 다국어 검색에서 지침은 어떻게 작성해야 하나요?
A: 작업에 대해 명확한 지침을 맞춤화하는 것이 종종 권장됩니다; 만약 언어 간 시나리오가 복잡하다면, 영어 지시를 우선시하고 목표 말뭉치에 미치는 영향을 평가할 수 있습니다.
Q: 멀티모달 RAG가 먼저 스크린샷이나 이미지를 OCR해야 하나요?
A: 반드시 그런 것은 아닙니다; 모델과 프로세스가 이미지/스크린샷의 직접 처리를 지원한다면, 멀티모달 인코딩과 미세 배열을 직접 수행할 수 있습니다. 하지만 "검색 가능한 단편화와 해석 가능한 인용"과 같은 요구사항이 더 강할 때는 OCR/레이아웃 파싱이 여전히 제어 가능성을 향상시킬 수 있습니다.